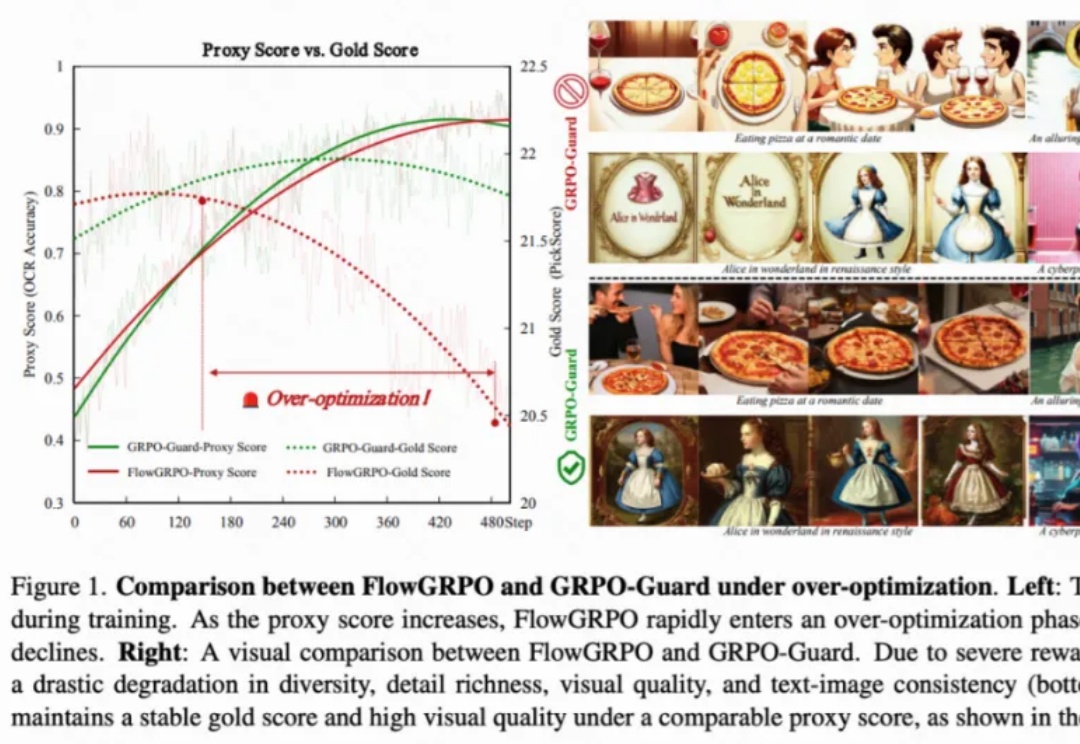
GRPO训练不再「自嗨」!快手可灵 x 中山大学推出「GRPO卫兵」,显著缓解视觉生成过优化
GRPO训练不再「自嗨」!快手可灵 x 中山大学推出「GRPO卫兵」,显著缓解视觉生成过优化目前,GRPO 在图像和视频生成的流模型中取得了显著提升(如 FlowGRPO 和 DanceGRPO),已被证明在后训练阶段能够有效提升视觉生成式流模型的人类偏好对齐、文本渲染与指令遵循能力。
来自主题: AI技术研报
9258 点击 2025-11-13 14:52
 搜索
搜索
目前,GRPO 在图像和视频生成的流模型中取得了显著提升(如 FlowGRPO 和 DanceGRPO),已被证明在后训练阶段能够有效提升视觉生成式流模型的人类偏好对齐、文本渲染与指令遵循能力。

