
谁是AI之王?聊聊备受争议的AI评测与崛起的LMArena
谁是AI之王?聊聊备受争议的AI评测与崛起的LMArena当AI模型排行榜开始被各种刷分作弊之后,谁家大模型最牛这个问题就变得非常主观,直到一家线上排行榜诞生,它叫:LMArena。在文字、视觉、搜索、文生图、文生视频等不同的AI大模型细分领域,LMArena上每天都有上千场的实时对战,由普通用户来匿名投票选出哪一方的回答更好。
来自主题: AI资讯
9813 点击 2025-11-03 09:41
 搜索
搜索
当AI模型排行榜开始被各种刷分作弊之后,谁家大模型最牛这个问题就变得非常主观,直到一家线上排行榜诞生,它叫:LMArena。在文字、视觉、搜索、文生图、文生视频等不同的AI大模型细分领域,LMArena上每天都有上千场的实时对战,由普通用户来匿名投票选出哪一方的回答更好。

在NeurIPS 2025论文中,来自「南京理工大学、中南大学、南京林业大学」的研究团队提出了一个极具突破性的框架——VIST(Vision-centric Token Compression in LLM),为大语言模型的长文本高效推理提供了全新的「视觉解决方案」。值得注意的是,这一思路与近期引起广泛关注的DeepSeek-OCR的核心理念不谋而合。
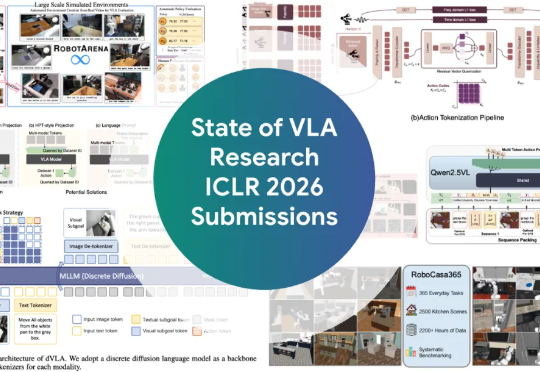
