
视觉SSL终于追上了CLIP!Yann LeCun、谢赛宁等新作,逆转VQA任务固有认知
视觉SSL终于追上了CLIP!Yann LeCun、谢赛宁等新作,逆转VQA任务固有认知扩展无语言的视觉表征学习。
来自主题: AI技术研报
7805 点击 2025-04-03 15:06
扩展无语言的视觉表征学习。

当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。
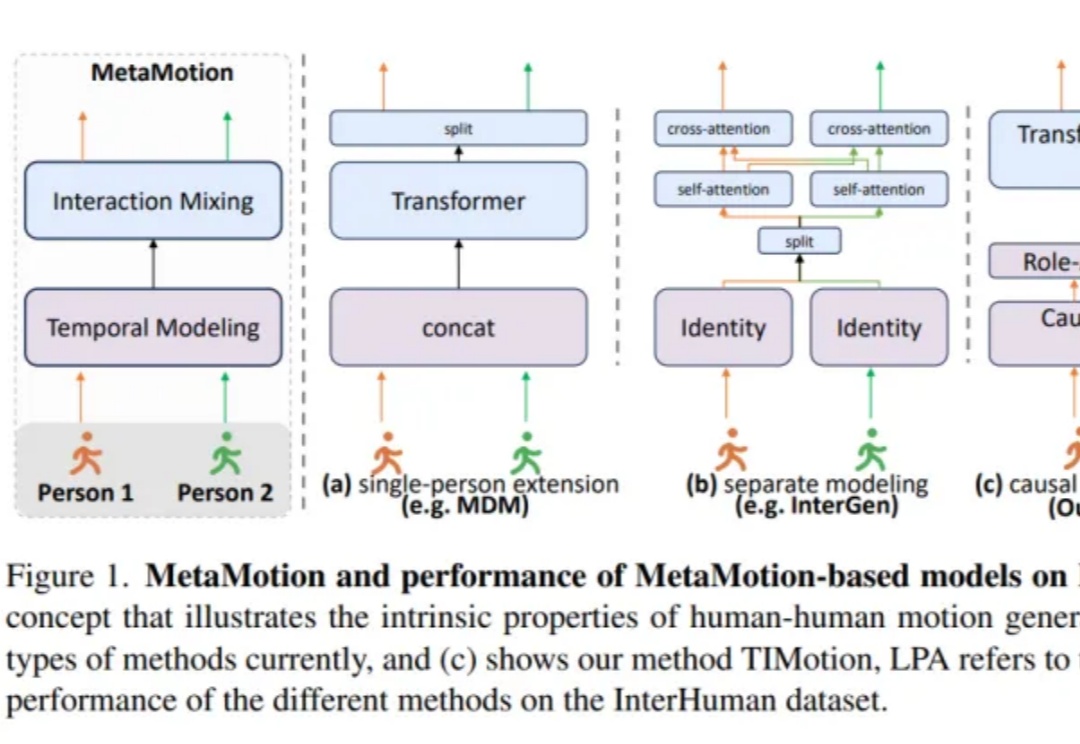
双人动作生成新SOTA!
如何从一张普通的单幅图像准确估计物体的三维法线和材质属性,是计算机视觉与图形学领域长期关注的难题。
一个7B奖励模型搞定全学科,大模型强化学习不止数学和代码。

“艺术家与人工智能”的张力正在持续紧张。OpenAI虽然声称避免复制“个别在世艺术家的风格”,但它一直在践行并推动政策允许AI对版权内容的训练;而小部分能够承担高昂诉讼成本的艺术家,却也因为版权法灰色地带而面临不确定的局面,更不要说那些不知名的艺术家们了。

4D LangSplat通过结合多模态大语言模型和动态三维高斯泼溅技术,成功构建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。该方法利用多模态大模型生成物体级的语言描述,并通过状态变化网络实现语义特征的平滑建模,显著提升了动态语义场的建模能力。
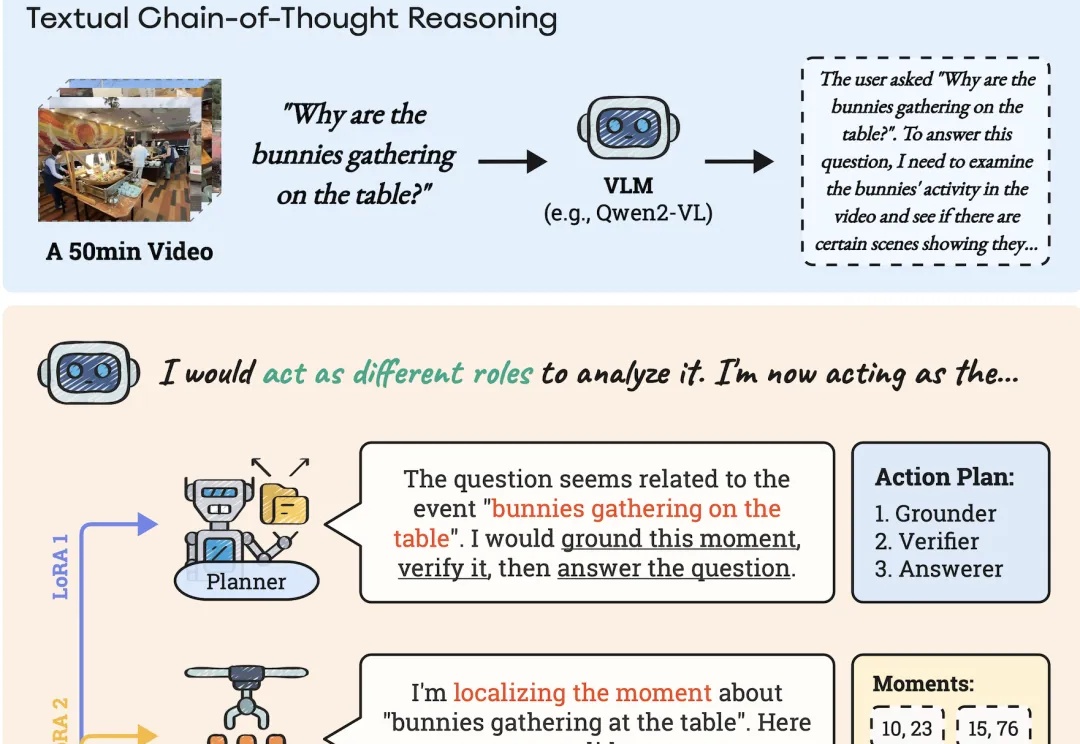
AI能像人类一样理解长视频。

在自动驾驶领域,高精度仿真系统扮演着 “虚拟练兵场” 的角色。工程师需要在数字世界中模拟暴雨、拥堵、突发事故等极端场景,反复验证算法的可靠性。

众所周知,DeepSeek R1 这种模型在推理任务上很能打,尤其是在数学和编程这些逻辑性强的领域。那么我们能直接把这种强大的推理能力搬到 DeepSearch 这种需要动态规划、多轮交互的深度搜索场景里吗?