华中科技大学团队推出首个水下多模态大模型NAUTILUS,支持8种水下场景理解任务,并开源145万图文对的NautData数据集。模型通过视觉特征增强模块解决水下图像模糊和颜色失真问题,性能超越现有模型,恶劣环境下表现更佳。
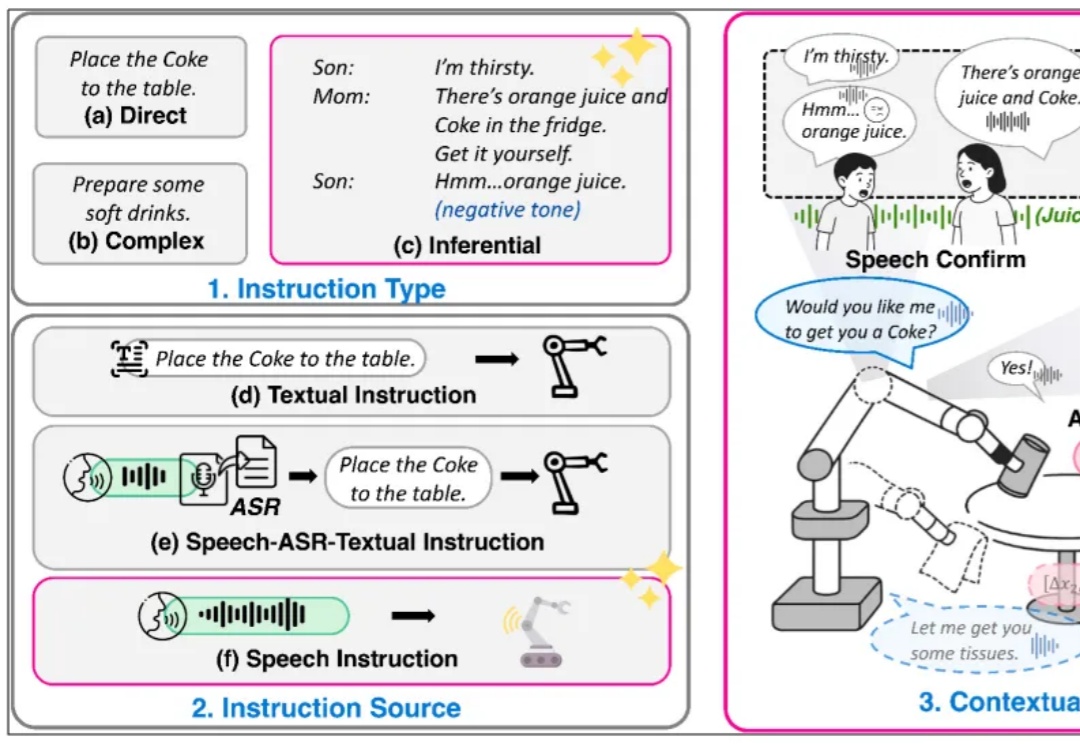
复旦⼤学、上海创智学院与新加坡国立⼤学联合推出全模态端到端操作⼤模型 RoboOmni,统⼀视觉、⽂本、听觉与动作模态,实现动作⽣成与语⾳交互的协同控制。开源 140K 条语⾳ - 视觉 - ⽂字「情境指令」真机操作数据,引领机器⼈从「被动执⾏⼈类指令」迈向「主动提供服务」新时代。

在一场矿难救援中,时间意味着生命。想象一台搜救机器人在部分坍塌的矿井中穿行:浓烟、碎石、扭曲的金属梁。它必须在险象环生的环境中迅速绘制地图,识别路径,并精准定位自己的位置。
OmniVinci是英伟达推出的全模态大模型,能精准解析视频和音频,尤其擅长视觉和听觉信号的时序对齐。它以90亿参数规模,性能超越同级别甚至更高级别模型,训练数据效率是对手的6倍,大幅降低成本。在视频内容理解、语音转录、机器人导航等场景中,OmniVinci能提供高效支持,展现出卓越的多模态应用能力。
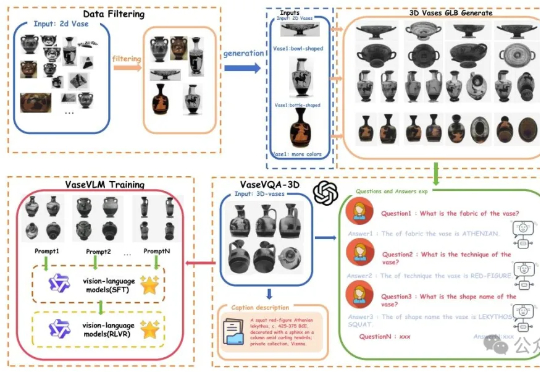
现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。

