
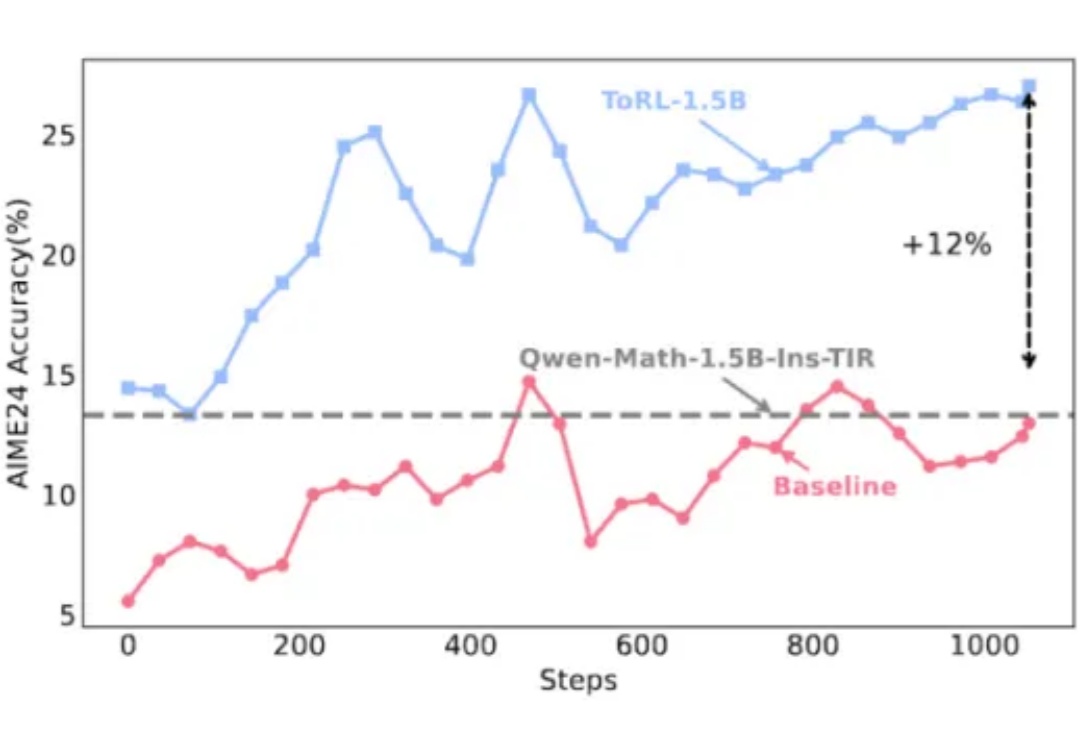
自动学会工具解题,RL扩展催化奥数能力激增17%
自动学会工具解题,RL扩展催化奥数能力激增17%在大模型推理能力提升的探索中,工具使用一直是克服语言模型计算局限性的关键路径。不过,当今的大模型在使用工具方面还存在一些局限,比如预先确定了工具的使用模式、限制了对最优策略的探索、实现透明度不足等。
来自主题: AI技术研报
10031 点击 2025-04-02 10:09
在大模型推理能力提升的探索中,工具使用一直是克服语言模型计算局限性的关键路径。不过,当今的大模型在使用工具方面还存在一些局限,比如预先确定了工具的使用模式、限制了对最优策略的探索、实现透明度不足等。

LLM正推动推荐系统革新,以用户表征为「软提示」的范式开辟了高效推荐新路径。在此趋势下,淘天团队发布了首个基于用户表征的个性化问答基准UQABench,系统评估了用户表征的提示效能。
