

AI革命下一站:Anthropic与OpenAI斥巨资打造“虚拟员工”
AI革命下一站:Anthropic与OpenAI斥巨资打造“虚拟员工”9月17日消息,AI领域的两大巨头Anthropic和OpenAI正致力于开发能够替代人类执行复杂工作的“AI同事”。其核心方法是使用模拟企业软件来训练AI模型,使其能像人类员工那样理解和操作真实的工作流程。
来自主题: AI资讯
9211 点击 2025-09-17 16:46
9月17日消息,AI领域的两大巨头Anthropic和OpenAI正致力于开发能够替代人类执行复杂工作的“AI同事”。其核心方法是使用模拟企业软件来训练AI模型,使其能像人类员工那样理解和操作真实的工作流程。
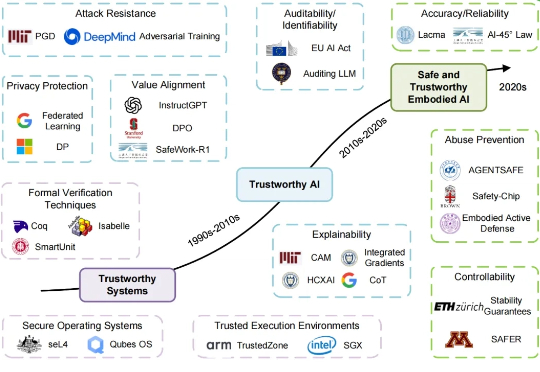
近年来,以人形机器人、自动驾驶为代表的具身人工智能(Embodied Artificial Intelligence, EAI)正以前所未有的速度发展,从数字世界大步迈向物理现实。然而,当一次错误的风险不再是屏幕上的一行乱码,而是可能导致真实世界中的物理伤害时,一个紧迫的问题摆在了我们面前: 如何确保这些日益强大的具身智能体是安全且值得信赖的?
谷歌DeepMind研究团队一年前的研究成果直到昨晚才姗姗揭秘,提出了一种叫做GDR的新方法,颠覆了传统训练中设法剔除脏数据的思路,将饱含恶意内容的数据「变废为宝」,处理后的数据集用于训练,甚至比直接剔除脏数据训练出的模型效果还好,「出淤泥而不染」,「择善而从」。

近日,全球网络通信顶会 ACM SIGCOMM 2025 在葡萄牙落幕,共 3 篇论文获奖,华为网络技术实验室与香港科技大学 iSING Lab 合作的 DCP 研究成果,获本届大会 Best Student Paper Award (Honorable Mention),成为亚洲地域唯一获奖的论文。
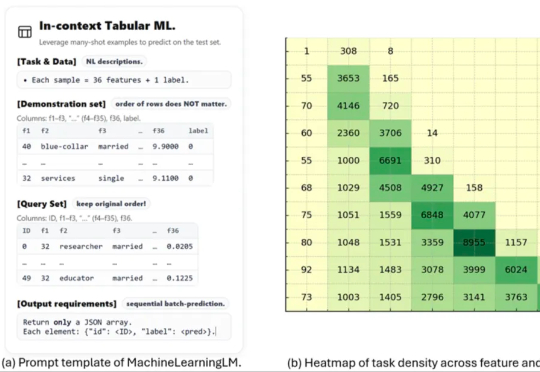
这项名为 MachineLearningLM 的新研究突破了这一瓶颈。该研究提出了一种轻量且可移植的「继续预训练」框架,无需下游微调即可直接通过上下文学习上千条示例,在金融、健康、生物信息、物理等等多个领域的二分类 / 多分类任务中的准确率显著超越基准模型(Qwen-2.5-7B-Instruct)以及最新发布的 GPT-5-mini。

本周,我们关注 Agent 与工业结合正在发生的变化,我们邀请研发时序大模型 Geegobyte-g1 以及工业智能体平台「河谷」的初创企业极峰科技的创始人王筱圃,和我们聊一聊什么是时序大模型,和大语言模型的区别和具体的案例,他们如何训练一个 Agent 并把它卖给企业投入到生产流程中。希望能对大家了解 AI Agent 如何应用于工业生产有所帮助。

只要科学任务可以评分,AI就能找到超越人类专家的方法,实现SOTA结果? 这是谷歌一篇最新论文里的内容: 使用大模型+树搜索,让AI大海捞针就行。

上周,福布斯、Wired等争相报道「全球最快开源推理模型」K2-Think,,甚至图灵奖得主Yann LeCun转发推文。但仅三天后,ETH五位研究员的博客如晴天霹雳:87数学评估题竟藏在训练集中!这不仅仅是技术突破,更是行业诚信的警钟。

什么情况,帮马斯克训练大模型的人说失业就失业了?上周四晚,xAI内部上演了一场突袭测试,还要求员工必须在第二天早上之前完成并提交。这可不是一次简单的随堂测试——截至目前,本次xAI内部测试的淘汰率高达33%,已有超过500名员工被通知卷铺盖走人。

人类的大脑,会在梦里筛选记忆。如今,AI也开始学会在「睡眠」中整理、保存,甚至遗忘。Bilt部署数百万智能体,让科幻小说里的设问——「仿生人会梦见电子羊吗?」——逐步成真。那么,当AI也能选择忘记时,它会变得更像人,还是更陌生?