ICLR 2026爆火领域VLA(Vision-Language-Action,视觉-语言-动作)全面综述来了! 如果你还不了解VLA是什么,以及这个让机器人学者集体兴奋的领域进展如何,看这一篇就够了。
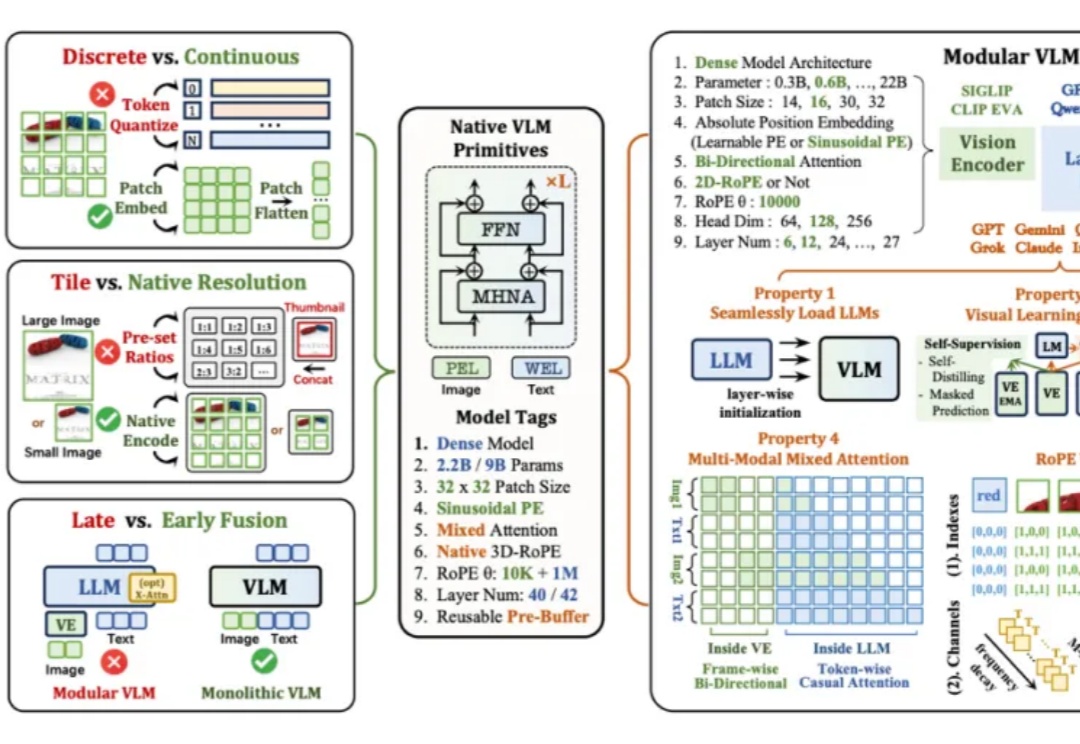
当下主流的视觉语言模型(Vision-Language Models, VLM),通常都采用这样一种设计思路:将预训练的视觉编码器与大语言模型通过投影层拼接起来。这种模块化架构成就了当前 VLM 的辉煌,但也带来了一系列新的问题——多阶段训练复杂、组件间语义对齐成本高,不同模块的扩展规律难以协调。
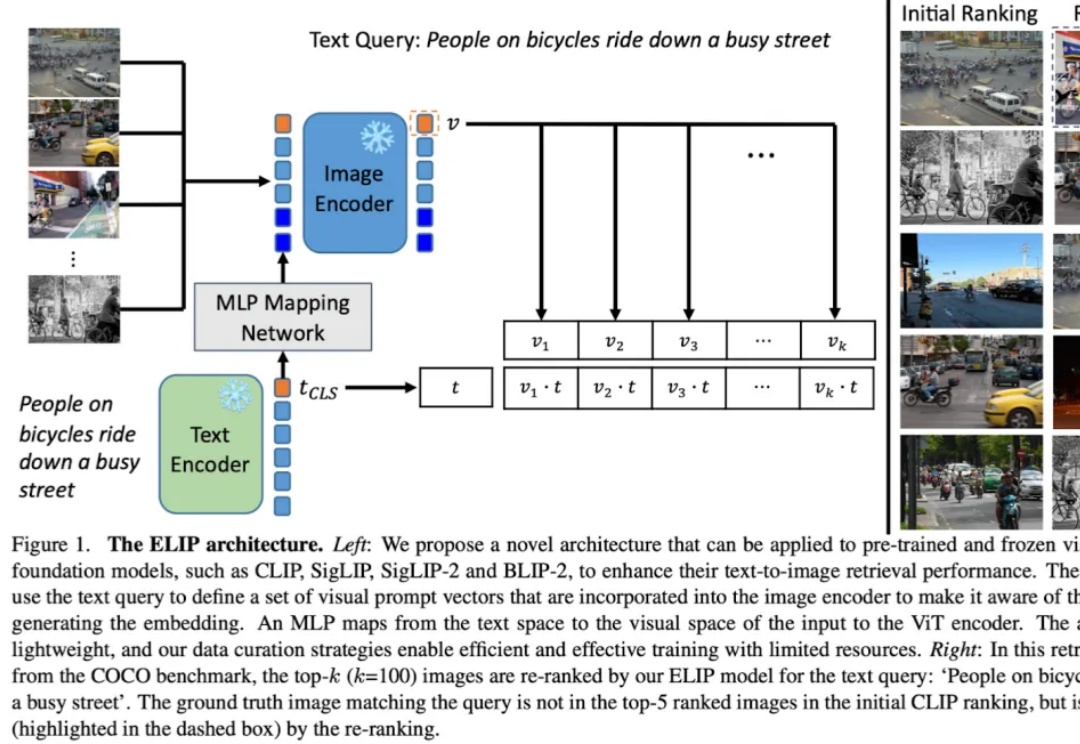
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。
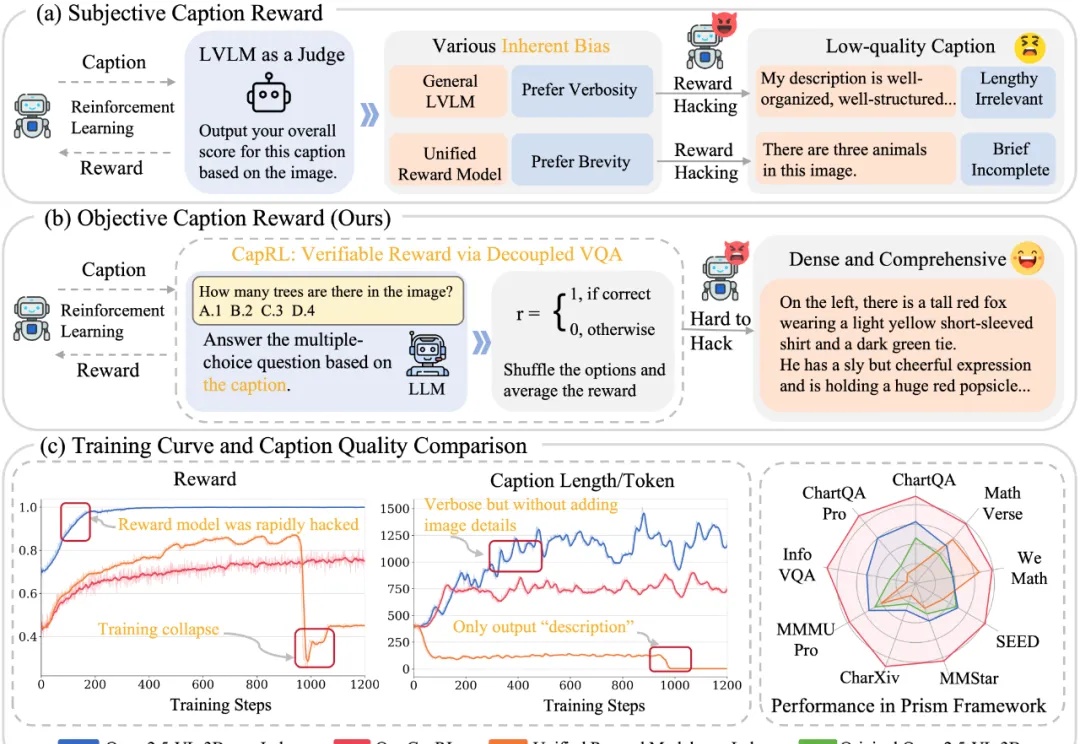
今天推荐一个 Dense Image Captioning 的最新技术 —— CapRL (Captioning Reinforcement Learning)。CapRL 首次成功将 DeepSeek-R1 的强化学习方法应用到 image captioning 这种开放视觉任务,创新的以实用性重新定义 image captioning 的 reward。
