
零开销,消除图像幻觉!基于零空间投影挖掘正常样本特征 | CVPR 2025
零开销,消除图像幻觉!基于零空间投影挖掘正常样本特征 | CVPR 2025当前大型视觉语言模型(LVLMs)存在物体幻觉问题,即会生成图像中不存在的物体描述。
来自主题: AI技术研报
10738 点击 2025-06-27 16:26
 搜索
搜索
当前大型视觉语言模型(LVLMs)存在物体幻觉问题,即会生成图像中不存在的物体描述。
![Black Forest震撼开源FLUX.1 Kontext [dev]:媲美GPT-4o的图像编辑](https://www.aitntnews.com/pictures/2025/6/27/49d75709-5310-11f0-82be-fa163e47d677.jpg)
前段时间,沉寂了很久的Flux官方团队Black Forest Labs发布了新模型:FLUX.1 Kontext,这是一套支持生成与编辑图像的流匹配(flow matching)模型。FLUX.1 Kontext不仅支持文生图,还实现了上下文图像生成功能,可以同时使用文本和图像作为提示词,并能无缝提取修改视觉元素,生成全新且协调一致的画面。
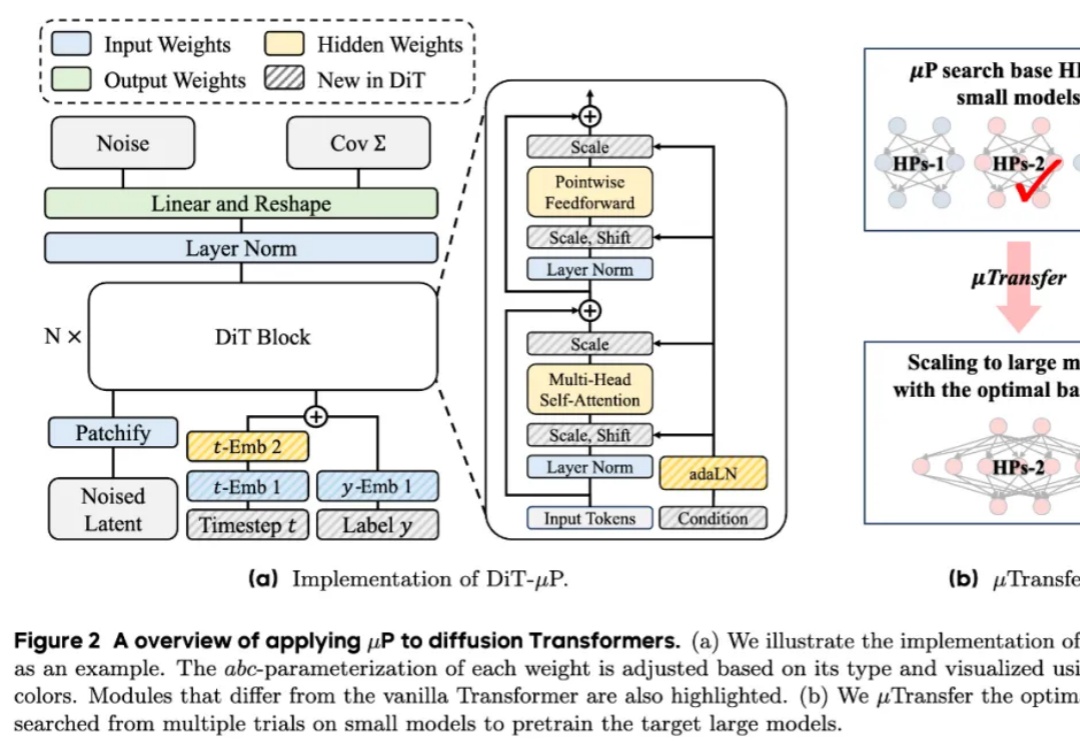
近年来,diffusion Transformers已经成为了现代视觉生成模型的主干网络。随着数据量和任务复杂度的进一步增加,diffusion Transformers的规模也在快速增长。然而在模型进一步扩大的过程中,如何调得较好的超参(如学习率)已经成为了一个巨大的问题,阻碍了大规模diffusion Transformers释放其全部的潜能。

梵高、蒙娜丽莎、维纳斯、毕加索、草间弥生……这些世界名画的主角和画家们忽然复活,穿上时装走上T台,这个AI视频,已经全网刷爆了!视觉盛宴,泪点拉满,这场穿越时空的艺术秀,让全网震撼。

