AI写完85%的代码!字节研发负责人和TRAE合作的首个项目官宣开源
AI写完85%的代码!字节研发负责人和TRAE合作的首个项目官宣开源短短3天时间,字节技术副总裁就借助AI原生IDE——TRAE,打造并开源了一款英语学习应用「积流成江」。其中,约85%代码都是通过自然语言生成的。
来自主题: AI资讯
10817 点击 2025-06-20 16:41
 搜索
搜索
短短3天时间,字节技术副总裁就借助AI原生IDE——TRAE,打造并开源了一款英语学习应用「积流成江」。其中,约85%代码都是通过自然语言生成的。

GRIT能让多模态大语言模型(MLLM)通过生成自然语言和图像框坐标结合的推理链进行「图像思维」,仅需20个训练样本即可实现优越性能!

「编程的未来是Human语言」,AI掀起编程70年来最大变革,从对话到代码,「氛围编程」与自然语言成为主角。老黄预言,AI让人人都能成为人机交互的桥梁。

「市象」获悉,段楠已在其GitHub主页悄然更新履历:现任京东探索研究院视觉与多模态实验室负责人,带领研究团队研发视觉和多模态基础模型。此前,他曾任阶跃星辰Technical Fellow(2024-2025)和微软亚洲研究院自然语言计算团队资深首席研究员和研究经理(2012-2024)。

豆包的一句话P图功能,又进化了!各种高考祝福、网络梗图、大片级精修、设计师草稿,无不是信手拈来。此刻,AI P图再次迎来降维打击,只要用自然语言,就能实现精准的图片编辑。可以说,AI修图终于来到了3.0时代!

在生成式 AI 重塑搜索形态的当下,Perplexity 正以“答案”为核心,重构信息入口。它不是聊天机器人,也不是传统搜索引擎,而是一种 “认知界面”——通过自然语言对话,为用户提供可验证、可引用的真实答案 。
IBM 于 6 月 2 日宣布已收购 Seek AI,这是一个允许用户使用自然语言查询企业数据的 AI 平台,具体收购金额未披露。
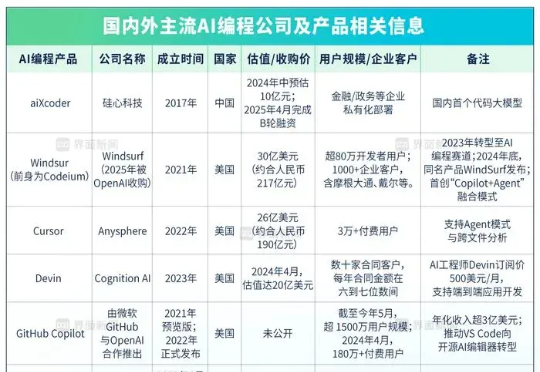
AI编程工具正引发技术革命,Cursor等产品通过自然语言交互颠覆传统编程模式,显著提升开发效率。全球创业公司竞逐AI Coding赛道,但技术成熟度、商业化路径仍面临挑战。中国企业在安全定制、垂直领域探索机会,行业期待通过代码平权重构开发生态,推动AGI实现进程。

