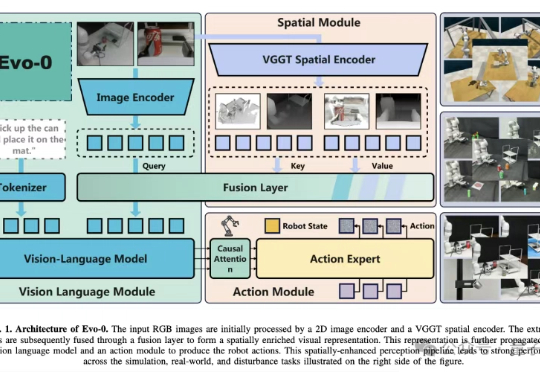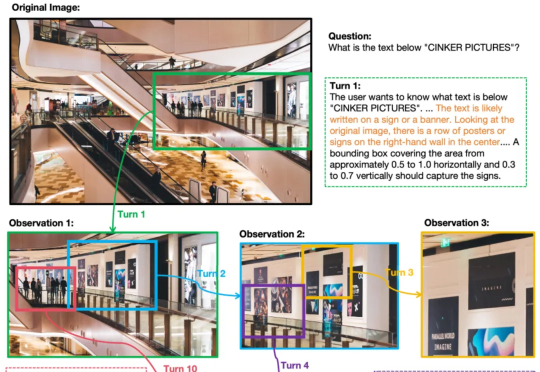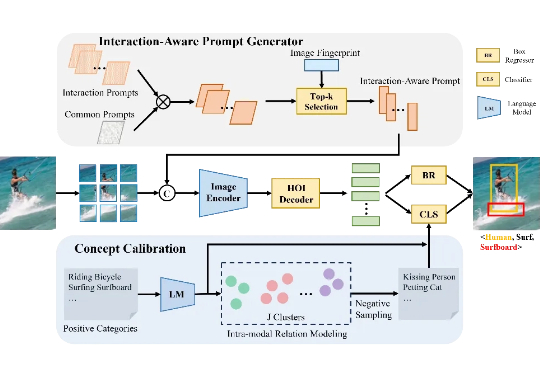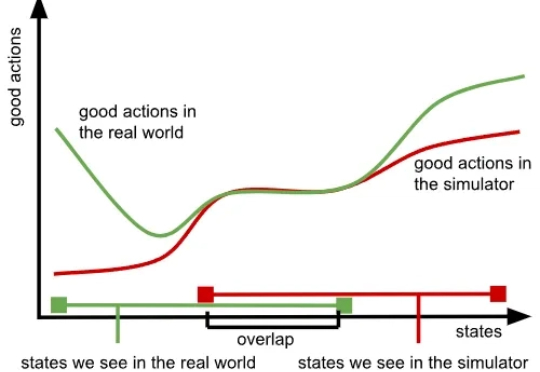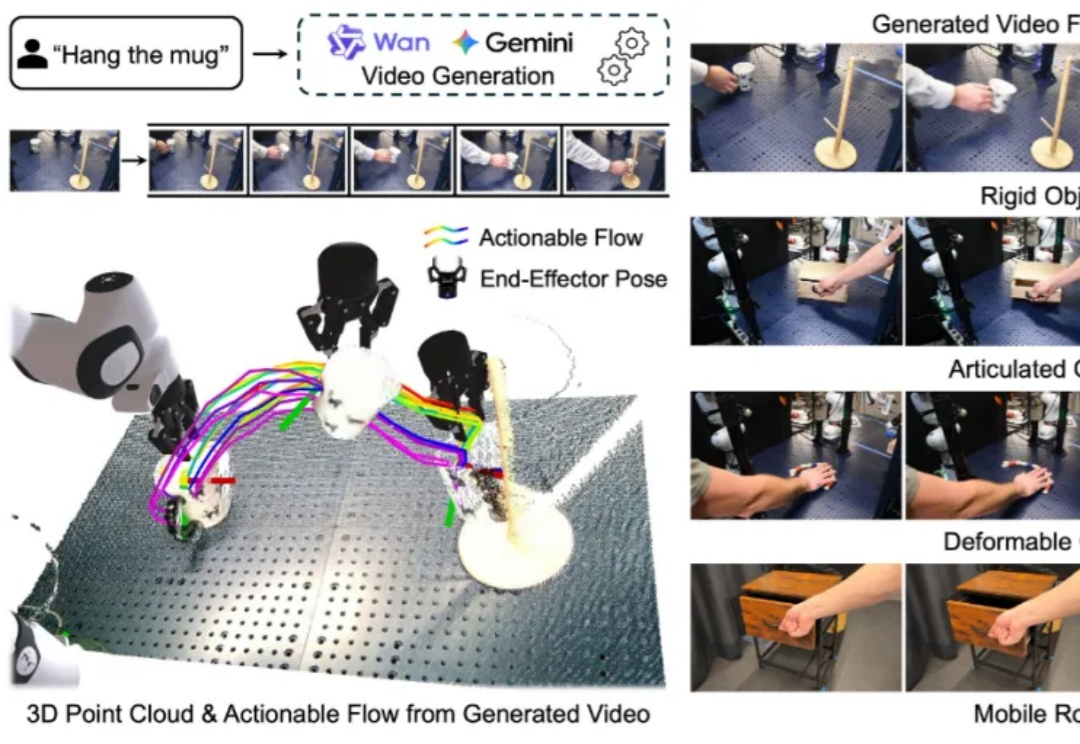
机器人「看片」自学新技能:NovaFlow从生成视频中提取动作流,实现零样本操控
机器人「看片」自学新技能:NovaFlow从生成视频中提取动作流,实现零样本操控构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。
来自主题: AI技术研报
9025 点击 2025-10-13 11:02