
长上下文窗口、Agent崛起,RAG已死?
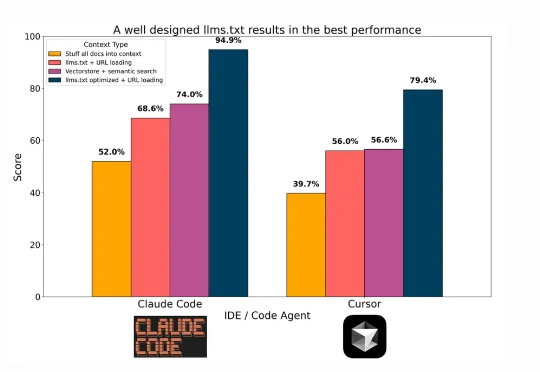
长上下文窗口、Agent崛起,RAG已死?在技术飞速更新迭代的今天,每隔一段时间就会出现「XX 已死」的论调。「搜索已死」、「Prompt 已死」的余音未散,如今矛头又直指 RAG。
来自主题: AI资讯
7745 点击 2025-10-20 15:03
在技术飞速更新迭代的今天,每隔一段时间就会出现「XX 已死」的论调。「搜索已死」、「Prompt 已死」的余音未散,如今矛头又直指 RAG。
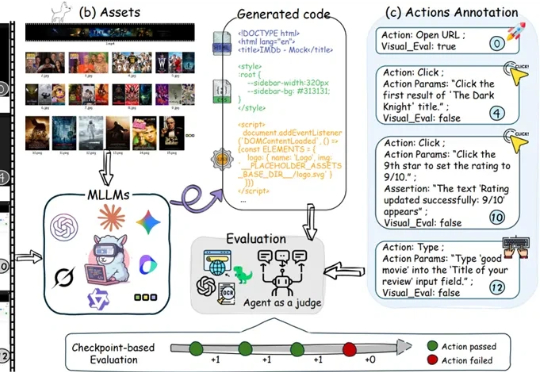
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
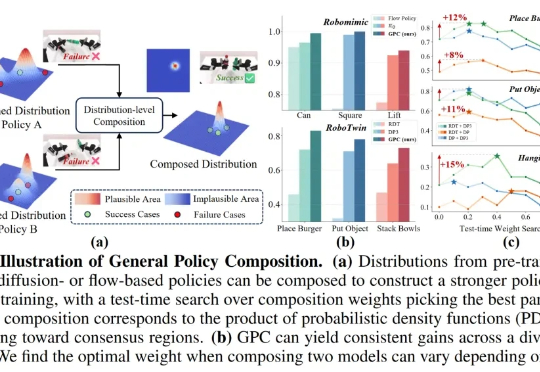
在机器人学习领域,提升基于生成式模型的控制策略(Policy)的性能通常意味着投入巨额成本进行额外的数据采集和模型训练,这极大地限制了机器人能力的快速迭代与升级。面对模型性能的瓶颈,如何在不增加训练负担的情况下,进一步挖掘并增强现有策略的潜力?

