
Midjourney入局视频生成,图像模型V7不断更新,视觉卷王实锤了
Midjourney入局视频生成,图像模型V7不断更新,视觉卷王实锤了图像生成界的“大魔王”Midjourney也来卷视频生成了?!
来自主题: AI资讯
10693 点击 2025-06-17 10:45
 搜索
搜索
图像生成界的“大魔王”Midjourney也来卷视频生成了?!

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。

AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。

视频生成技术正以前所未有的速度革新着当前的视觉内容创作方式,从电影制作到广告设计,从虚拟现实到社交媒体,高质量且符合人类期望的视频生成模型正变得越来越重要。

「市象」获悉,段楠已在其GitHub主页悄然更新履历:现任京东探索研究院视觉与多模态实验室负责人,带领研究团队研发视觉和多模态基础模型。此前,他曾任阶跃星辰Technical Fellow(2024-2025)和微软亚洲研究院自然语言计算团队资深首席研究员和研究经理(2012-2024)。
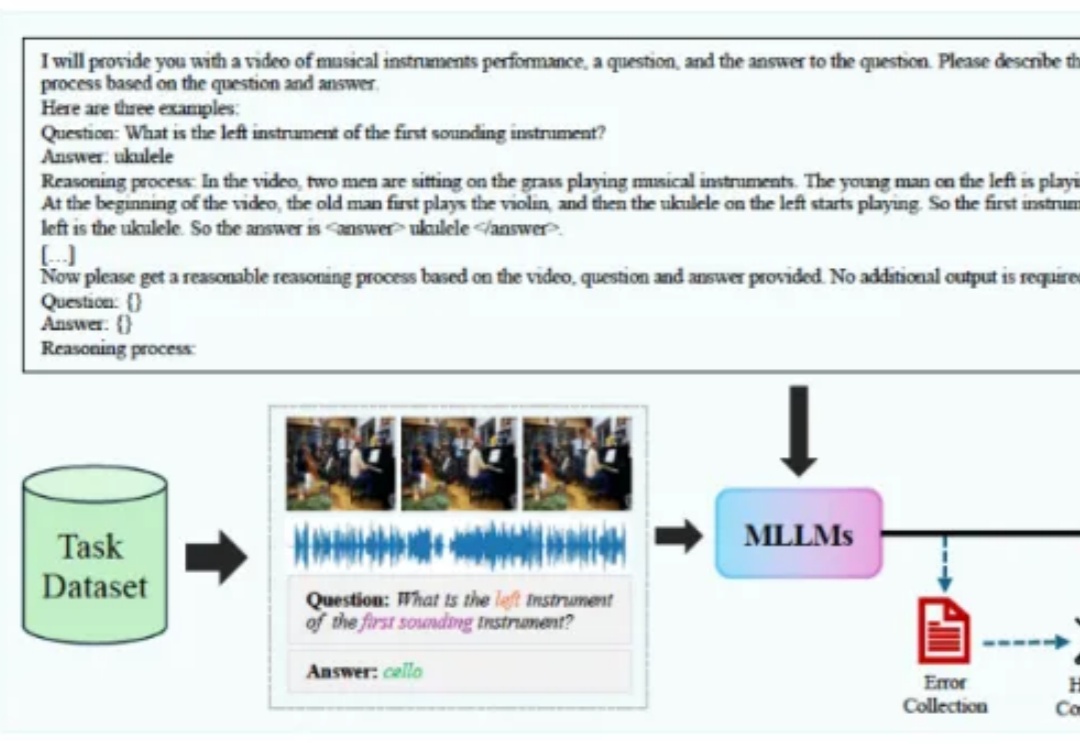
我们人类生活在一个充满视觉和音频信息的世界中,近年来已经有很多工作利用这两个模态的信息来增强模型对视听场景的理解能力,衍生出了多种不同类型的任务,它们分别要求模型具备不同层面的能力。

第一财经「新皮层」独家获悉,MiniMax即将推出文本推理模型,并将开源。半个月前,MiniMax刚刚发布和开源了视觉推理模型Orsta(One RL to See Them All)。MiniMax今年3月做出产品线调整,将旗下现有产品「海螺AI」更名为「MiniMax」,与公司同名,聚焦文本理解和生成;
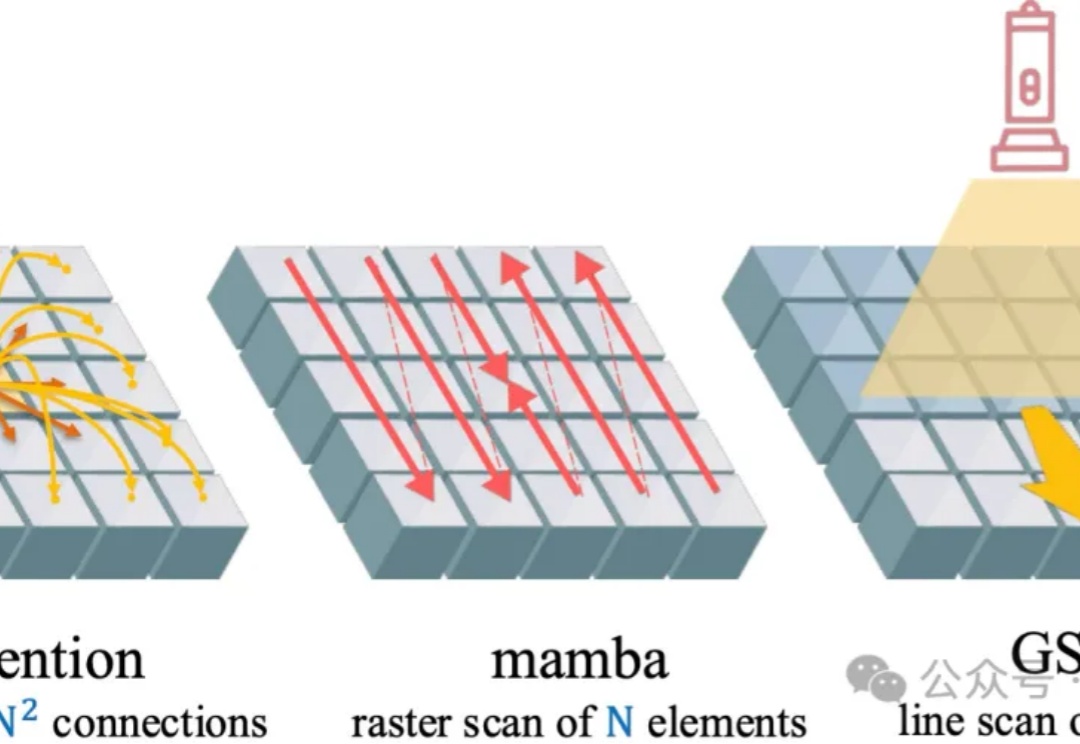
视觉注意力机制,又有新突破,来自香港大学和英伟达。

今年苹果在 AI 上宣布的诸多所谓新功能,例如实时翻译、快捷指令等,并无太多革命性;至于视觉智能 (visual intelligence),不仅功能落后 Google Lens 六七年,交互体验上也远未达到一众 Android 友商的内置 AI/Agent 产品在 2025 上半年水平。

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?