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
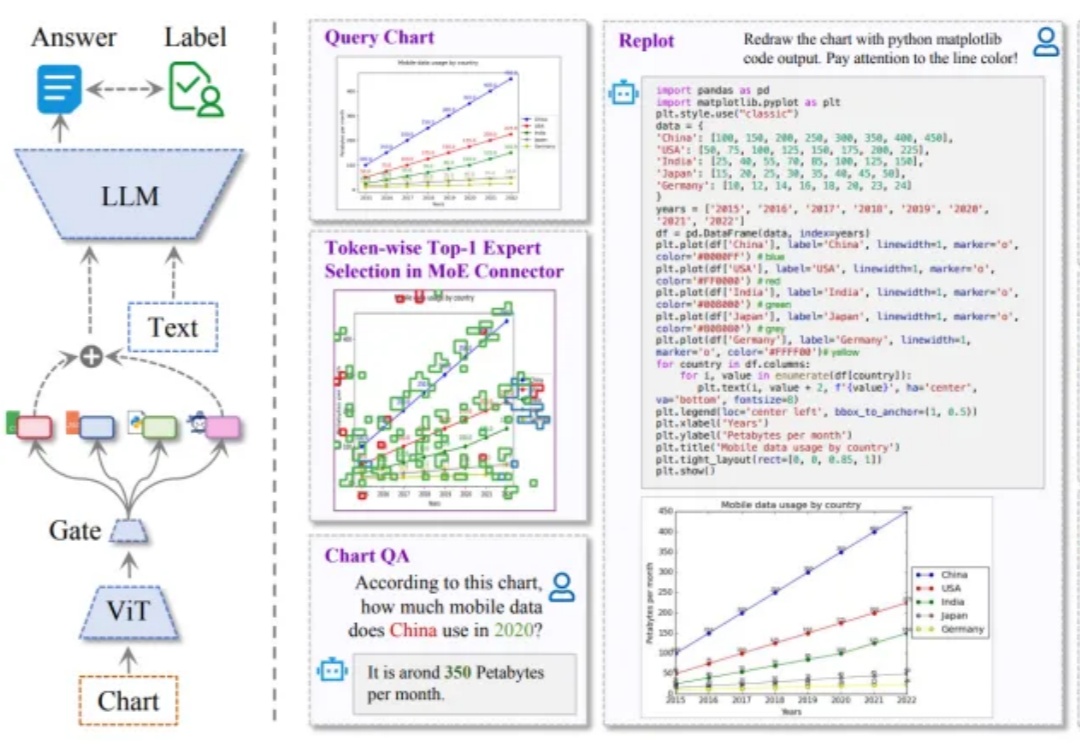
最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由 IDEA、清华大学、北京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文。据了解,本届大会共收到 11672 篇论文,被选中做 Oral Presentation(口头报告)的比例约为 1.8%

2025年,人工智能领域正在经历一场由LLM Agent引发的深刻变革,不管普通人的衣食住行还是研究者的尖端研究,都很难不受Agent的影响。

“创业公司不要浪费一分钱去训练底层模型”、“所有的应用都是套壳应用,关键是如何构建长期壁垒”。
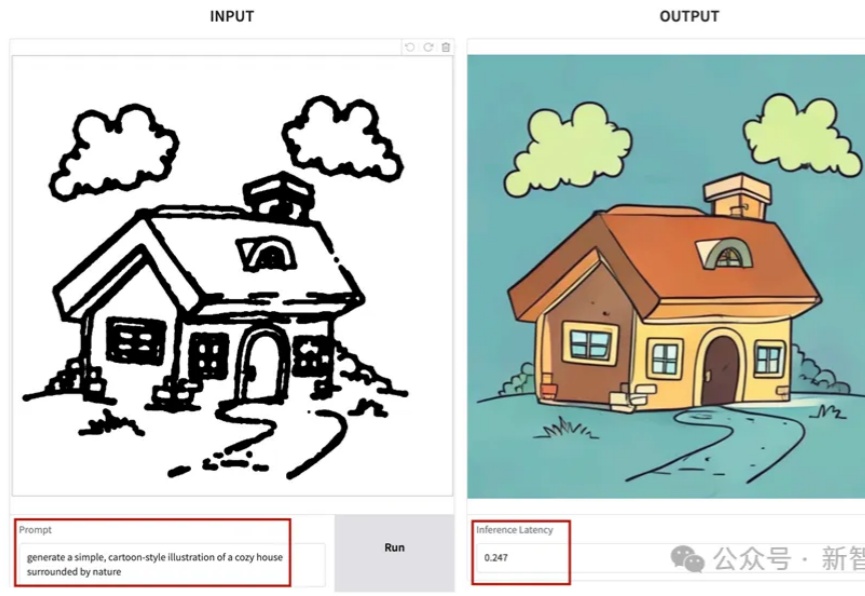
