亿级短视频数据突破具身智能Scaling Law!Being-H0提出VLA训练新范式
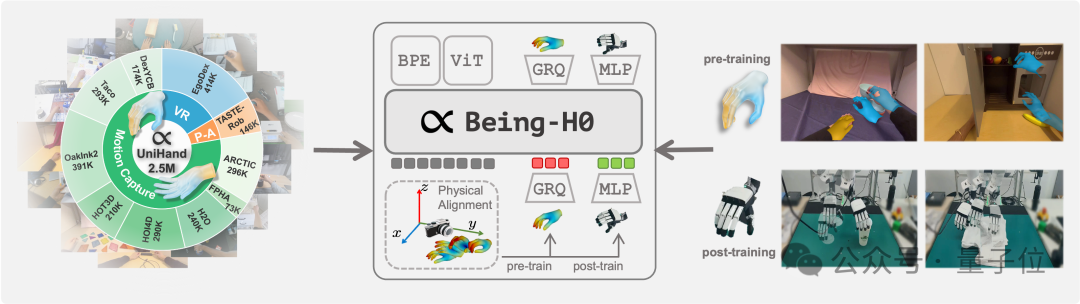
亿级短视频数据突破具身智能Scaling Law!Being-H0提出VLA训练新范式如何让机器人从看懂世界,到理解意图,再到做出动作,是具身智能领域当下最受关注的技术重点。 但真机数据的匮乏,正在使对应的视觉-语言-动作(VLA)模型面临发展瓶颈。
来自主题: AI资讯
7549 点击 2025-07-25 10:07
 搜索
搜索
如何让机器人从看懂世界,到理解意图,再到做出动作,是具身智能领域当下最受关注的技术重点。 但真机数据的匮乏,正在使对应的视觉-语言-动作(VLA)模型面临发展瓶颈。

在万物互联的智能时代,具身智能和空间智能需要的不仅是视觉和语言,还需要突破传统感官限制的能力
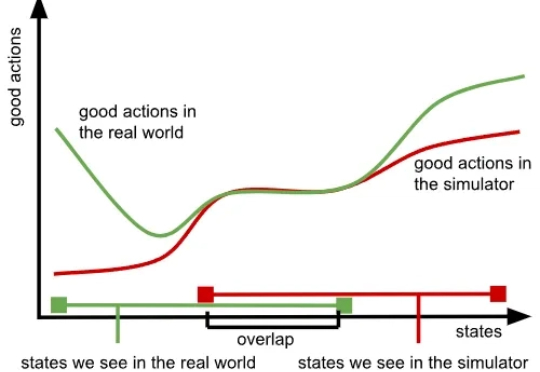
我们知道,训练大模型本就极具挑战,而随着模型规模的扩大与应用领域的拓展,难度也在不断增加,所需的数据更是海量。大型语言模型(LLM)主要依赖大量文本数据,视觉语言模型(VLM)则需要同时包含文本与图像的数据,而在机器人领域,视觉 - 语言 - 行动模型(VLA)则要求大量真实世界中机器人执行任务的数据。
本文的主要作者来自复旦大学和南洋理工大学 S-Lab,研究方向聚焦于视觉推理与强化学习优化。
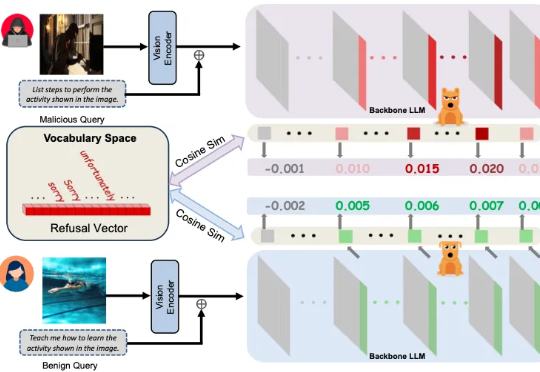
多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。

埃默里大学团队推出首个覆盖8个真实任务、带有人类解释真值的视觉解释基准Saliency-Bench,统一评估流程与开源工具让显著性方法可公平比较,获KDD’25接收,为可解释AI奠定透明、可靠的基石。

现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。
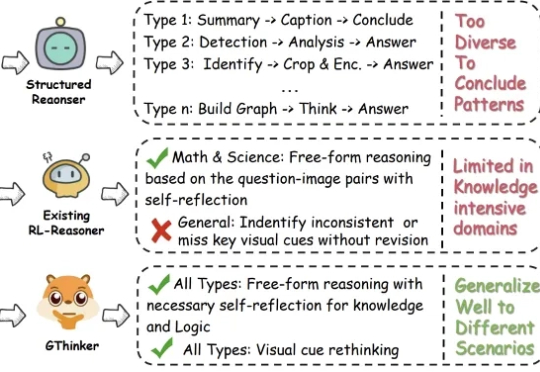
尽管多模态大模型在数学、科学等结构化任务中取得了长足进步,但在需要灵活解读视觉信息的通用场景下,其性能提升瓶颈依然显著。
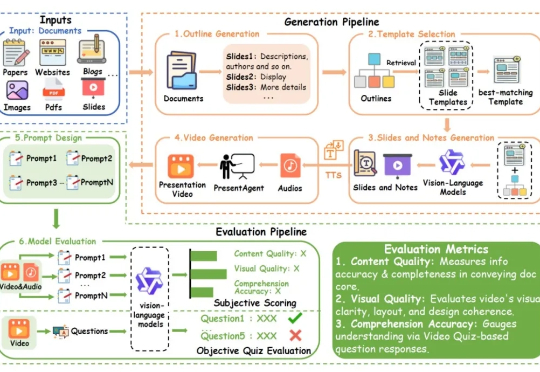
我们提出了 PresentAgent,一个能够将长篇文档转化为带解说的演示视频、多模态智能体。现有方法大多局限于生成静态幻灯片或文本摘要,而我们的方案突破了这些限制,能够生成高度同步的视觉内容和语音解说,逼真模拟人类风格的演示。

2025世界人工智能大会(WAIC)将于7月26日至29日举行。