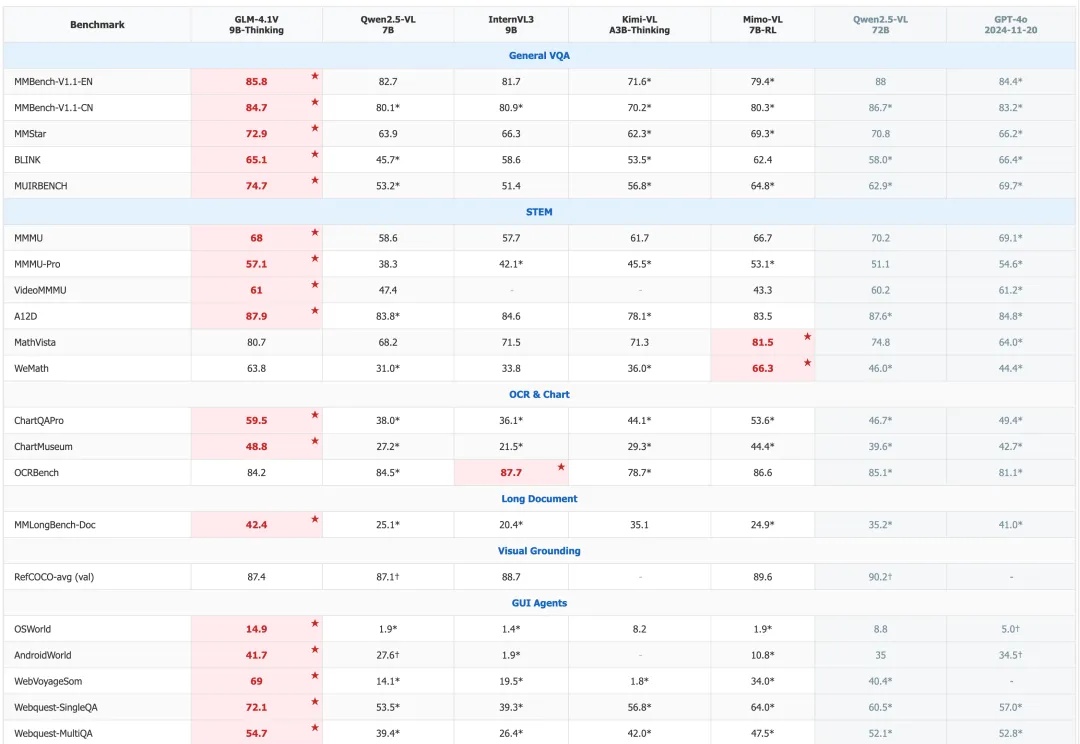
9B“小”模型干了票“大”的:性能超8倍参数模型,拿下23项SOTA | 智谱开源
9B“小”模型干了票“大”的:性能超8倍参数模型,拿下23项SOTA | 智谱开源如果一个视觉语言模型(VLM)只会“看”,那真的是已经不够看的了。
来自主题: AI技术研报
10477 点击 2025-07-02 15:56
 搜索
搜索
如果一个视觉语言模型(VLM)只会“看”,那真的是已经不够看的了。
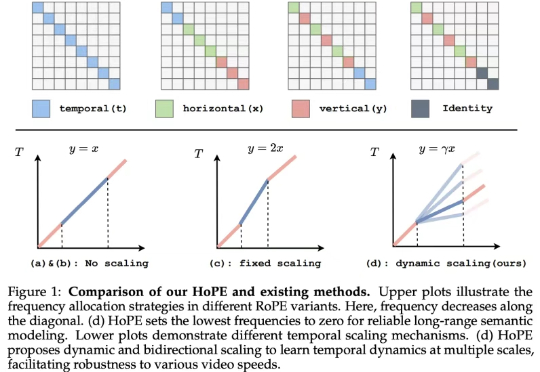
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。
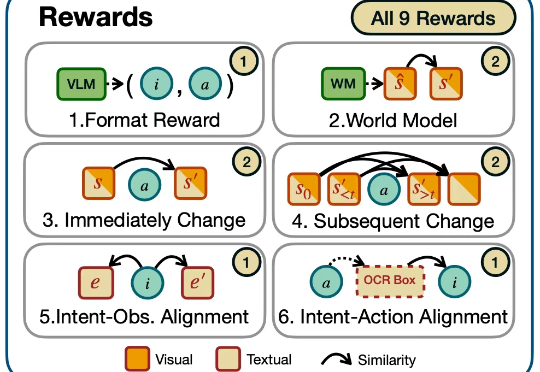