在 3D 视觉领域,如何从二维图像快速、精准地恢复三维世界,一直是计算机视觉与计算机图形学最核心的问题之一。从早期的 Structure-from-Motion (SfM) 到 Neural Radiance Fields (NeRF),再到 3D Gaussian Splatting (3DGS),技术的演进让我们离实时、通用的 3D 理解越来越近。

这年头,AI 创造的视觉世界真是炫酷至极。但真要跟细节较真儿,这些大模型的「眼力见儿」可就让人难绷了。

当前机器人领域,基础模型主要基于「视觉-语言预训练」,这样可将现有大型多模态模型的语义泛化优势迁移过来。但是,机器人的智能确实能随着算力和数据的增加而持续提升吗?我们能预测这种提升吗?
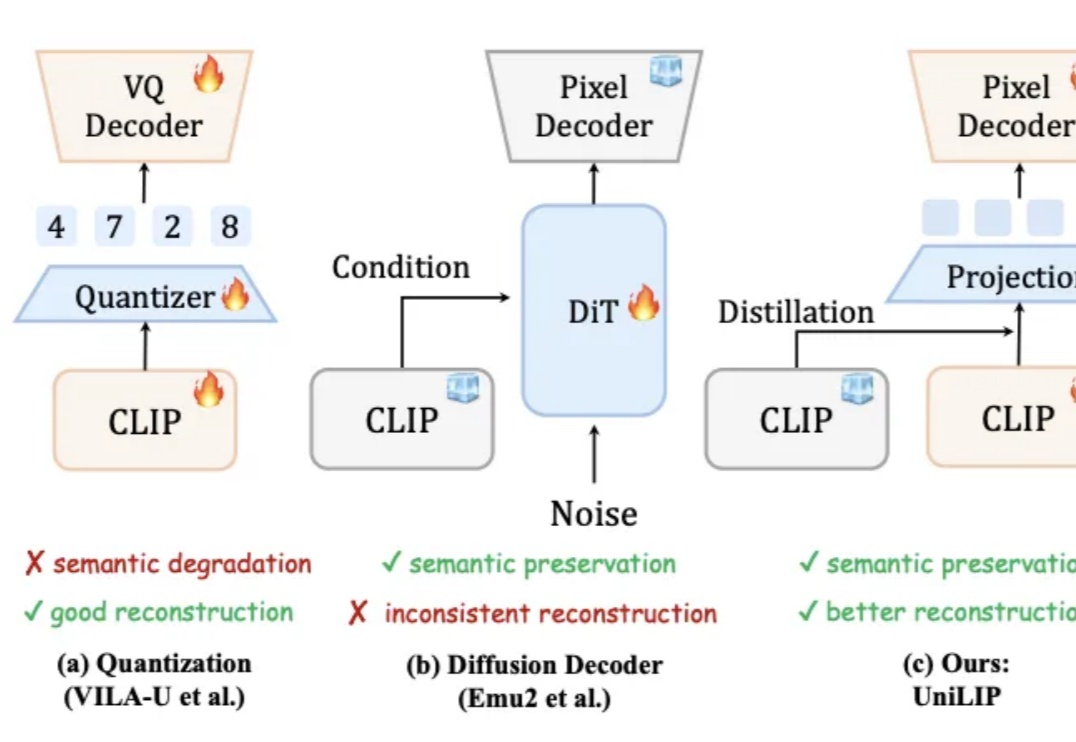
统一多模态模型要求视觉表征必须兼顾语义(理解)和细节(生成 / 编辑)。早期 VAE 因语义不足而理解受限。近期基于 CLIP 的统一编码器,面临理解与重建的权衡:直接量化 CLIP 特征会损害理解性能;而为冻结的 CLIP 训练解码器,又因特征细节缺失而无法精确重建。例如,RAE 使用冻结的 DINOv2 重建,PSNR 仅 19.23。