

是RAG已死,还是RAG Anything,All in RAG?
是RAG已死,还是RAG Anything,All in RAG?每隔一阵子,总有人宣告“RAG已死”:上下文越来越长、端到端多模态模型越来越强,好像不再需要检索与证据拼装。但真正落地到复杂文档与可溯源场景,你会发现死掉的只是“只切文本的旧RAG”。
来自主题: AI技术研报
7352 点击 2025-10-20 12:08
每隔一阵子,总有人宣告“RAG已死”:上下文越来越长、端到端多模态模型越来越强,好像不再需要检索与证据拼装。但真正落地到复杂文档与可溯源场景,你会发现死掉的只是“只切文本的旧RAG”。

Meta提出早期经验(Early Experience)让代理在无奖励下从自身经验中学习:在专家状态上采样替代动作、执行并收集未来状态,将这些真实后果当作监督信号。核心是把“自己造成的未来状态”转为可规模化的监督。

美团LongCat团队发布了当前高度贴近真实生活场景、面向复杂问题的大模型智能体评测基准——VitaBench(Versatile Interactive Tasks Benchmark)。VitaBench以外卖点餐、餐厅就餐、旅游出行三大高频生活场景为典型载体,构建了一个包含66个工具的交互式评测环境,并设计了跨场景综合任务。

OpenAI的封闭模型在IOI 2025竞赛夺金的同时,英伟达团队交出了一份同样令人振奋的答卷——他们利用完全开源的大模型和全新的GenCluster策略,在IOI 2025竞赛中跑出了媲美金牌选手的成绩!开源模型首次达到了IOI金牌水准。这究竟是怎样实现的?
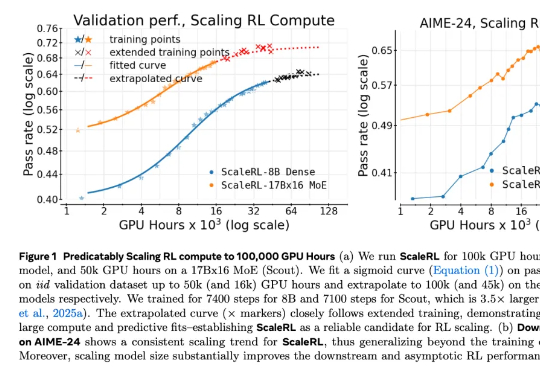
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?

麻省理工学院最新研究预示着人类距离能够自主学习的AI又迈出了关键一步。该研究推出了一种全新的自适应大模型框架「SEAL」,让模型从「被动学习者」变为「主动进化者」。
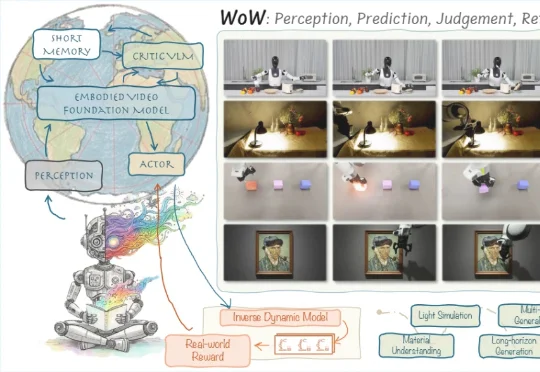
在「具身智能」与「世界模型」成为新一轮 AI 竞赛关键词的当下,来自北京人形机器人创新中心、北京大学多媒体信息处理国家重点实验室、香港科技大学的中国团队开源了全新的世界模型架构。
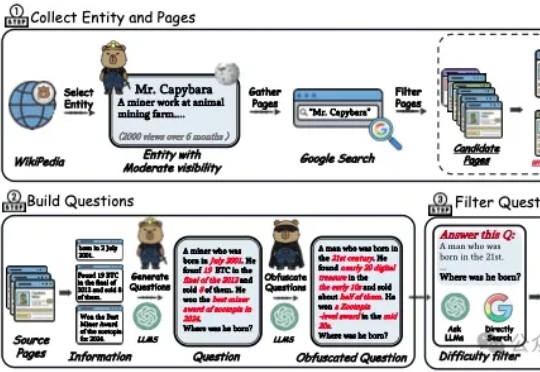
中科院的这篇工作解决了“深度搜索智能体”(deep search agents),两个实打实的工程痛点,一个是问题本身不够难导致模型不必真正思考,另一个是上下文被工具长文本迅速挤爆导致过程提前夭折,研究者直面挑战,从数据和系统两端同时重塑训练与推理流程,让复杂推理既有用又能跑得起来。
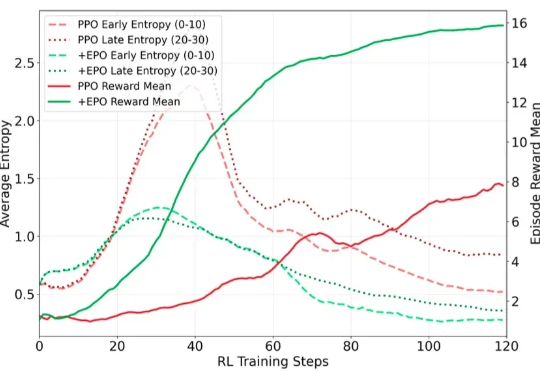
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
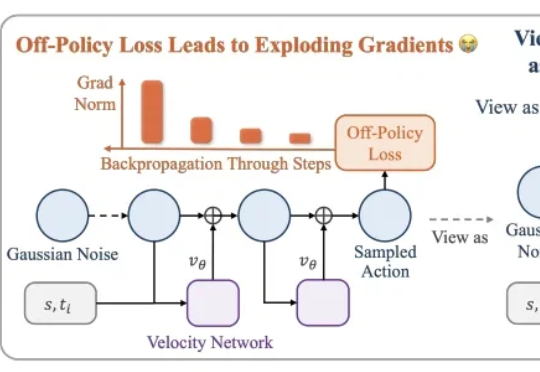
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。