迈向通用人工智能(AGI)的核心目标之一就是打造能在开放世界中自主探索并持续交互的智能体。随着大语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,智能体已展现出令人瞩目的跨领域任务泛化能力。

当前大型视觉语言模型(LVLMs)存在物体幻觉问题,即会生成图像中不存在的物体描述。
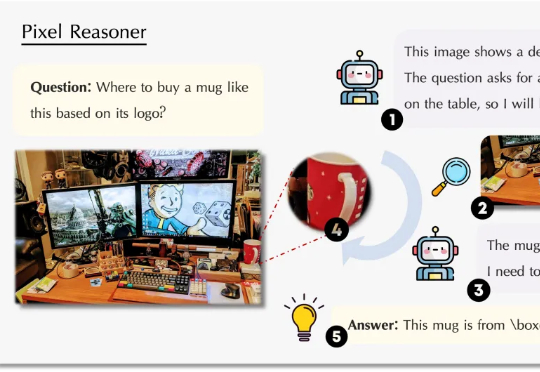
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。
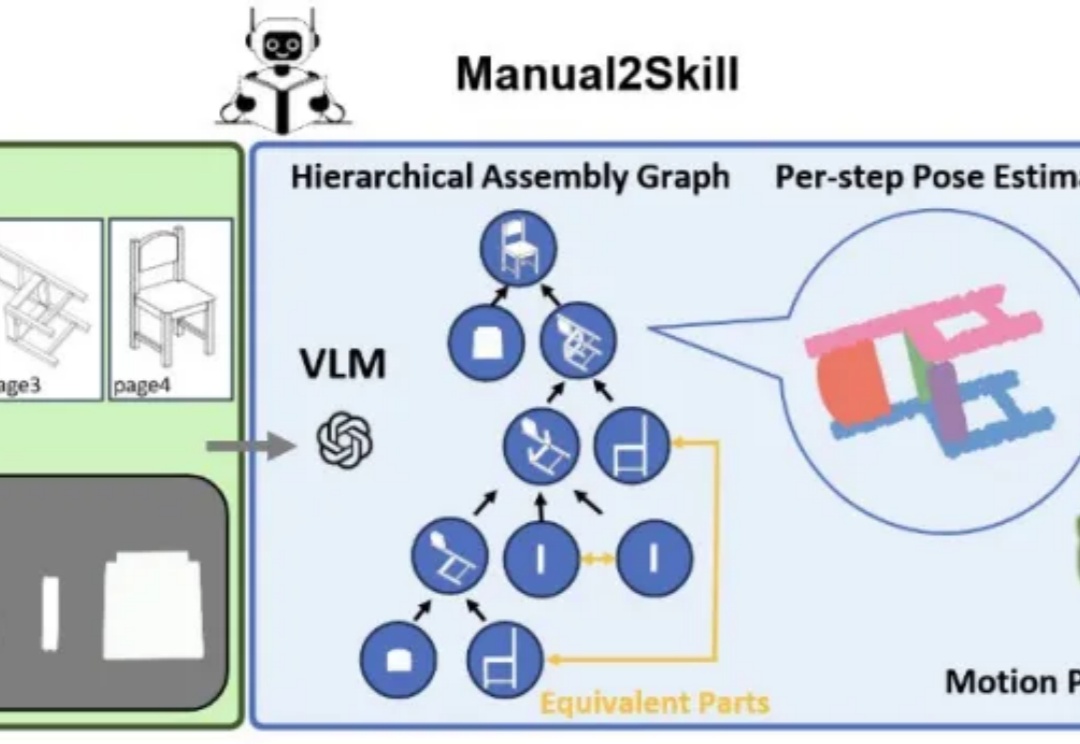
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。

