
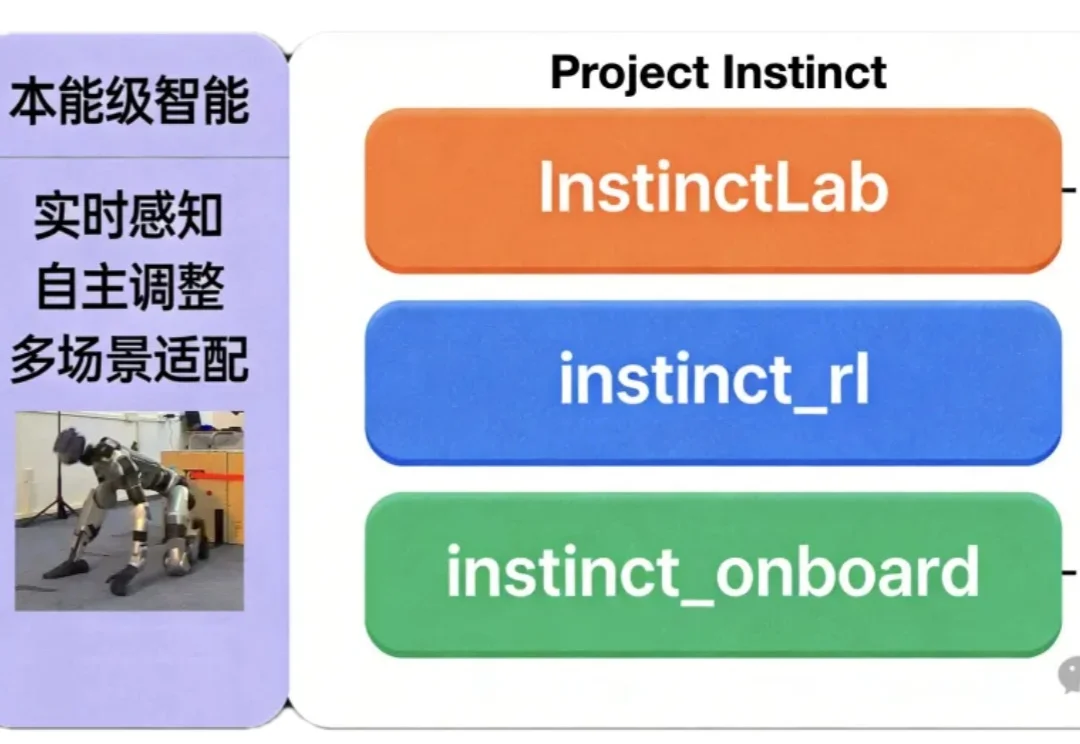
让机器人拥有本能反应!清华开源:一套代码实现跑酷、野外徒步两大能力
让机器人拥有本能反应!清华开源:一套代码实现跑酷、野外徒步两大能力如何让机器人同时具备“本能反应”与复杂运动能力?
来自主题: AI技术研报
9460 点击 2026-01-22 16:11
如何让机器人同时具备“本能反应”与复杂运动能力?
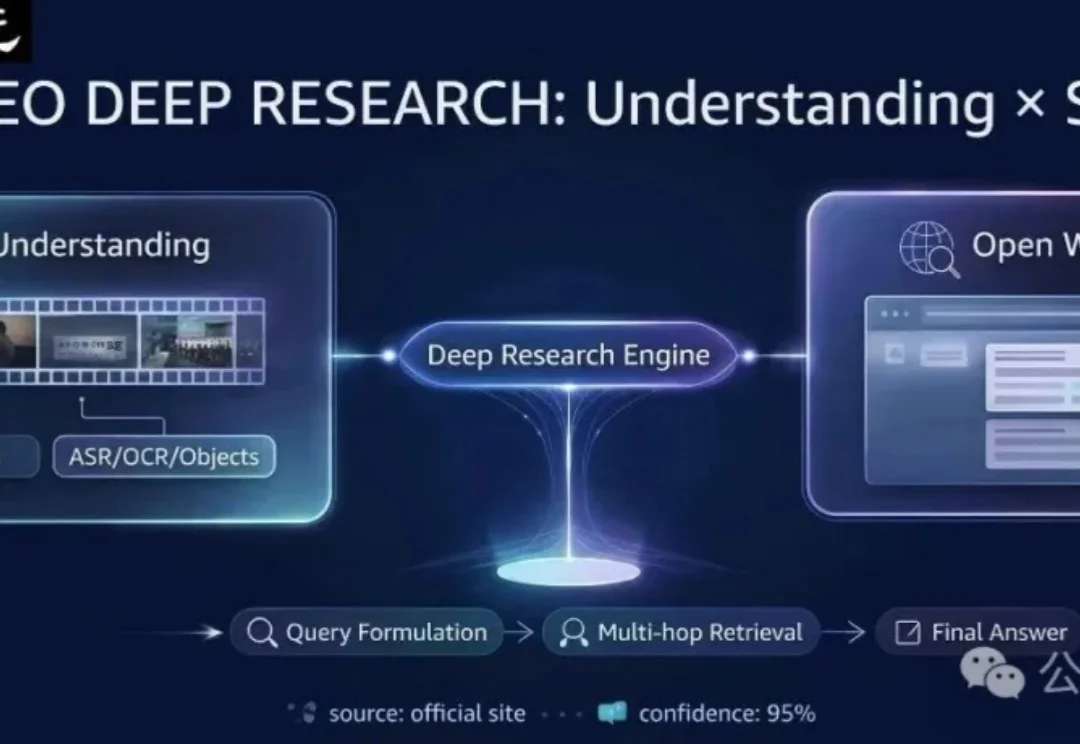
现有的多模态模型往往被困在「视频」的孤岛里——它们只能回答视频内的问题。但在真实世界中,人类解决问题往往是「看视频找线索 -> 上网搜证 -> 综合推理」。

就在刚刚,Liquid AI 又一次在 LFM 模型上放大招。他们正式发布并开源了 LFM2.5-1.2B-Thinking,一款可完全在端侧运行的推理模型。Liquid AI 声称,该模型专门为简洁推理而训练;在生成最终答案前,会先生成内部思考轨迹;在端侧级别的低延迟条件下,实现系统化的问题求解;在工具使用、数学推理和指令遵循方面表现尤为出色。