SANA-Sprint是一个高效的蒸馏扩散模型,专为超快速文本到图像生成而设计。通过结合连续时间一致性蒸馏(sCM)和潜空间对抗蒸馏(LADD)的混合蒸馏策略,SANA-Sprint在一步内实现了7.59 FID和0.74 GenEval的最先进性能。SANA-Sprint仅需0.1秒即可在H100上生成高质量的1024x1024图像,在速度和质量的权衡方面树立了新的标杆。
在三维数字内容生产领域,三角形网格作为核心的几何表示形式,其质量直接影响虚拟资产在影视、游戏和工业设计等应用场景中的表现与效率。
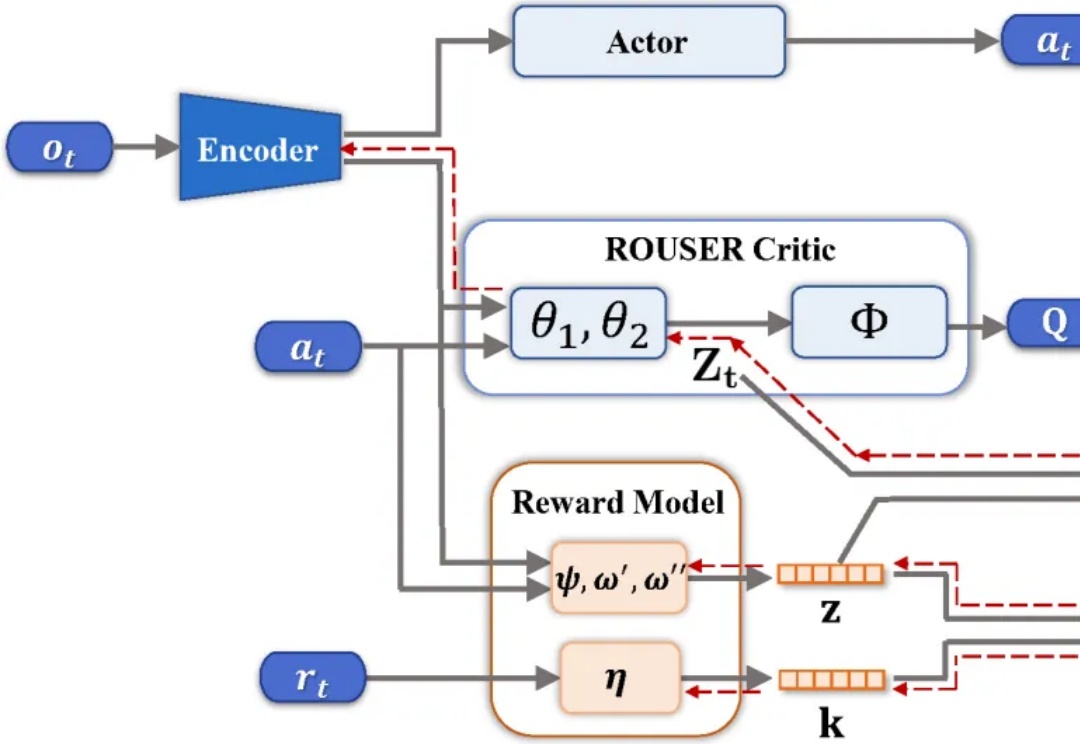
在视觉强化学习中,许多方法未考虑序列决策过程,导致所学表征缺乏关键的长期信息的空缺被填补上了。
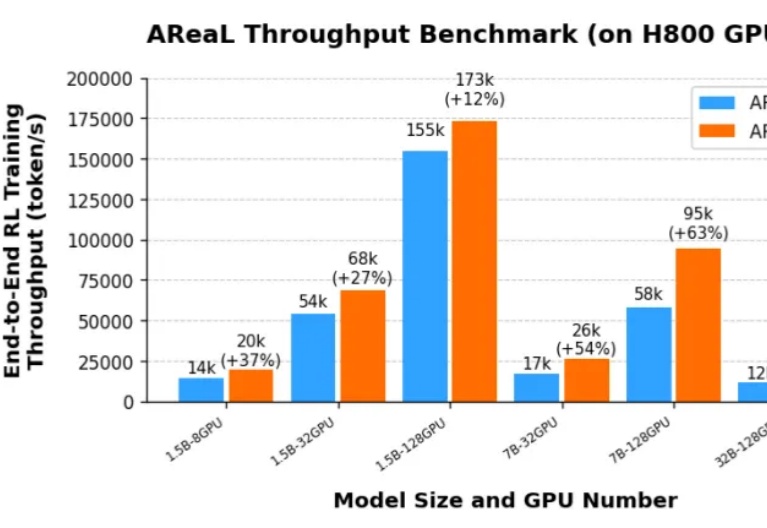
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高: