
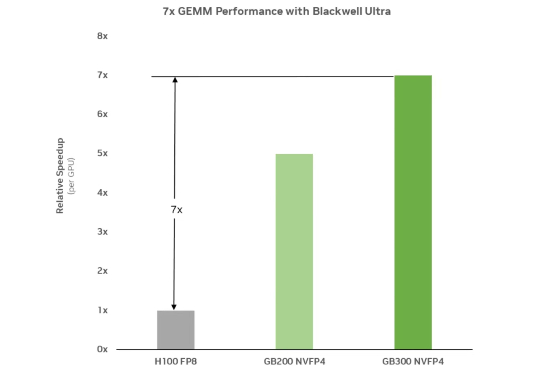
DeepSeek刚提到FP8,英伟达就把FP4精度推向预训练,更快、更便宜
DeepSeek刚提到FP8,英伟达就把FP4精度推向预训练,更快、更便宜前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。
来自主题: AI资讯
8682 点击 2025-08-28 15:40
前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。

传统 video dubbing 技术长期受限于其固有的 “口型僵局”,即仅能编辑嘴部区域,导致配音所传递的情感与人物的面部、肢体表达严重脱节,削弱了观众的沉浸感。现有新兴的音频驱动视频生成模型,在应对长视频序列时也暴露出身份漂移和片段过渡生硬等问题。
近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。
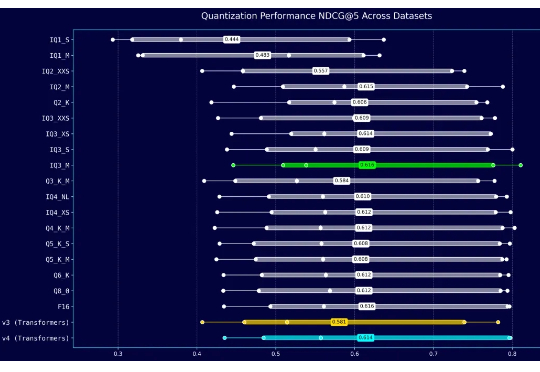
两周前,我们发布了 jina-embeddings-v4 的 GGUF 格式及其多种动态量化版本。jina-embeddings-v4 原模型有 37.5 亿参数,在我们的 GCP G2 GPU 实例上直接运行时效率不高。因此,我们希望通过更小、更快的 GGUF 格式来加速推理。
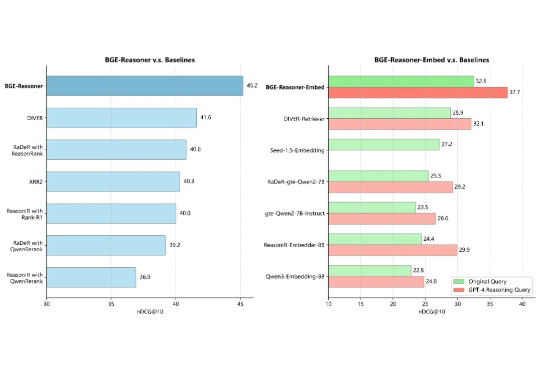
人工智能的浪潮正将我们推向一个由 RAG 和 AI Agent 定义的新时代。然而,要让这些智能体真正「智能」,而非仅仅是信息的搬运工,就必须攻克一个横亘在所有顶尖团队面前的核心难题。这个难题,就是推理密集型信息检索(Reasoning-Intensive IR)。

人类和AI在工作中如何协作?耶鲁和南大的研究人员合作的这篇论文讲清楚了。 这篇论文提出了一个数学框架,通过把工作技能拆分成两个层次来解释这个问题
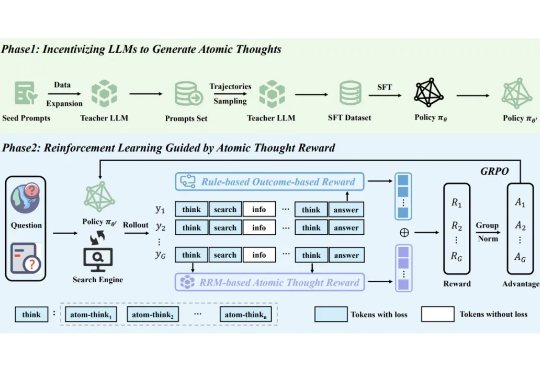
尽管 LLM 的能力与日俱增,但其在复杂任务上的表现仍受限于静态的内部知识。为从根本上解决这一限制,突破 AI 能力界限,业界研究者们提出了 Agentic Deep Research 系统,在该系统中基于 LLM 的 Agent 通过自主推理、调用搜索引擎和迭代地整合信息来给出全面、有深度且正确性有保障的解决方案。
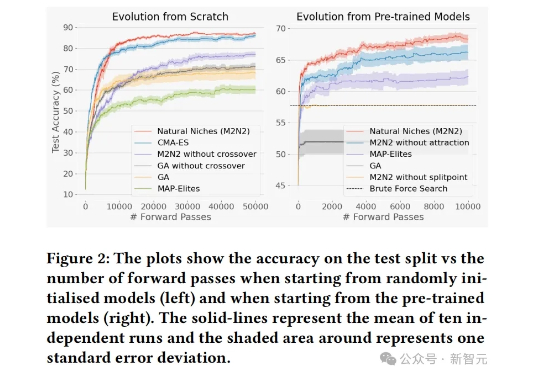
Sakana AI以自然演化为灵感,提出了一种全新的模型融合进化方法M2N2。通过引入自然界的「择偶机制」,AI可以像生物一样「竞争、择偶、繁衍」。在当前全球算力短缺、模型训练实际规模受制的情况下,Sakana AI借助自然界的启示,为模型融合探索出了一条新路。
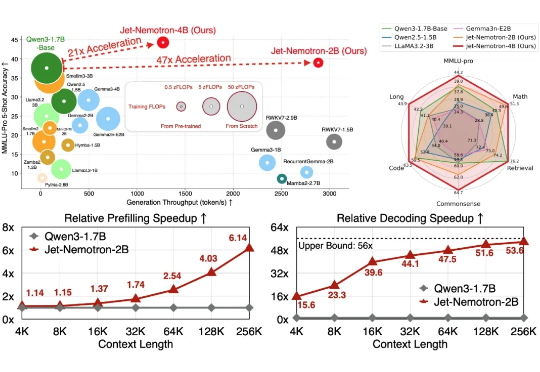
Transformer 架构对计算和内存的巨大需求使得大模型效率的提升成为一大难题。为应对这一挑战,研究者们投入了大量精力来设计更高效的 LM 架构。
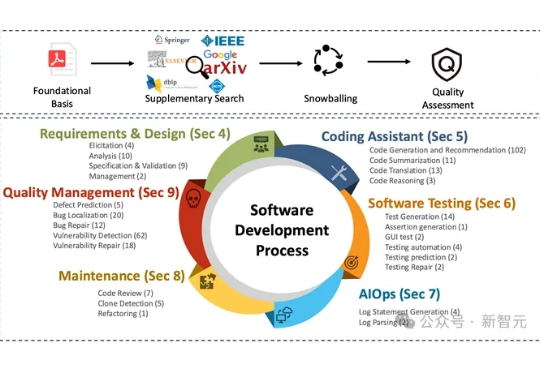
大语言模型正加速重塑软件工程领域的各个环节,从需求分析到代码生成,再到自动化测试,几乎无所不能,但衡量这些模型到底「好不好用」、「好在哪里」、「还有哪些短板」,一直缺乏系统、权威的评估工具。