竟然只需要一次Ctrl+V?这可能是深度学习领域为数不多的“免费午餐”。
Agent很好,但要做好工具调用能才能跑得通。
近日,中国科学技术大学(USTC)联合新疆师范大学、中关村人工智能研究院、香港理工大学,在数据驱动的多功能双连通多尺度结构逆向设计领域取得重要突破。

现有AI记忆评测存在局限,如数据源单一、忽视变化本质、注入成本高等。CloneMem通过层次化生成框架构建合成人生,设计贴近真实场景的评测任务,涵盖多种问题类型。
在具身智能(Embodied AI)的快速发展中,样本效率已成为制约智能体从实验室环境走向复杂开放世界的瓶颈问题。
今天的 Agent,在一个独立的、短时间任务上的表现已经很不错了。
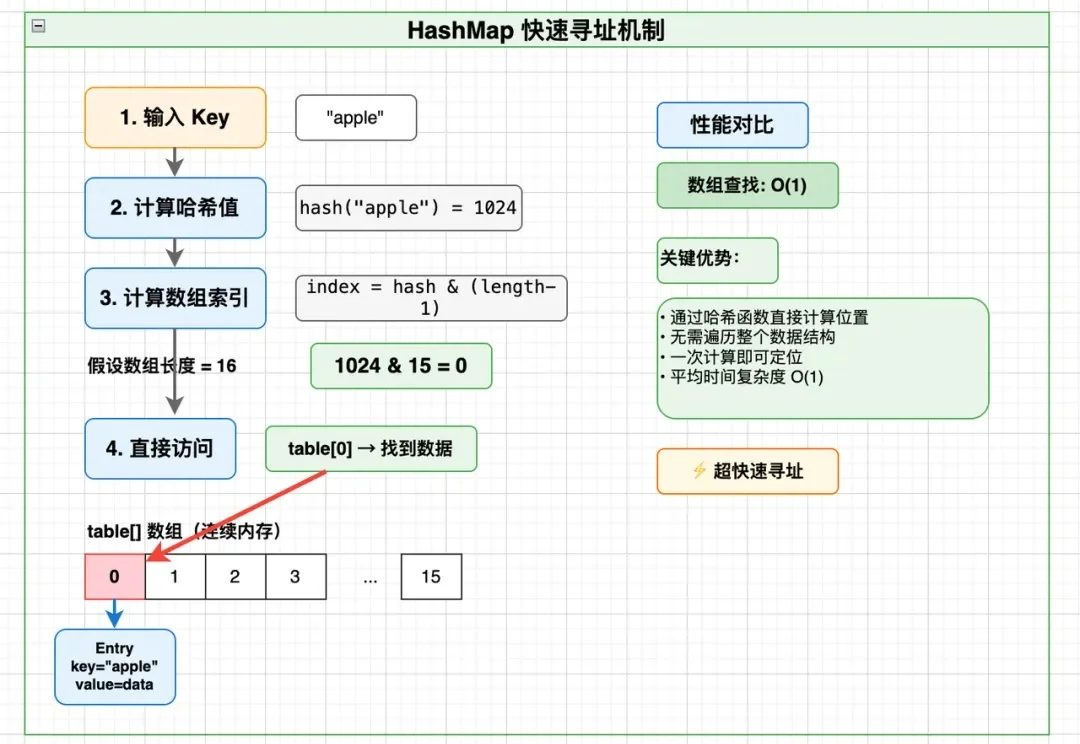
做后端、大数据、分布式存储的同学,大概率都遇到过这样的问题: