

LLM会梦到AI智能体吗?不,是睡着了也要加班
LLM会梦到AI智能体吗?不,是睡着了也要加班人类的大脑,会在梦里筛选记忆。如今,AI也开始学会在「睡眠」中整理、保存,甚至遗忘。Bilt部署数百万智能体,让科幻小说里的设问——「仿生人会梦见电子羊吗?」——逐步成真。那么,当AI也能选择忘记时,它会变得更像人,还是更陌生?
来自主题: AI资讯
7957 点击 2025-09-16 15:55
人类的大脑,会在梦里筛选记忆。如今,AI也开始学会在「睡眠」中整理、保存,甚至遗忘。Bilt部署数百万智能体,让科幻小说里的设问——「仿生人会梦见电子羊吗?」——逐步成真。那么,当AI也能选择忘记时,它会变得更像人,还是更陌生?

很多人认为,Scaling Law 正在面临收益递减,因此继续扩大计算规模训练模型的做法正在被质疑。最近的观察给出了不一样的结论。研究发现,哪怕模型在「单步任务」上的准确率提升越来越慢,这些小小的进步叠加起来,也能让模型完成的任务长度实现「指数级增长」,而这一点可能在现实中更有经济价值。
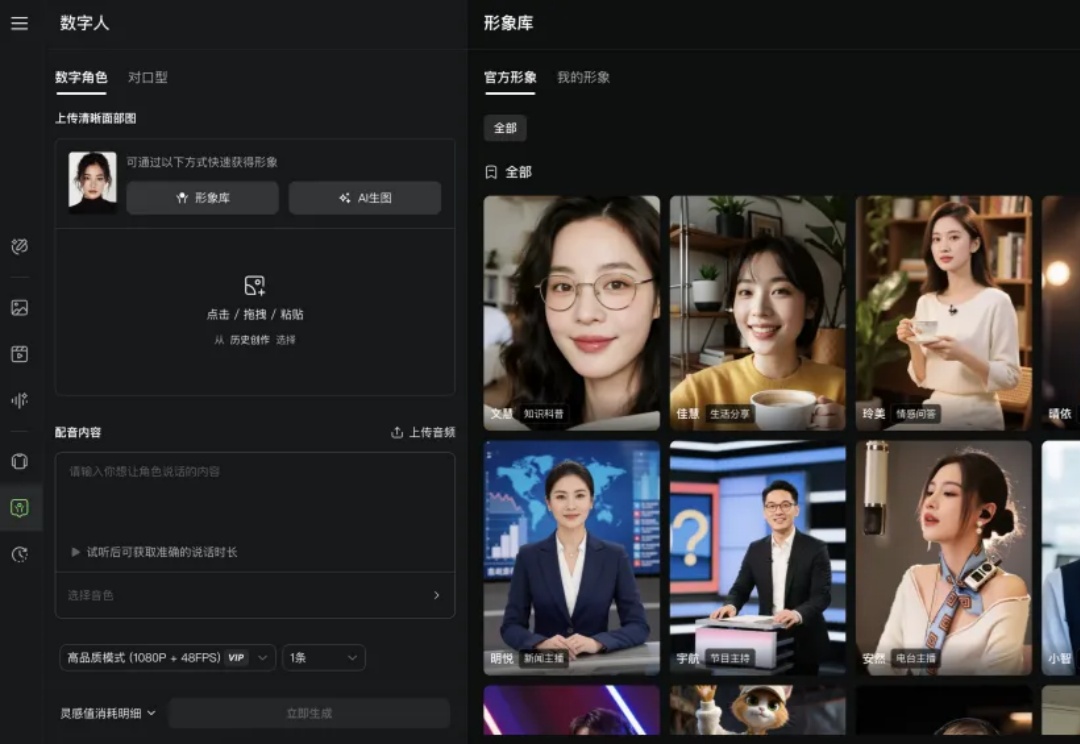
让数字人的口型随着声音一开一合早已不是新鲜事。更令人期待的,是当明快的旋律响起,它会自然扬起嘴角,眼神含笑;当进入说唱段落,它会随着鼓点起伏,肩膀与手臂有节奏地带动气氛。
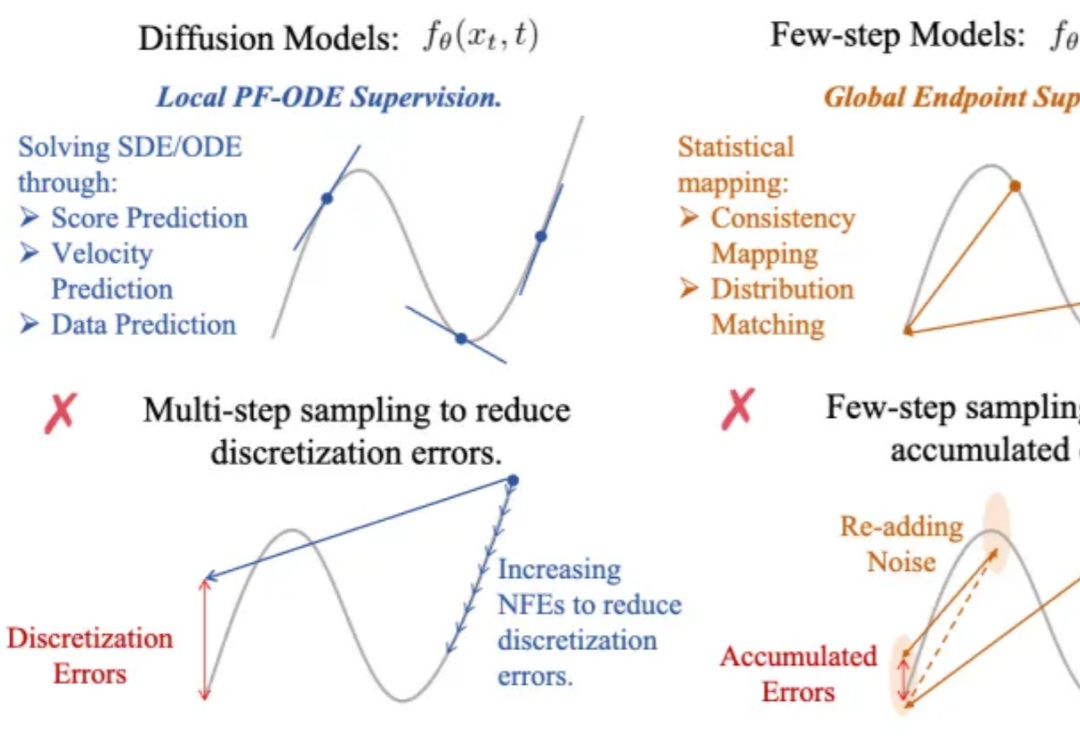
生成式AI的快与好,终于能兼得了?