想象这样一个场景: 一个AI智能体在帮你处理邮件,一封看似正常的邮件里,却用一张图片的伪装暗藏指令。AI在读取图片时被悄然感染,之后它发给其他AI或人类的所有信息里,都可能携带上这个病毒,导致更大范围的感染和信息泄露。
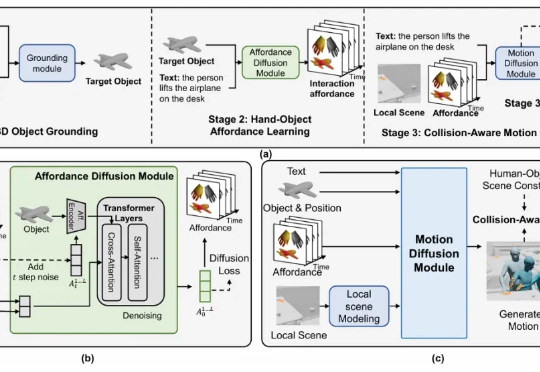
该研究首次提出了含可移动物体的 3D 场景中,基于文本的人 - 物交互生成任务,并构建了大规模数据集与创新方法框架,在多个评测指标上均取得了领先效果。
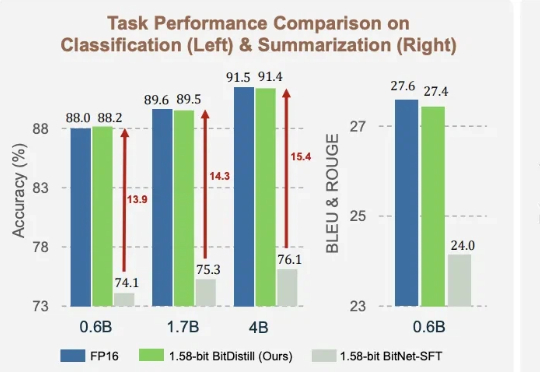
1.58bit量化,内存仅需1/10,但表现不输FP16? 微软最新推出的蒸馏框架BitNet Distillation(简称BitDistill),实现了几乎无性能损失的模型量化。
