
ACL首届博士论文奖公布,华人学者李曼玲获荣誉提名
ACL首届博士论文奖公布,华人学者李曼玲获荣誉提名昨晚,自然语言处理顶会 ACL 公布了今年的一个特别奖项 —— 计算语言学博士论文奖。
来自主题: AI资讯
8099 点击 2025-07-30 11:34
 搜索
搜索
昨晚,自然语言处理顶会 ACL 公布了今年的一个特别奖项 —— 计算语言学博士论文奖。

AI Coding太火,微软也坐不住了。 GitHub放大招,新工具GitHub Spark只需自然语言,就能把你的想法变成APP。

使用Google Gemini CLI构建个人知识库是高效的知识管理新方式。该工具通过命令行实现自然语言交互,能自动化整理文件、转换格式、生成结构化内容(如知识图谱)。相比云端笔记软件,其本地优先特性保障隐私且支持多模态处理,结合高质量输入可实现个性化自适应学习,本质是人与AI协同进化的工作范式升级。
OpenAI通用推理模型在国际奥数竞赛中达到金牌水平,解出5题得分35/42。模型通过新技术实现长时间复杂推理和自然语言证明,非专用系统。标志AI在创造性思考和科学研究的重大突破,为解决千年难题铺路。GPT-5即将发布但暂缺此能力。
2025 年 7 月 15 日,韩国游戏创企 Planetarium Labs 宣布,公司旗下 AI 游戏创作分享平台 Verse 8 已正式在 Web 端上线。根据 Planetarium Labs 介绍,在 AI 游戏开发助手 Agent 8 的辅助下,用户可以在 Verse 8 上利用自然语言开发、发行以及分享游戏,不需要下载和安装任何软件/资源。
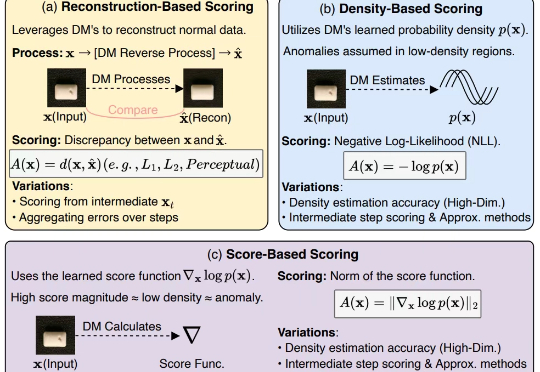
扩散模型(Diffusion Models, DMs)近年来展现出巨大的潜力,在计算机视觉和自然语言处理等诸多任务中取得了显著进展,而异常检测(Anomaly Detection, AD)作为人工智能领域的关键研究任务,在工业制造、金融风控、医疗诊断等众多实际场景中发挥着重要作用。

该大模型由海洋精准感知技术全国重点实验室(浙江大学)牵头研发,具备基础的海洋专业知识问答,以及声呐图像、海洋观测图等海洋特色多模态数据的自然语言解读能力。其采用的领域知识增强“慢思考”推理机制,相较现有通用大模型能有效降低幻觉式错误。

这两天 Andrej Karpathy 的最新演讲在 AI 社区引发了热烈讨论,他提出了「软件 3.0」的概念,自然语言正在成为新的编程接口,而 AI 模型负责执行具体任务。
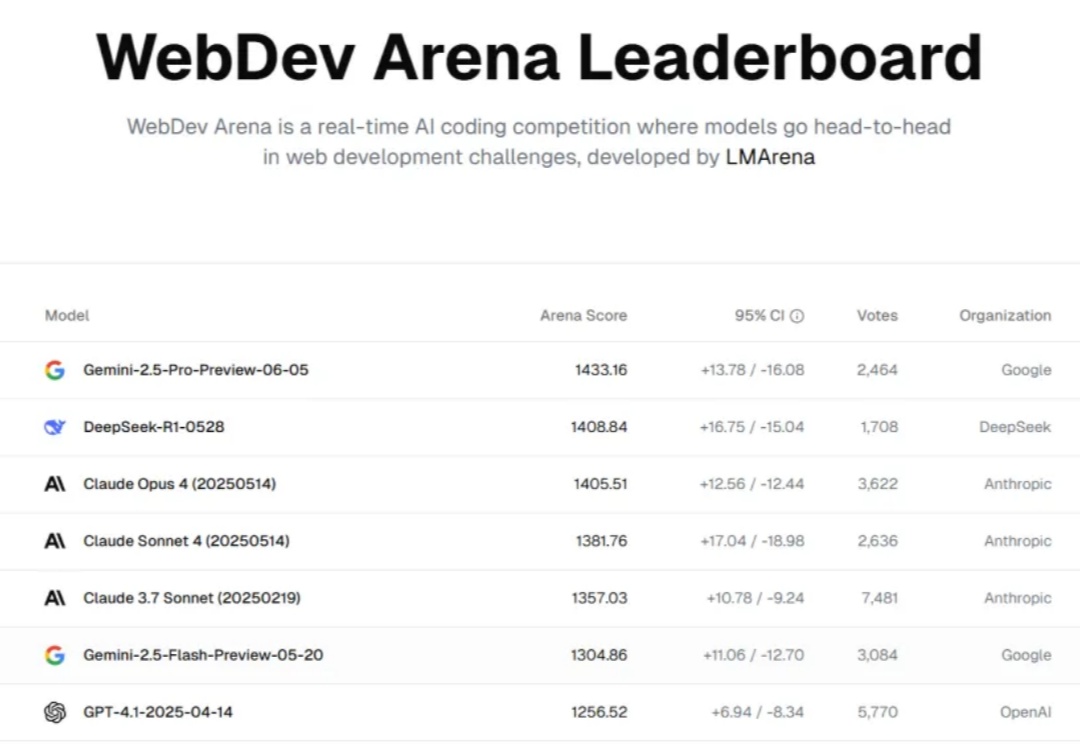
人类从农耕时代到工业时代花了数千年,从工业时代到信息时代又花了两百多年,而 LLM 仅出现不到十年,就已将曾经遥不可及的人工智能能力普及给大众,让全球数亿人能够通过自然语言进行创作、编程和推理。
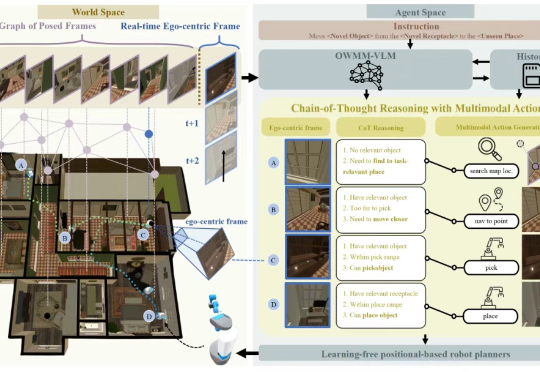
在家庭服务机器人领域,如何让机器人理解开放环境中的自然语言指令、动态规划行动路径并精准执行操作,一直是学界和工业界的核心挑战。