在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
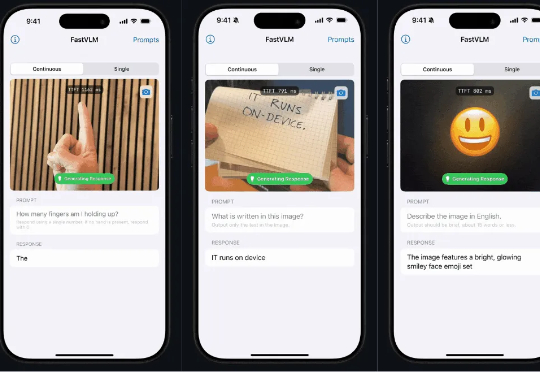
FastVLM—— 让苹果手机拥有极速视觉理解能力
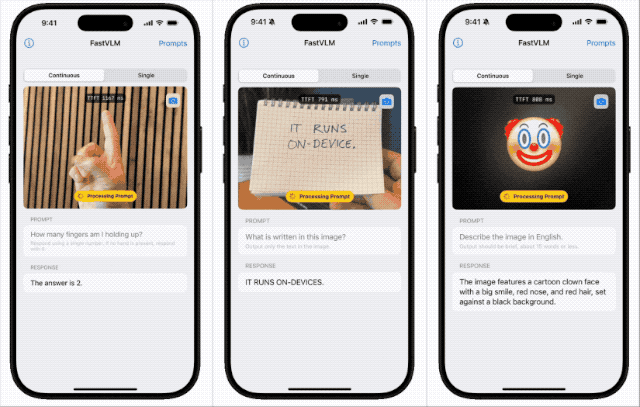
苹果近期开源本地端侧视觉语言模型FastVLM,支持iPhone等设备本地运行,具备快速响应、低延迟和多设备适配特性。该模型依托自研框架MLX和视觉架构FastViT-HD,通过算法优化实现高效推理,或为未来智能眼镜等新硬件铺路,体现苹果将AI深度嵌入系统底层的战略布局。
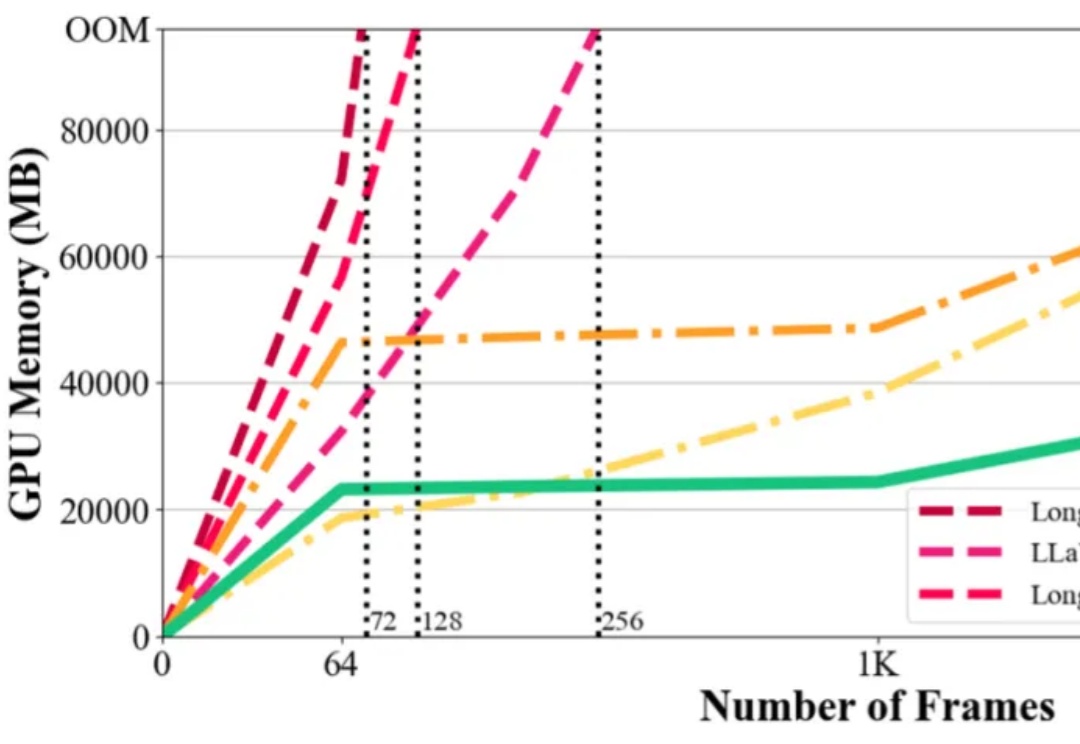
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。