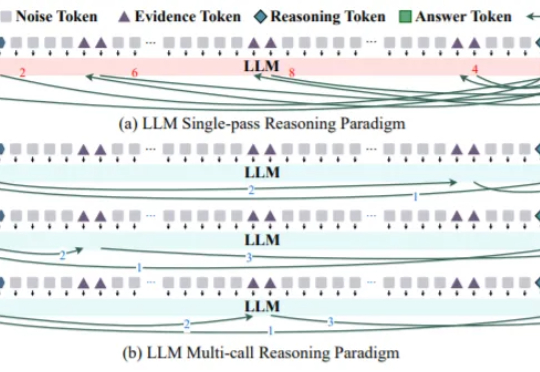
近日,来自阿联酋穆罕默德·本·扎耶德人工智能大学 MBZUAI 和保加利亚 INSAIT 研究所的研究人员发现一个针对大模型单次推理的“法诺式准确率上限”,借此不仅揭示了单次生成范式的根本性脆弱点,也揭示了“准确率悬崖”这一现象。

具身智能落地迈出关键一步,AI拥有第一人称与第三人称的“通感”了!
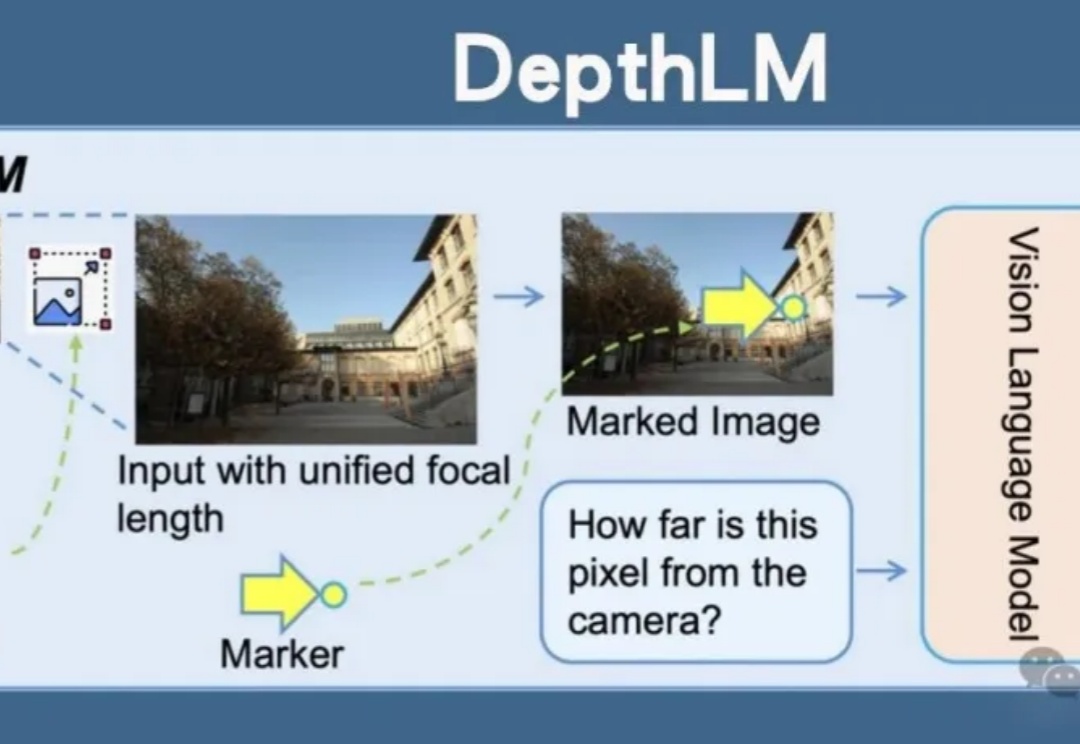
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
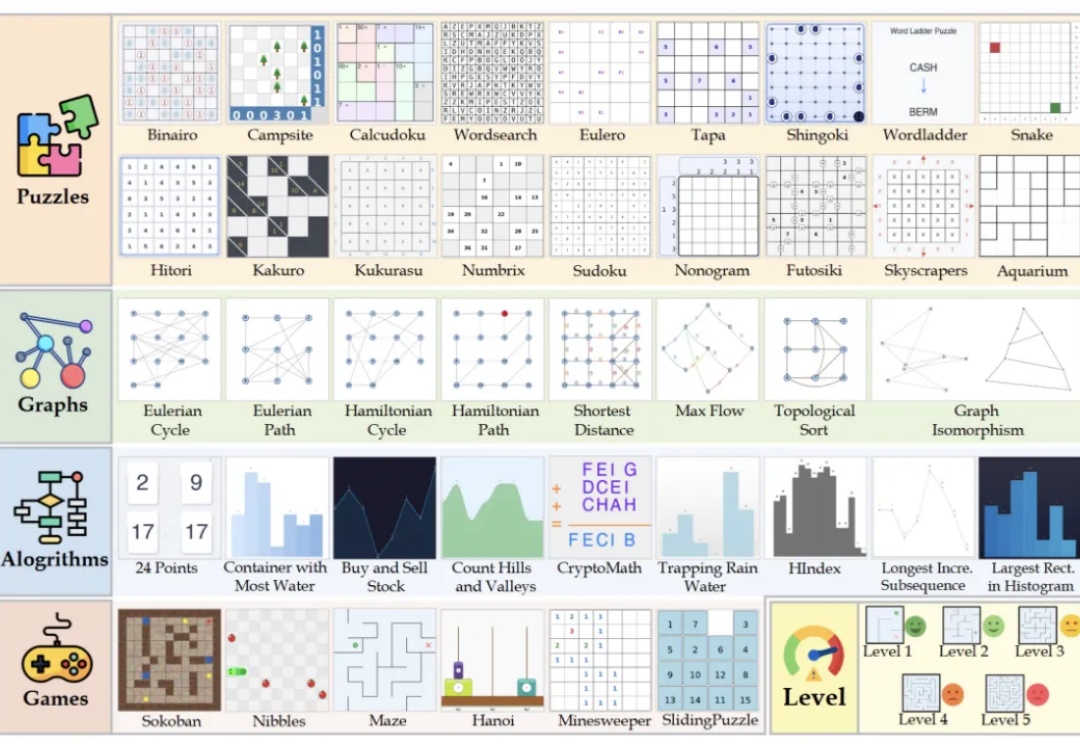
多模态大模型表现越来越惊艳,但人们也时常困于它的“耿直”。