
JinaVDR: 一个图文混排文档搜索任务的基准集
JinaVDR: 一个图文混排文档搜索任务的基准集大部分现有的文档检索基准(如MTEB)只考虑了纯文本。而一旦文档的关键信息蕴含在图表、截图、扫描件和手写标记中,这些基准就无能为力。为了更好的开发下一代向量模型和重排器,我们首先需要一个能评测模型在视觉复杂文档能力的基准集。
来自主题: AI技术研报
11510 点击 2025-08-07 14:43
 搜索
搜索
大部分现有的文档检索基准(如MTEB)只考虑了纯文本。而一旦文档的关键信息蕴含在图表、截图、扫描件和手写标记中,这些基准就无能为力。为了更好的开发下一代向量模型和重排器,我们首先需要一个能评测模型在视觉复杂文档能力的基准集。

上周我写过一篇AI产品自用分享,当时我说,AI知识问答方面,我会选择openai o3和豆包。
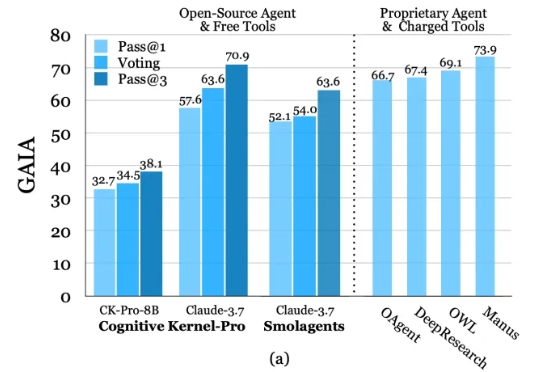
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。

老黄曾预言,每个像素都将由AI生成!刚刚,谷歌DeepMind放出的「通用世界模型」Genie 3,一句话即生720p实时模拟世界,1分钟视觉记忆一致性超高。刚刚,谷歌DeepMind祭出新一代通用世界模型——Genie 3,能模拟出史无前例的丰富交互环境。
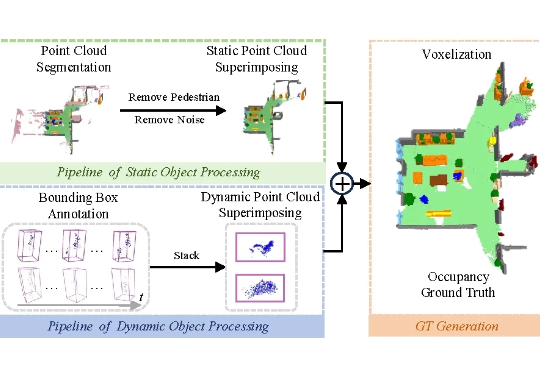
凭借类人化的结构设计与运动模式,人形机器人被公认为最具潜力融入人类环境的通用型机器人。其核心任务涵盖操作 (manipulation)、移动 (locomotion) 与导航 (navigation) 三大领域,而这些任务的高效完成,均以机器人对自身所处环境的全面精准理解为前提。

在人工智能快速发展的今天,我们已逐渐习惯于让 AI 识别图像、理解语言,甚至与之对话。但当我们进入真实三维世界,如何让 AI 具备「看懂场景」、「理解空间」和「推理复杂任务」的能力?这正是 3D 视觉语言模型(3D VLM)所要解决的问题。

尽管当前的机器人视觉语言操作模型(VLA)展现出一定的泛化能力,但其操作模式仍以准静态的抓取与放置(pick-and-place)为主。相比之下,人类在操作物体时常常采用推动、翻转等更加灵活的方式。若机器人仅掌握抓取,将难以应对现实环境中的复杂任务。

在复杂的开放环境中,让足式机器人像人类一样自主完成「先跑到椅子旁,再快速接近行人」这类长程多目标任务,一直是 robotics 领域的棘手难题。传统方法要么局限于固定目标类别,要么难以应对运动中的视觉抖动、目标丢失等实时挑战,导致机器人在真实场景中常常「迷路」或「认错对象」。

据 AI 科技评论报道,前阿里通义实验室视觉负责人薄列峰已正式加盟腾讯混元大模型团队,直接向腾讯副总裁、混元项目负责人蒋杰汇报,主要负责多模态方向的技术攻坚。早在今年4月30日,薄列峰从阿里离职,外界曾一度传出他将赴美加入某大型科技公司,统筹多模态AI研发。如今尘埃落定,他最终选择落脚深圳,加入国内多模态竞争最激烈的战场之一。

在大语言模型席卷全球的时代,坚持更接近生命本质的智能是少有人走的路。2025年7月初,一篇来自Numenta与Thousand Brains Project的论文,首次通过一个名为“Monty”的AI系统,实验性地验证了神经科学家杰夫·霍金斯(Jeff Hawkins)提出的“千脑智能理论”。