完全免费可商用 Lummi AI 人工智能生成图库
完全免费可商用 Lummi AI 人工智能生成图库在今天数字图像无处不在,而高质量的图片对于各种项目至关重要。然而,许多人对于那些无聊、过度使用的传统库存照片感到厌倦,他们渴望与众不同、创新的视觉效果。这就是为什么 Lummi 库存图片的出现如此重要。
来自主题: AI资讯
10495 点击 2025-04-01 16:23
 搜索
搜索
在今天数字图像无处不在,而高质量的图片对于各种项目至关重要。然而,许多人对于那些无聊、过度使用的传统库存照片感到厌倦,他们渴望与众不同、创新的视觉效果。这就是为什么 Lummi 库存图片的出现如此重要。
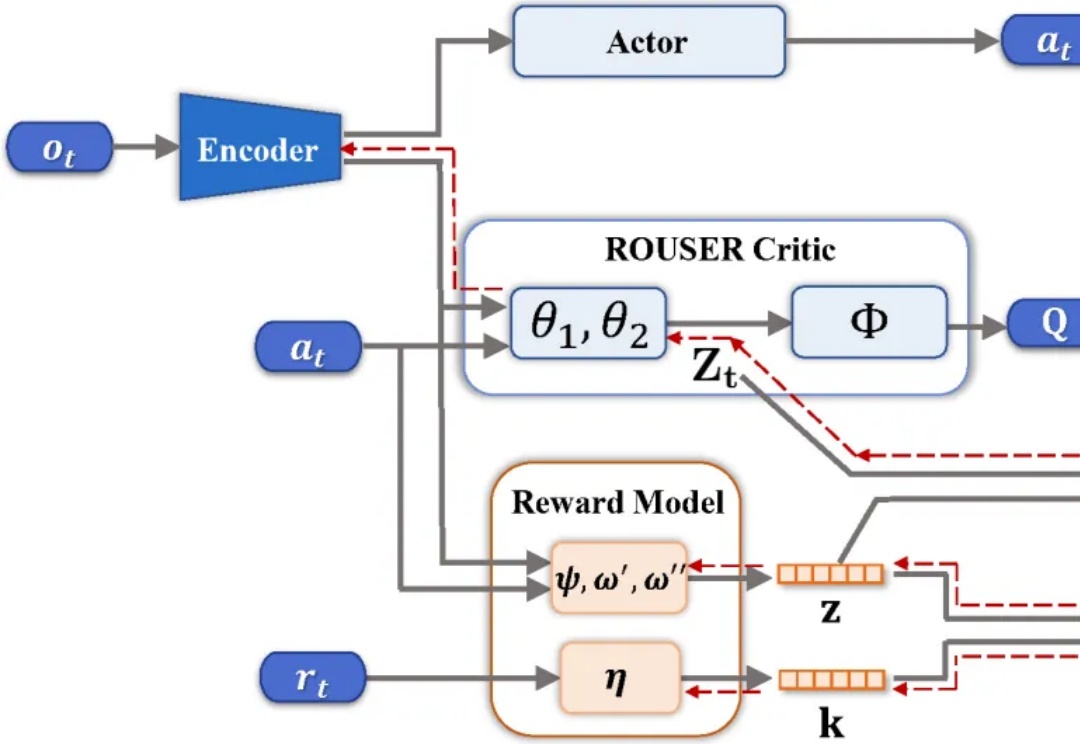
在视觉强化学习中,许多方法未考虑序列决策过程,导致所学表征缺乏关键的长期信息的空缺被填补上了。

你是否注意过人类观察世界的独特方式?

AI圈最热的风头莫过于GPT-4o的原生图像,但别急着下定论。Gemini 2.5 Pro正在悄悄反击,在Chatbot竞技场夺冠、IQ测试拿下第一后,它还能解魔方、建模型、创游戏,甚至一键生成3D打印文件!AI的下一个战场,正在从文字转向视觉与空间,谁能笑到最后?

给AI一张全新的照片,它能以相当高的准确率还猜出照片在哪个城市拍摄的。在新研究中,表现最好的AI模型,猜出图片所在城市的正确率比人类高62.6%!以后网上晒图可要当心了,AI可能知道你在哪里!
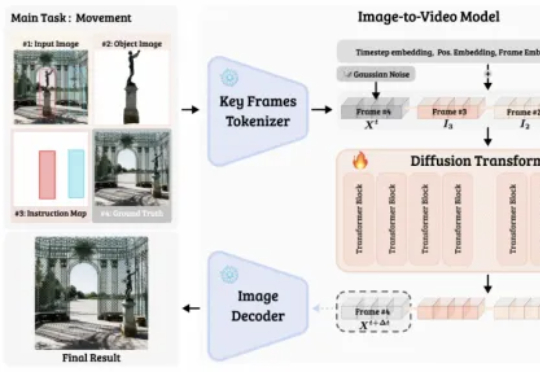
论文第一作者为余鑫,香港大学三年级博士生,通讯作者为香港大学齐晓娟教授。主要研究方向为生成模型及其在图像和 3D 中的应用,发表计算机视觉和图形学顶级会议期刊论文数十篇,论文数次获得 Oral, Spotlight 和 Best Paper Honorable Mention 等荣誉。此项研究工作为作者于 Adobe Research 的实习期间完成。

一夜之间,CV被大模型“解决”了(狗头)。万物皆可吉卜力之后,GPT-4o原生多模态图像生成更多玩法被开发出来。万物皆可吉卜力之后,GPT-4o原生多模态图像生成更多玩法被开发出来。

幻觉(Hallucination),即生成事实错误或不一致的信息,已成为视觉-语言模型 (VLMs)可靠性面临的核心挑战。随着VLMs在自动驾驶、医疗诊断等关键领域的广泛应用,幻觉问题因其潜在的重大后果而备受关注。

「仅需一次前向推理,即可预测相机参数、深度图、点云与 3D 轨迹 ——VGGT 如何重新定义 3D 视觉?」
阿里又发了个有意思的大模型——QVQ-Max,第一版视觉推理模型,对任意图像或视频都可以进行深度思考。