上周,有媒体曝出了美团的 AI 零代码工具 NoCode,这是一款无需编程背景和经验,仅通过自然语言和对话形式即可快速生成应用的工具。 顾名思义,NoCode 可帮助很多人以「零代码」的方式创建个人提效工具、产品原型、可交互页面等。它不仅能生成代码,还可以进行实时预览,局部修改并一键部署,大幅降低了开发的门槛,可以帮助更多人释放创意。
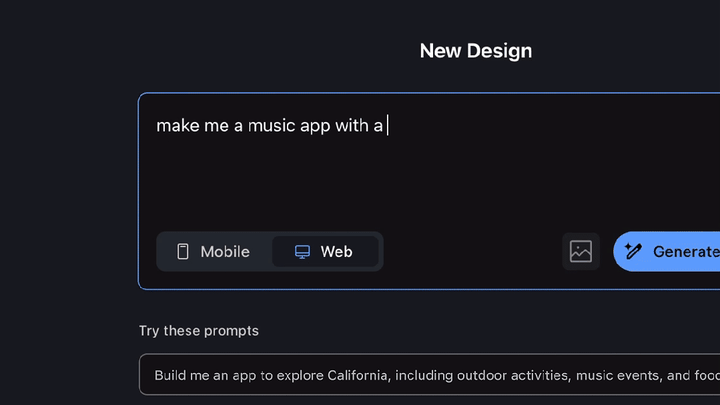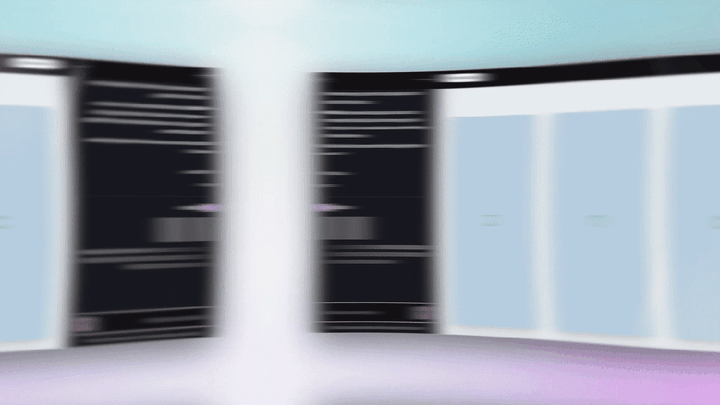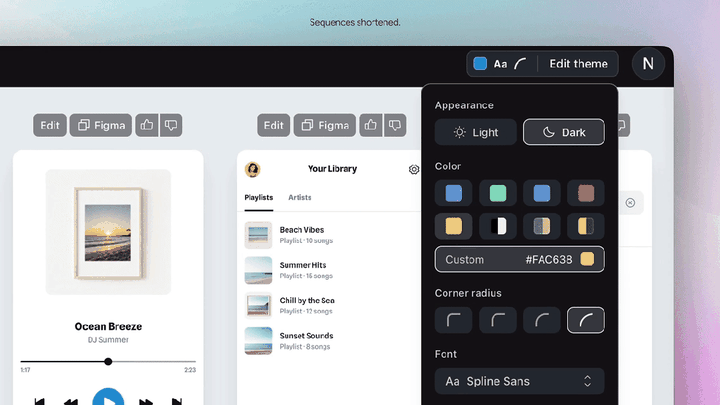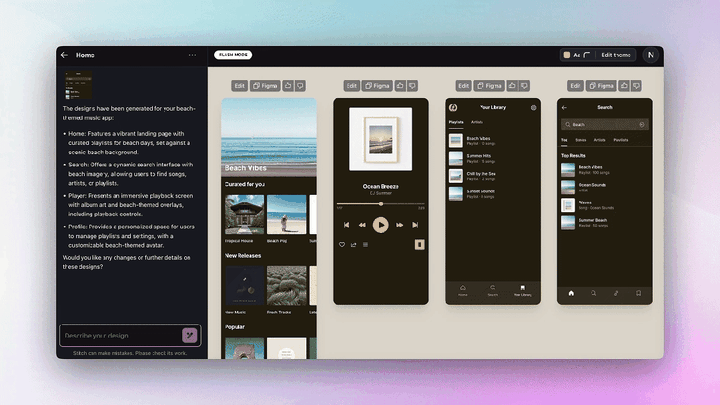
简单来说,Google Stitch 是一款由 AI 驱动的 UI 设计工具,能根据你的自然语言描述,自动生成高质量的网页和移动端界面。不止如此,它还支持直接导出 HTML/CSS 代码,甚至可以一键粘贴进 Figma,实现从原型到上线的无缝衔接。