
NextStep-1:一次在图像生成上自回归范式的探索
NextStep-1:一次在图像生成上自回归范式的探索自回归模型,是 AIGC 领域一块迷人的基石。开发者们一直在探索它在视觉生成领域的边界,从经典的离散序列生成,到结合强大扩散模型的混合范式,每一步都凝聚了社区的智慧。
来自主题: AI技术研报
8650 点击 2025-08-18 17:36
 搜索
搜索
自回归模型,是 AIGC 领域一块迷人的基石。开发者们一直在探索它在视觉生成领域的边界,从经典的离散序列生成,到结合强大扩散模型的混合范式,每一步都凝聚了社区的智慧。

作者测试了智谱GLM-4.5V(开启/关闭推理)、豆包、Kimi、元宝和ChatGPT-5在识别十张奇葩卫生间标识上的表现。评测模拟紧急如厕场景,按识别正确性评分。结果智谱普通模式得分最高(86分),ChatGPT-5和智谱推理模式次之(78分),豆包和元宝70分,Kimi垫底(38分),揭示了各AI视觉能力的差异及局限性。
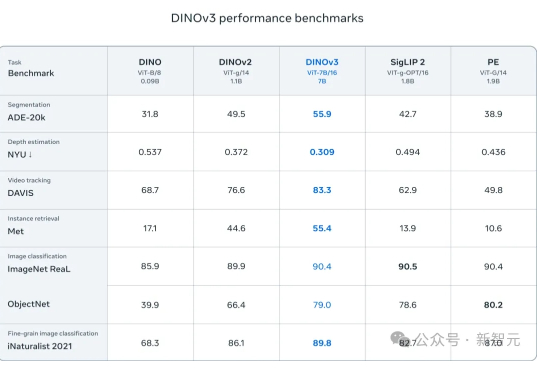
无需人工标注,吞下17亿张图片,Meta用自监督学习炼出「视觉全能王」!NASA已将它送上火星,医疗、卫星、自动驾驶领域集体沸腾。
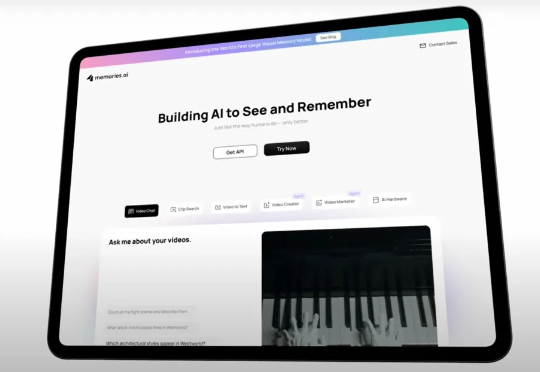
过去几年,AI 的巨大突破赋予了机器语言的力量。而下一个前沿,是给予它们关于世界的记忆。当大模型只能分析短暂的视频内容时,一个根本性的鸿沟依然存在:AI 能够处理信息,却无法真正地“记住” 信息。如今的瓶颈已不再是“看见”,而是如何保留、索引并回忆构成我们现实世界的视觉数据流。
穿着运动鞋的鲨鱼踩着滑板冲浪,头顶卡布奇诺泡沫的芭蕾舞者在水晶球里旋转——这些被称为“脑残视频”(Brainrot Videos)的荒诞内容正在TikTok和Instagram上病毒式传播,年轻用户群体疯狂追捧这些脱离现实逻辑的视觉梗图,单条播放量动辄突破千万。
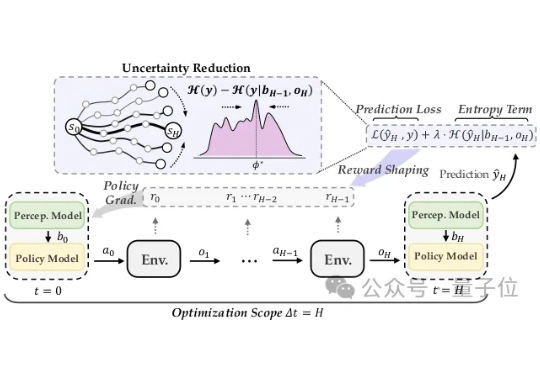
面对对抗攻击,具身智能体除了被动防范,也能主动出击! 在人类视觉系统启发下,清华朱军团队在TPMAI 2025中提出了强化学习驱动的主动防御框架REIN-EAD。
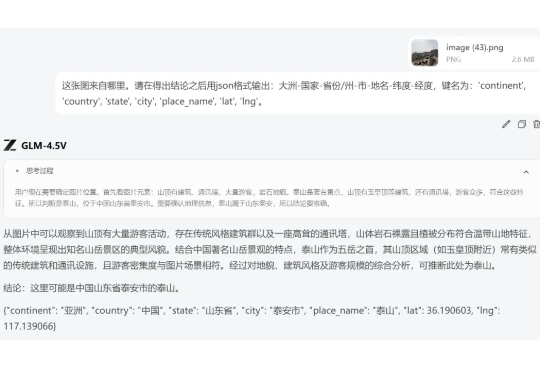
当同事出差回来扔到群里这么一张图,我们也是猜了半天,但毫无头绪。 直到另一位同事把图扔给智谱的新模型 ——GLM-4.5V,这个谜团才解开。

智谱基于GLM-4.5打造的开源多模态视觉推理模型GLM-4.5V,在42个公开榜单中41项夺得SOTA!其功能涵盖图像、视频、文档理解、Grounding、地图定位、空间关系推理、UI转Code等。
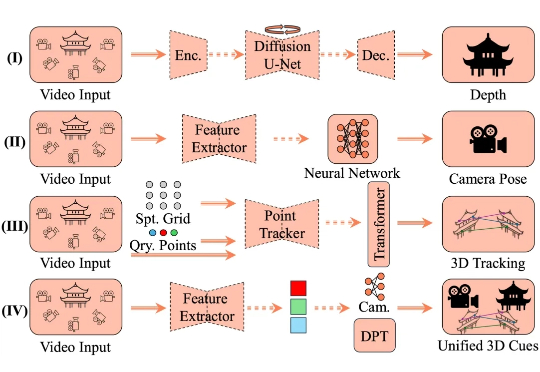
4D 空间智能重建是计算机视觉领域的核心挑战,其目标在于从视觉数据中还原三维空间的动态演化过程。这一技术通过整合静态场景结构与时空动态变化,构建出具有时间维度的空间表征系统,在虚拟现实、数字孪生和智能交互等领域展现出关键价值。

擅长「种草」的小红书正加大技术自研力度,两个月内接连开源三款模型!最新开源的首个多模态大模型dots.vlm1,基于自研视觉编码器构建,实测看穿色盲图,破解数独,解高考数学题,一句话写李白诗风,视觉理解和推理能力都逼近Gemini 2.5 Pro闭源模型。