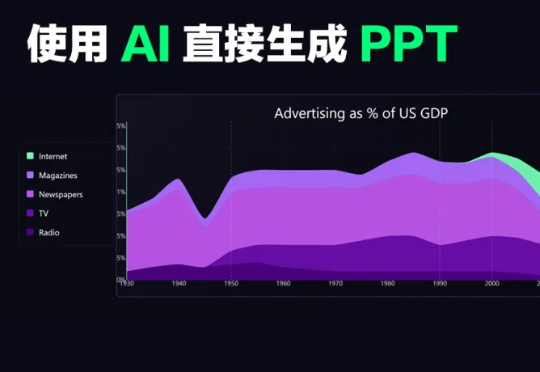
信息的AI可视化(1):AI生成动态PPT的步骤分享
信息的AI可视化(1):AI生成动态PPT的步骤分享PPT对大部分朋友的的价值不言而喻。我在日常做商业咨询时也需要大量PPT做交付,所以从年初开始,我尝试让AI来完成商业PPT的生成和设计。目前效果大致如下:视觉效果是有点超出我的预期的。而且从可读性、图形化、信息整理几个角度来说,这些结果已经完全够用了。同时这些生成的PPT可以是动态的:
来自主题: AI资讯
12144 点击 2025-03-27 10:18
 搜索
搜索
PPT对大部分朋友的的价值不言而喻。我在日常做商业咨询时也需要大量PPT做交付,所以从年初开始,我尝试让AI来完成商业PPT的生成和设计。目前效果大致如下:视觉效果是有点超出我的预期的。而且从可读性、图形化、信息整理几个角度来说,这些结果已经完全够用了。同时这些生成的PPT可以是动态的:
在基于物理世界的真实场景进行视觉问答时,有可能出现参考选项中没有最佳答案的情况,比如以下例子:

个性化图像生成是图像生成领域的一项重要技术,正以前所未有的速度吸引着广泛关注。它能够根据用户提供的独特概念,精准合成定制化的视觉内容,满足日益增长的个性化需求,并同时支持对生成结果进行细粒度的语义控制与编辑,使其能够精确实现心中的创意愿景。
就在DeepSeek-V3更新的同一夜,阿里通义千问Qwen又双叒叕一次梦幻联动了——
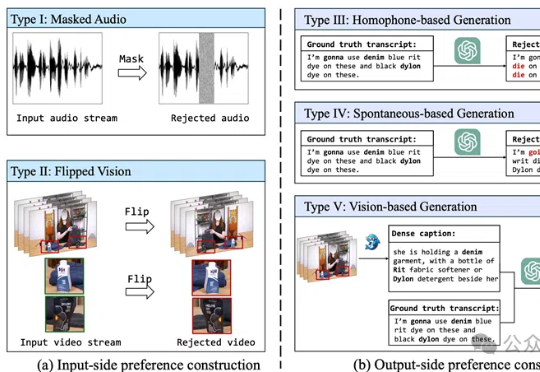
视觉+语音=更强的语音识别!BPO-AVASR通过优化音视频输入和输出偏好,提升语音识别在真实场景中的准确性,解决了传统方法在噪声、口语化和视觉信息利用不足的问题。

3D 视觉定位(3D Visual Grounding, 3DVG)是智能体理解和交互三维世界的重要任务,旨在让 AI 根据自然语言描述在 3D 场景中找到指定物体。
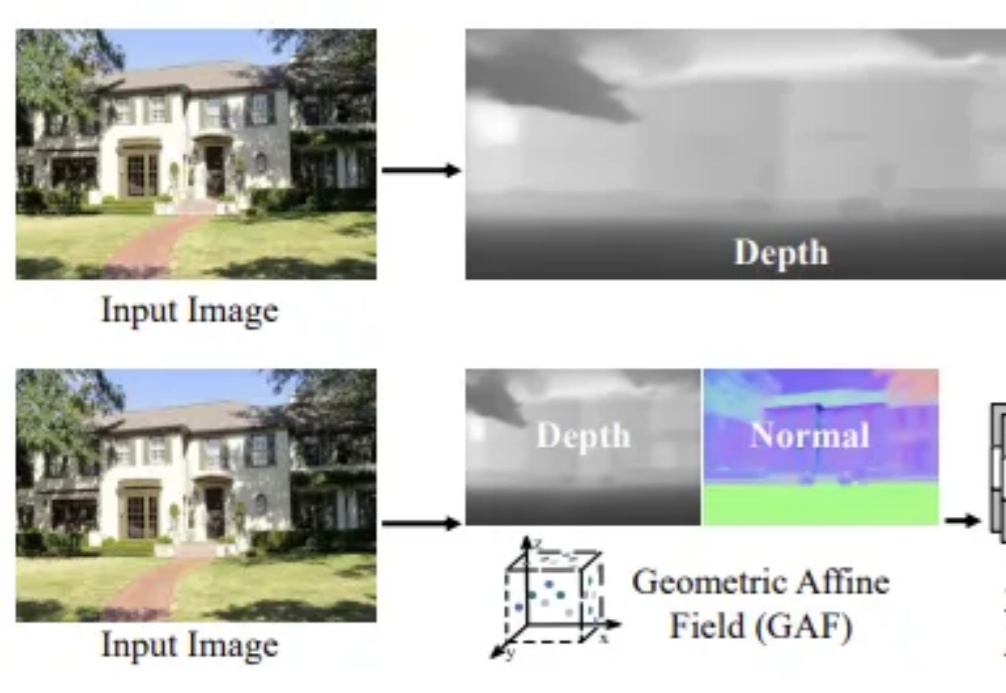
单视角三维场景重建一直是计算机视觉领域中的核心挑战之一,尤其在捕捉高保真室外场景细节时,如何确保结构一致性和几何精度显得尤为困难。

大家好,最近感觉有点AI编程搞产品上瘾了😂。这次主要想和大家分享第二个小产品 art4kid.com 过程中遇到的挑战和收获。这个产品也是通过AI编程完成的,我所做的主要就是把握方向,发现问题,让AI思考问题发生原因然后解决问题,还有提供一些视觉。

EgoNormia基准可以评估视觉语言模型在物理社会规范理解方面能力,从结果上看,当前最先进的模型在规范推理方面仍远不如人类,主要问题在于规范合理性和优先级判断上的不足。
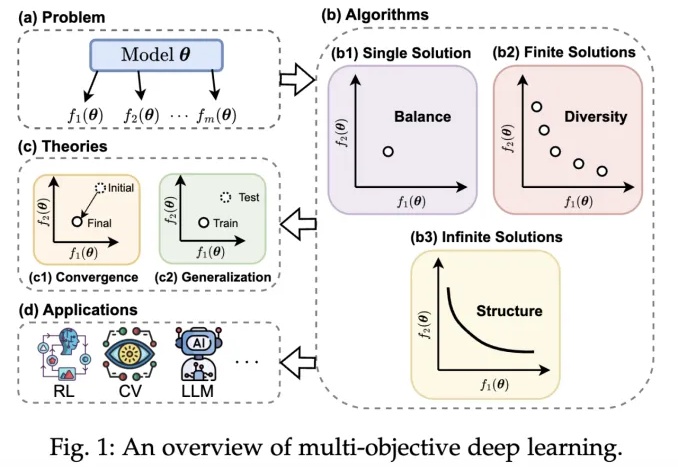
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。