
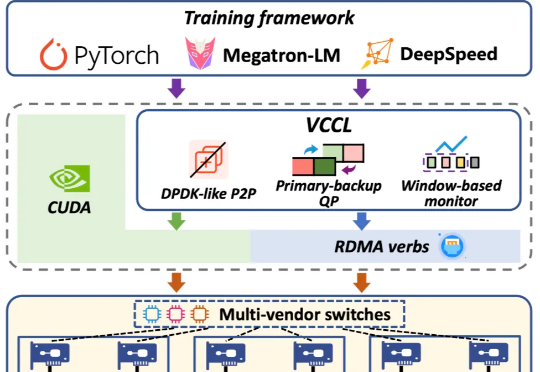
集合通信库VCCL释放GPU极致算力,创智、基流、智谱、联通、北航、清华、东南重磅开源
集合通信库VCCL释放GPU极致算力,创智、基流、智谱、联通、北航、清华、东南重磅开源创智、基流、智谱、联通、北航、清华、东南联合打造了高效率、高可靠、高可视的 GPU 集合通信库 VCCL(Venus Collective Communication Library),VCCL 已部署于多个生产环境集群中。
来自主题: AI技术研报
8180 点击 2025-09-21 11:08
创智、基流、智谱、联通、北航、清华、东南联合打造了高效率、高可靠、高可视的 GPU 集合通信库 VCCL(Venus Collective Communication Library),VCCL 已部署于多个生产环境集群中。
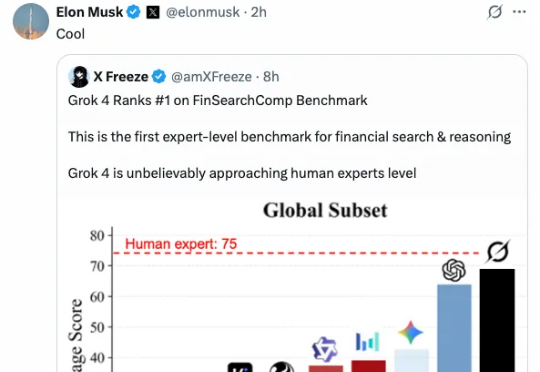
字节跳动Seed团队联合哥伦比亚大学商学院推出了FinSearchComp,这是首个完全开源的金融搜索与推理基准测试。该基准包含635个金融专家精心设计的问题,覆盖全球和大中华两个市场,并在多个主流模型产品上进行了全面评测。

拿下中国AI云市场第一后,阿里云又敞开说了。 援引第三方机构Omdia数据,中国AI云市场规模达到223亿元,阿里云占比35.8%位列第一。围绕这一领先地位的技术根基,阿里云的弹性计算、集群、容器、人工智能平台等技术产品负责人来了场AI Infra分享会。
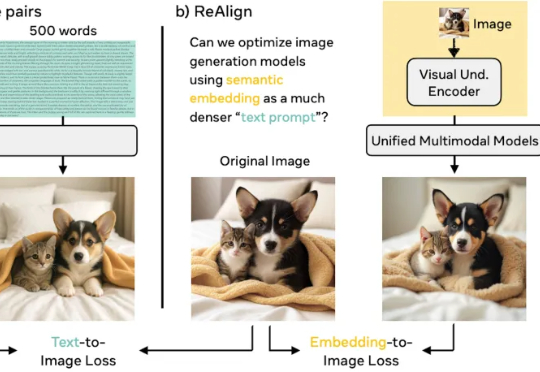
谢集,浙江大学竺可桢学院大四学生,于加州大学伯克利分校(BAIR)进行访问,研究方向为统一多模态理解生成大模型。第二作者为加州大学伯克利分校的 Trevor Darrell,第三作者为华盛顿大学的 Luke Zettlemoyer,通讯作者是 XuDong Wang, Meta GenAl Research Scientist、
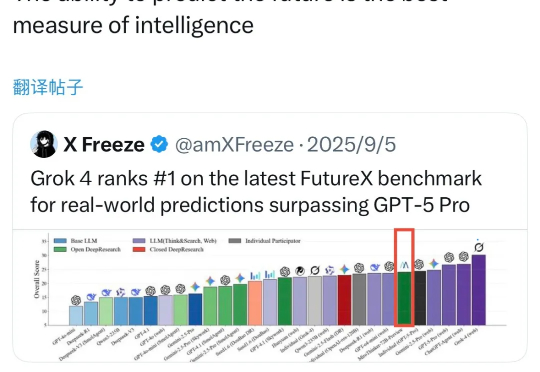
全球创新企业家、慈善家陈天桥旗下的 MiroMind 团队在这一 AI 未来大考中,连续第二周蝉联冠军。与专注文本输出的生成式模型不同,MiroMind 采用记忆驱动机制,专为预测与决策设计,旨在打造全球最好的预测大模型。
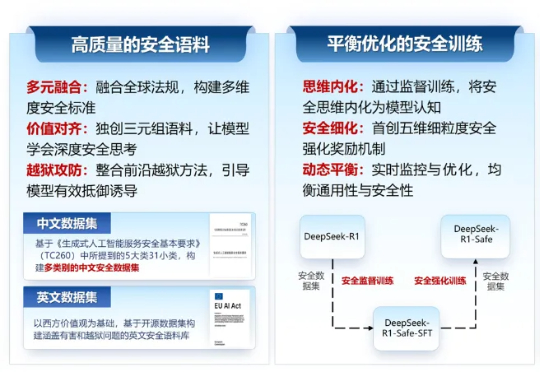
2025年9月18日,由浙江大学计算机科学与技术学院院长、区块链与数据安全全国重点实验室常务副主任任奎教授团队联合华为技术有限公司计算产品线共同研发的国内首个基于昇腾千卡算力平台的DeepSeek-R1-Safe基础大模型在“华为全联接大会2025”正式发布。

几周前,我们发布了 jina-embeddings-v4 模型的 GGUF 版本,大幅降低了显存占用,提升了运行效率。不过,受限于 llama.cpp 上游版本的运行时,当时的 GGUF 模型只能当作文本向量模型使用而无法支持多模态向量的输出。

宝可梦游戏的开放世界、长周期、巨大行动空间和高难度特性,为训练能应对现实世界复杂性(如稀疏奖励、探索挑战)的AI提供了理想沙盒。对比AI的机械尝试和人类的“乐趣驱动”探索,文章阐释人类特有的好奇心美学对于科学发现的关键价值,并探讨AI赋能游戏设计(个性化体验、无限故事/行动空间)以优化人类乐趣的潜力。

就在最新的Nature新刊中,DeepSeek一举成为首家登上《Nature》封面的中国大模型公司,创始人梁文锋担任通讯作者。纵观全球,之前也只有极少数如DeepMind者,凭借AlphaGo、AlphaFold有过类似荣誉。
最近在 B 站上,你是否也刷到过一些 “魔性” 又神奇的 AI 视频?比如英文版《甄嬛传》、坦克飞天、曹操大战孙悟空…… 这些作品不仅完美复现了原角色的音色,连情感和韵律都做到了高度还原!更让人惊讶的是,它们居然全都是靠 AI 生成的!