
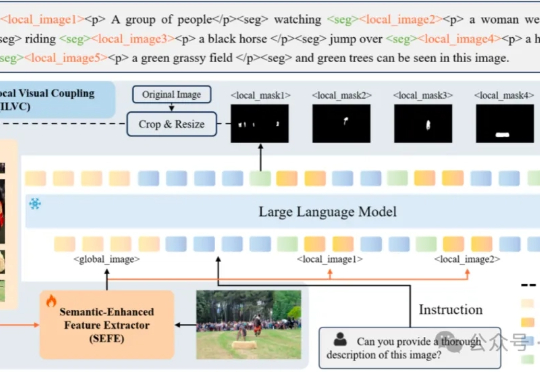
用两个简单模块实现分割理解双重SOTA!华科大白翔团队等推出多模态新框架
用两个简单模块实现分割理解双重SOTA!华科大白翔团队等推出多模态新框架多模态大模型需要干的活,已经从最初的文生图,扩展到了像素级任务(图像分割)。
来自主题: AI技术研报
7915 点击 2025-10-03 14:40
多模态大模型需要干的活,已经从最初的文生图,扩展到了像素级任务(图像分割)。

来自牛津大学、新加坡国立大学、伊利诺伊大学厄巴纳-香槟分校,伦敦大学学院、帝国理工学院、上海人工智能实验室等等全球 16 家顶尖研究机构的学者,共同撰写并发布了长达百页的综述:《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》。
只让机器人或虚拟智能体「想象」,不让它们和物理世界交互,它们也能学到和世界交互的技能?谷歌的世界模型 Dreamer 4 为这一想法提供了新的支撑。为了在具身环境中解决复杂任务,智能体需要深入理解世界并选择成功的行动。世界模型通过学习从智能体(如机器人或电子游戏玩家)的视角预测潜在行动的未来结果,为实现这一目标提供了一种有前景的方法。
Thinking Machines Lab发布首个产品:Thinker,让模型微调变得像改Python代码一样简单。也算是终于摘掉了“0产品0收入估值840亿”的帽子。Tinker受到了业界的密切关注。AI基础设施公司Anyscale的CEO Robert Nishihara等beta测试者表示,尽管市面上有其他微调工具,但Tinker在“抽象化和可调性之间取得了卓越的平衡”

这次英伟达可谓是“全家桶”式发布:不仅有让机器人拥有”物理直觉”的Newton引擎,还有赋予机器人人类推理能力的Isaac GR00T N1.6基础模型,以及能够生成海量训练数据的Cosmos世界基础模型,直接瞄准了机器人研发中最头疼的几个问题。

来自斯坦福大学、哥伦比亚大学、摩根大通AI研究院、卡耐基梅隆大学、英伟达提出了一种数据采集与策略学习框架DexUMI——利用人手作为自然接口将灵巧操作技能迁移至多种灵巧手。该框架通过硬件与软件的双重适配,最大限度缩小人手与各类灵巧手之间的具身差异。
小红书智创音频团队推出业内首个支持私有化部署的全双工大模型语音交互系统 FireRedChat,自研流式 pVAD 与 EoT 让语音交互更加自然,首发级联与半级联两套实现,端到端时延逼近工业级应用。

家人们,就在国庆放假前的今天凌晨,那个总在节前“搞事”的 DeepSeek,又双叒叕深夜悄然上线了!讲真,DeepSeek 是真的不考虑我们媒体人的死活啊哈哈!每次都卡着放假前更新,之前大家都转发的吐槽截图,本人又翻出来了:

OpenAI的后训练负责人和DeepMind的另一位AI4S大佬,双双离职并成立了一家AI4S公司Periodic Labs,专注于用AI Agent改造传统科研,助力攻克室温超导等世纪难题。目前该公司已获3亿美元融资。

蚂蚁通用人工智能中心自然语言组联合香港大学自然语言组(后简称“团队”)推出PromptCoT 2.0,要在大模型下半场押注任务合成。实验表明,通过“强起点、强反馈”的自博弈式训练,PromptCoT 2.0可以让30B-A3B模型在一系列数学代码推理任务上实现新的SOTA结果,达到和DeepSeek-R1-0528, OpenAI o3, Gemini 2.5 Pro等相当的表现。