
斯坦福博士后创业,给机器人做“电子皮肤”|涌现新项目
斯坦福博士后创业,给机器人做“电子皮肤”|涌现新项目途见科技通过“电子皮肤”触觉系统,为具身智能增加视觉、听觉之外的感知。
来自主题: AI资讯
9899 点击 2025-07-18 11:23
 搜索
搜索
途见科技通过“电子皮肤”触觉系统,为具身智能增加视觉、听觉之外的感知。
近日,ICCV 2025(国际计算机视觉大会)公布论文录用结果,理想汽车共有 8 篇论文入选,其中 3 篇来自基座模型团队。

当前最强大的视觉语言模型(VLMs)虽然能“看图识物”,但在理解电影方面还不够“聪明”。
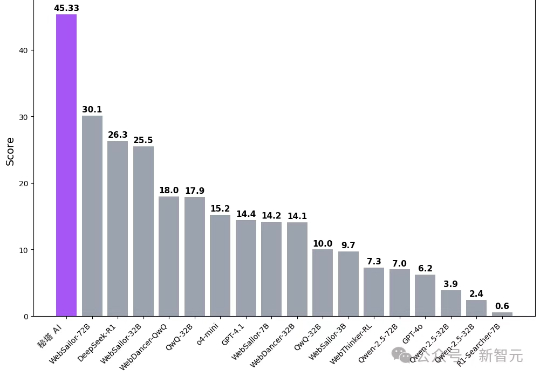
刚刚,国内首个免费可用Deep Research上线了!它在多个权威评测中拿下第一,准确率直接碾压开源WebSailor。研究过程中,它能多线迭代追搜,直至逻辑闭环。更绝的是,一键生成炫酷的互动研究报告,视觉效果直接拉满。
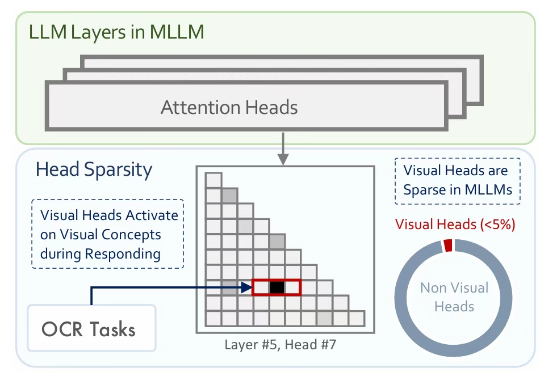
多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。
本来以为美图可能会在 8 月份推出新产品,给中期财报壮声势,但没想到,公告发布 20 天不到,这款名为 RoboNeo 的 AI Agent 就上线了,而且是直接面向所有用户免费开放。

昨天Grok4发布完以后,我随手刷了一下X。
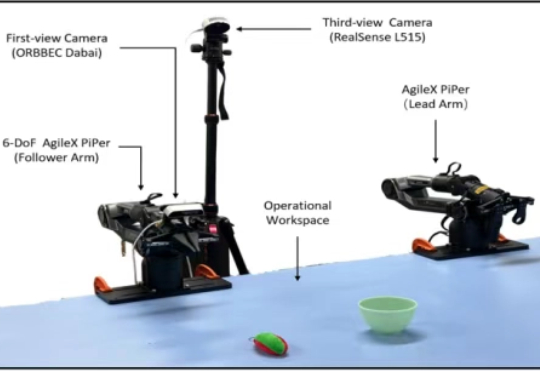
近年来,视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型因其出色的多模态理解与泛化能力,已成为机器人领域的重要研究方向。尽管相关技术取得了显著进展,但在实际部署中,尤其是在高频率和精细操作等任务中,VLA 模型仍受到推理速度瓶颈的严重制约。
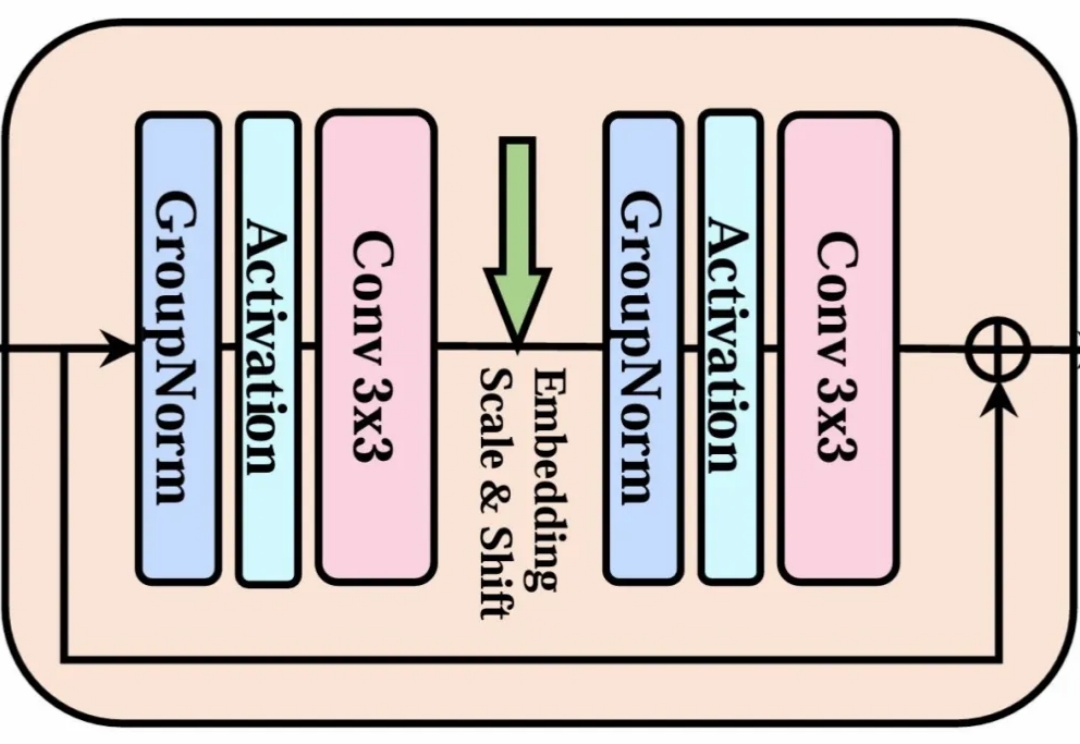
当整个 AI 视觉生成领域都在 Transformer 架构上「卷生卷死」时,一项来自北大、北邮和华为的最新研究却反其道而行之,重新审视了深度学习中最基础、最经典的模块——3x3 卷积。

在机器人操控领域,实现高频响应与复杂推理的统一,一直是一个重大技术挑战。近期,北京大学与香港中文大学的研究团队联合发布了名为 Fast-in-Slow(FiS-VLA) 的全新双系统视觉 - 语言 - 动作模型。