
推理模型其实无需「思考」?伯克利发现有时跳过思考过程会更快、更准确
推理模型其实无需「思考」?伯克利发现有时跳过思考过程会更快、更准确当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。
来自主题: AI技术研报
9260 点击 2025-04-19 14:39
 搜索
搜索
当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。

2024年11月,艾伦人工智能研究所(Ai2)推出了Tülu 3 8B和70B,在性能上超越了同等参数的Llama 3.1 Instruct版本,并在长达82页的论文中公布其训练细节,训练数据、代码、测试基准一应俱全。

在这个对谈中,Lex Fridman 与半导体分析专家 Dylan Patel(SemiAnalysis 创始人)和人工智能研究科学家 Nathan Lambert(艾伦人工智能研究所)展开对话,深入探讨 DeepSeek AI 及其开源模型 V3 和 R1,以及由此引发的 AI 发展地缘政治竞争,特别是中美在 AI 芯片和技术出口管制领域的博弈。
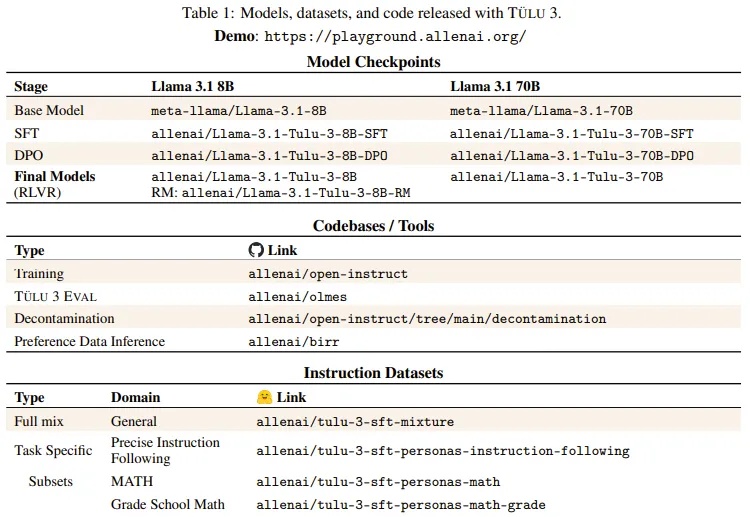
开源模型阵营又迎来一员猛将:Tülu 3。它来自艾伦人工智能研究所(Ai2),目前包含 8B 和 70B 两个版本(未来还会有 405B 版本),并且其性能超过了 Llama 3.1 Instruct 的相应版本!长达 73 的技术报告详细介绍了后训练的细节。

艾伦人工智能研究所等5机构最近公布了史上最全的开源模型「OLMo」,公开了模型的模型权重、完整训练代码、数据集和训练过程,为以后开源社区的工作设立了新的标杆。

近日,艾伦人工智能研究所发布了Unified-IO 2,——第一代Unified-IO曾预测了GPT-4等模型的能力,所以我们可以从新一代的模型中一窥GPT-5的真面目
语言模型究竟是如何感知时间的?如何利用语言模型对时间的感知来更好地控制输出甚至了解我们的大脑?最近,来自华盛顿大学和艾伦人工智能研究所的一项研究提供了一些见解。

大模型的效果好不好,有时候对齐调优很关键。但近来很多研究开始探索无微调的方法,艾伦人工智能研究所和华盛顿大学的研究者用「免调优」对齐新方法超越了使用监督调优(SFT)和人类反馈强化学习(RLHF)的 LLM 性能。