
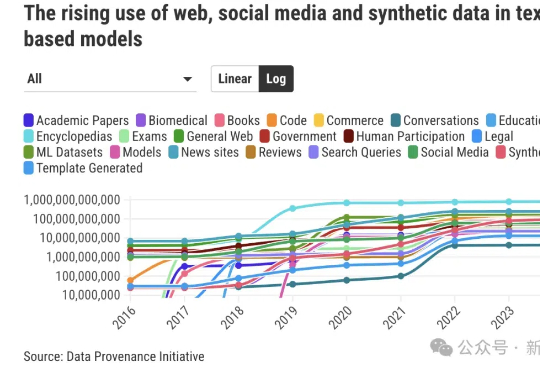
最新研究揭示AI数据之殇:科技巨头垄断权力,「西方中心」数据加剧模型偏见
最新研究揭示AI数据之殇:科技巨头垄断权力,「西方中心」数据加剧模型偏见相比LLM和Agent领域日新月异、高度成熟的进展相比,数据收集方面的规范有明显滞后。由超过50名研究人员组成的「数据溯源计划」(DPI)旨在回答这样一个问题:AI训练所需的数据究竟来自何处?
来自主题: AI技术研报
7663 点击 2025-01-30 13:00
相比LLM和Agent领域日新月异、高度成熟的进展相比,数据收集方面的规范有明显滞后。由超过50名研究人员组成的「数据溯源计划」(DPI)旨在回答这样一个问题:AI训练所需的数据究竟来自何处?

这个春节,国产AI引发全球轰动,一家叫做DeepSeek的初创科技公司发布了一款推理模型,不仅能力不输OpenAI的o1,训练成本也远低于国外,各行各业更是跟风尝试。1月27日,DeepSeek超过ChatGPT,成为苹果商店美国区免费应用榜单第一,也登顶中国区免费榜,由于用户突然涌入太多,还出现了短暂宕机。

基于一段文本提问时,人类和大模型会基于截然不同的思维模式给出问题。大模型喜欢那些需要详细解释才能回答的问题,而人类倾向于提出更直接、基于事实的问题。

「除了 Claude、豆包和 Gemini 之外,知名的闭源和开源 LLM 通常表现出很高的蒸馏度。」这是中国科学院深圳先进技术研究院、北大、零一万物等机构的研究者在一篇新论文中得出的结论。

VARGPT是一种新型多模态大模型,能够在单一框架内实现视觉理解和生成任务。通过预测下一个token完成视觉理解,预测下一个scale完成视觉生成,展现出强大的混合模态输入输出能力。
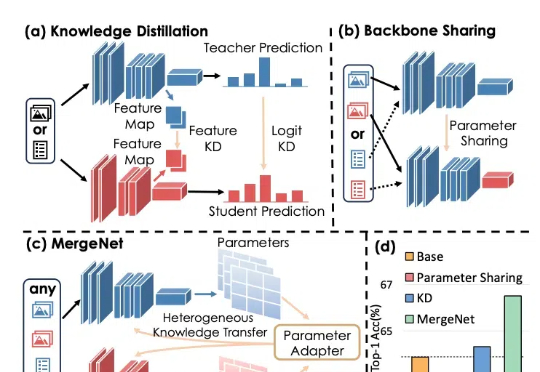
知识蒸馏通过训练一个紧凑的学生模型来模仿教师模型的 Logits 或 Feature Map,提高学生模型的准确性。迁移学习则通常通过预训练和微调,将预训练阶段在大规模数据集上学到的知识通过骨干网络共享应用于下游任务。

在美国发布AI禁令后,特朗普随即宣布了一项预算高达5000亿美元的AGI计划——星际之门,以保证其在AI领域的领先地位。而在大洋彼岸的中国,一家名为Deepseek的中国创业公司,只用了2048块显卡,就训练出了一个能与顶级模型相媲美的Deepseek-V3模型。

2028年,预计高质量数据将要耗尽,数据Scaling走向尽头。2025年,测试时计算将开始成为主导AI通向通用人工智能(AGI)的新一代Scaling Law。近日,CMU机器学习系博客发表新的技术文章,从元强化学习(meta RL)角度,详细解释了如何优化LLM测试时计算。

就在刚刚,网上已经出现了一波复现DeepSeek的狂潮。UC伯克利、港科大、HuggingFace等纷纷成功复现,只用强化学习,没有监督微调,30美元就能见证「啊哈时刻」!全球AI大模型,或许正在进入下一分水岭。
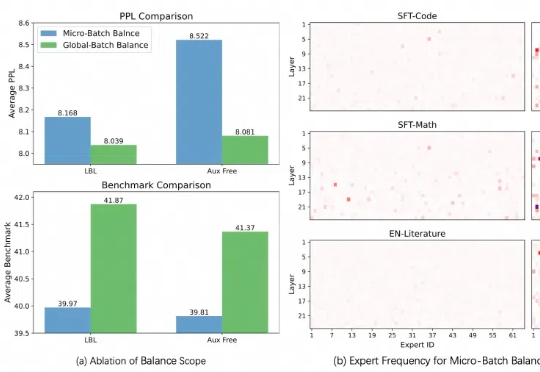
本周,在阿里云通义千问 Qwen 团队提交的一篇论文中,研究人员发现了目前最热门的 MoE(混合专家模型)训练中存在的一个普遍关键问题,并提出一种全新的方法——通过轻量的通信将局部均衡放松为全局均衡,使得 MoE 模型的性能和专家特异性都得到了显著的提升。