随着Agent的爆发,大型语言模型(LLM)的应用不再局限于生成日常对话,而是越来越多地被要求输出像JSON或XML这样的结构化数据。这种结构化输出对于确保安全性、与其他软件系统互操作以及执行下游自动化任务至关重要。
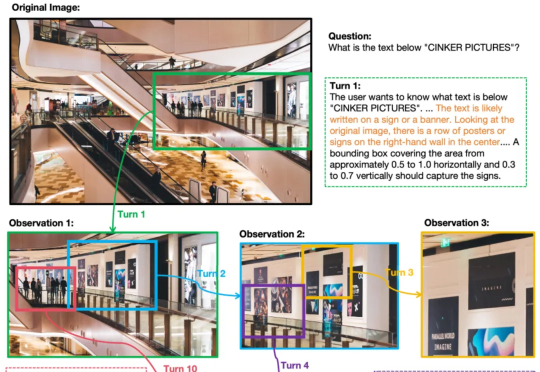
OpenAI o3的多轮视觉推理,有开源平替版了。并且,与先前局限于1-2轮对话的视觉语言模型(VLM)不同,它在训练限制轮数只有6轮的情况下,测试阶段能将思考轮数扩展到数十轮。

自动化修复真实世界的软件缺陷问题是自动化程序修复研究社区的长期目标。然而,如何自动化解决视觉软件缺陷仍然是一个尚未充分探索的领域。最近,随着 SWE-bench 团队发布最新的多模态 Issue 修复
最近,来自加州大学圣克鲁兹分校、乔治·梅森大学和Datadog的研究人员发现:在心算任务中,几乎所有实际的数学计算都集中在序列的最后一个token上完成,而不是分散在所有token中。
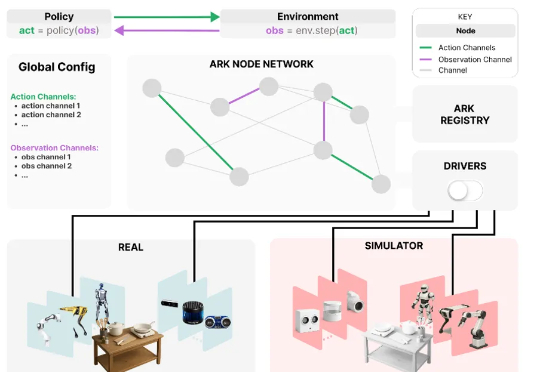
为应对这些挑战,来自华为诺亚方舟实验室,德国达姆施塔特工业大学,英国伦敦大学学院,帝国理工学院和牛津大学的研究者们联合推出了 Ark —— 一个基于 Python 的机器人开发框架,支持快速原型构建,并可便捷地在仿真和真实机器人系统上部署新算法。
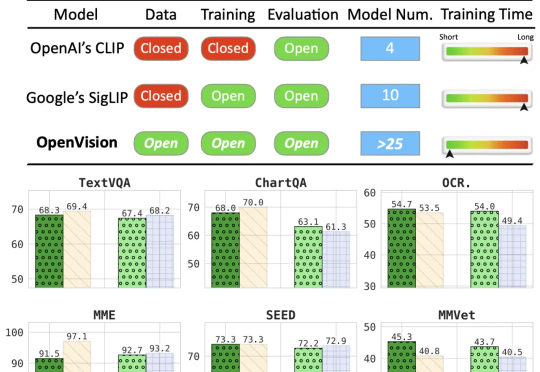
本文来自加州大学圣克鲁兹分校(UCSC)、苹果公司(Apple)与加州大学伯克利分校(UCB)的合作研究。第一作者刘彦青,本科毕业于浙江大学,现为UCSC博士生,研究方向包括多模态理解、视觉-语言预训