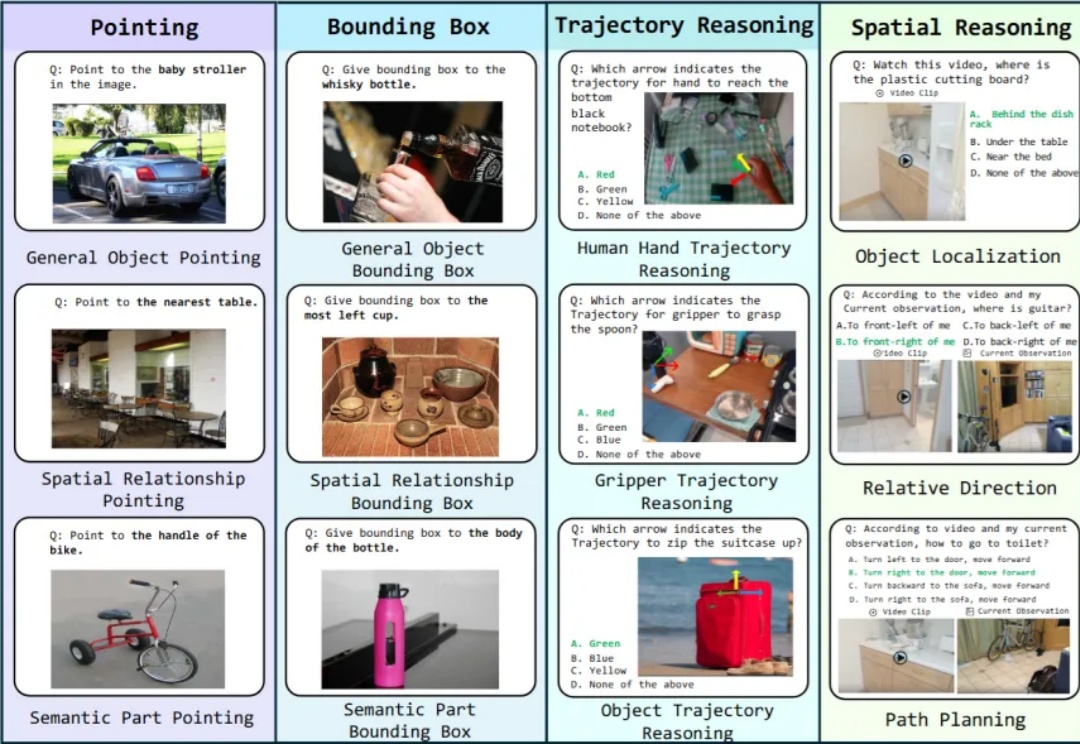
具身智能是近年来非常火概念。一个智能体(比如人)能够在环境中完成感知、理解与决策的闭环,并通过环境反馈不断进入新一轮循环,直至任务完成。这一过程往往依赖多种技能,涵盖了底层视觉对齐,空间感知,到上层决策的不同能力,这些能力便是广义上的具身智能。

当今的 AI 智能体(Agent)越来越强大,尤其是像 VLM(视觉-语言模型)这样能「看懂」世界的智能体。但研究者发现一个大问题:相比于只处理文本的 LLM 智能体,VLM 智能体在面对复杂的视觉任务时,常常表现得像一个「莽撞的执行者」,而不是一个「深思熟虑的思考者」。

在开放研究领域里,苹果似乎一整个脱胎换骨,在纯粹的研究中经常会有一些出彩的工作。这次苹果发布的研究成果的确出人意料:他们用谷歌的 Nano-banana 模型做个了视觉编辑领域的 ImageNet。

全新AI工具EditVerse将图片和视频编辑整合到一个框架中,让你像P图一样轻松P视频。通过统一的通用视觉语言和上下文学习能力,EditVerse解决了传统视频编辑复杂、数据稀缺的问题,还能实现罕见的「涌现能力」。在效果上,它甚至超越了商业工具Runway,预示着一个创作新纪元的到来。