不用提前熟悉环境,一声令下,就能让宇树机器人坐在椅子上、桌子上、箱子上!
你对着家里的机器人说:“去厨房,看看冰箱里还有没有牛奶。”
今天,Gemini 家族迎来了一个新成员:Gemini Robotics On-Device。这是谷歌 DeepMind 首个可以直接部署在机器人上的视觉-语言-动作(VLA)模型,可以帮助机器人更快、更高效地适应新任务和环境,同时无需持续的互联网连接。
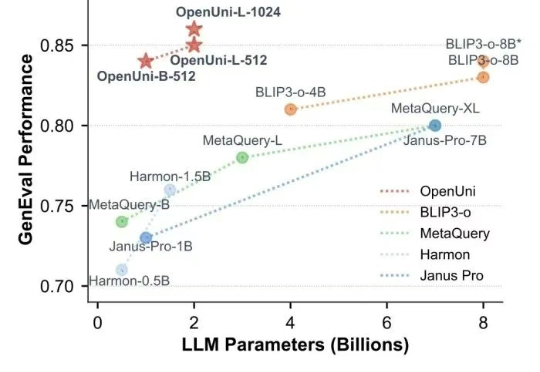
随着 GPT-4o 展现出令人印象深刻的多模态能力,将视觉理解和图像生成统一到单一模型中已成为 AI 领域的研究趋势(如MetaQuery 和 BLIP3-o )。
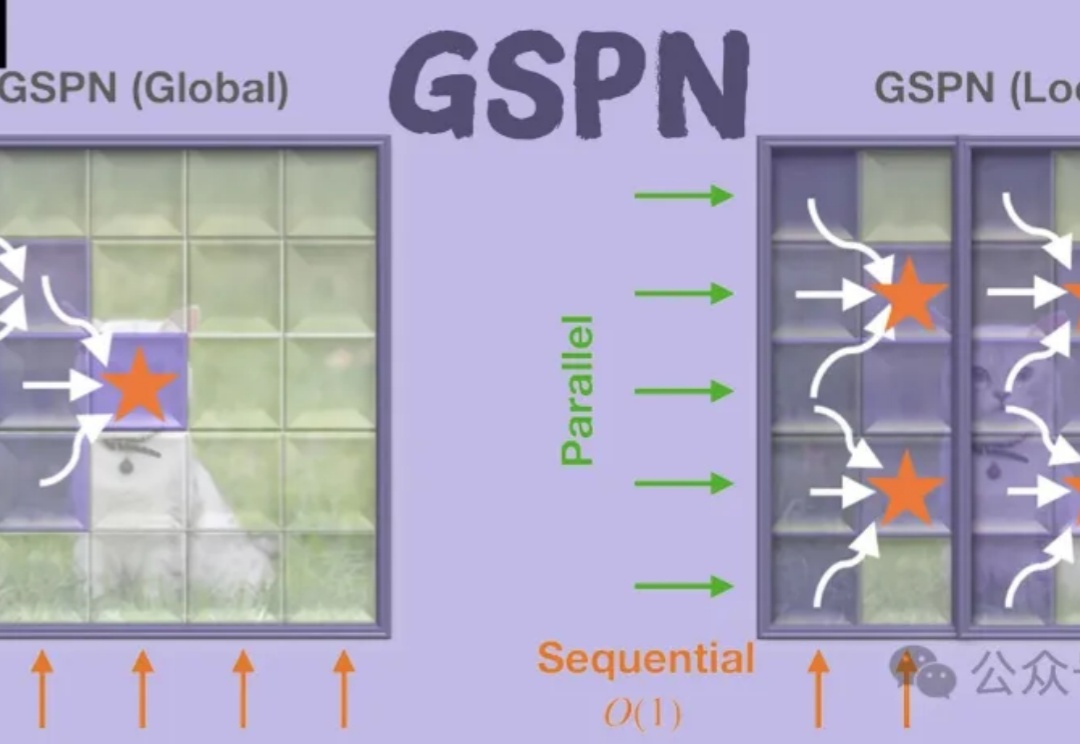
GSPN是一种新型视觉注意力机制,通过线性扫描和稳定性-上下文条件,高效处理图像空间结构,显著降低计算复杂度。通过线性扫描方法建立像素间的密集连接,并利用稳定性-上下文条件确保稳定的长距离上下文传播,将计算复杂度显著降低至√N量级。

NVIDIA等研究团队提出了一种革命性的AI训练范式——视觉游戏学习ViGaL。通过让7B参数的多模态模型玩贪吃蛇和3D旋转等街机游戏,AI不仅掌握了游戏技巧,还培养出强大的跨领域推理能力,在数学、几何等复杂任务上击败GPT-4o等顶级模型。