
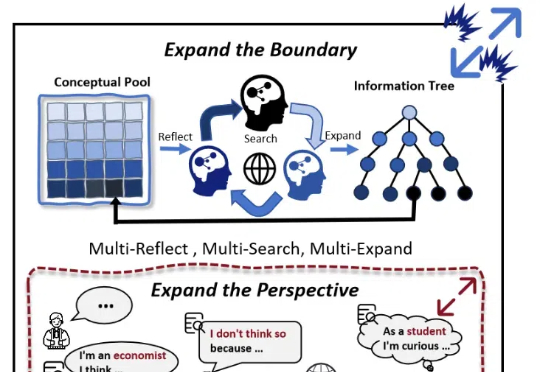
浙大通义联手推出慢思考长文本生成框架OmniThink,让AI写作突破知识边界
浙大通义联手推出慢思考长文本生成框架OmniThink,让AI写作突破知识边界随着大模型(LLMs)的发展,AI 写作取得了较大进展。然而,现有的方法大多依赖检索知识增强生成(RAG)和角色扮演等技术,其在信息的深度挖掘方面仍存在不足,较难突破已有知识边界,导致生成的内容缺乏深度和原创性。
来自主题: AI技术研报
9155 点击 2025-01-25 23:50
随着大模型(LLMs)的发展,AI 写作取得了较大进展。然而,现有的方法大多依赖检索知识增强生成(RAG)和角色扮演等技术,其在信息的深度挖掘方面仍存在不足,较难突破已有知识边界,导致生成的内容缺乏深度和原创性。

非营利研究机构AI2近日推出的完全开放模型OLMo 2,在同等大小模型中取得了最优性能,且该模型不止开放权重,还十分大方地公开了训练数据和方法。

瞄准推理时扩展(Inference-time scaling),DeepMind新的进化搜索策略火了! 所提出的“Mind Evolution”(思维进化),能够优化大语言模型(LLMs)在规划和推理中的响应。

OpenAI 在 “双十二” 发布会的最后一天公开了 o 系列背后的对齐方法 - deliberative alignment,展示了通过系统 2 的慢思考能力提升模型安全性的可行性。

新年第一天,陈天奇团队的FlashInfer论文出炉!块稀疏、可组合、可定制、负载均衡......更快的LLM推理技术细节全公开。

由无问芯穹与上海交通大学联合研究团队提出的视频生成软硬一体加速器,首次实现通过差分近似和自适应数据流解决 VDiT 生成速度缓慢瓶颈,推理速度相比 A100 提升高达 16.44 倍。
ChatGPT等聊天机器人背后的算法能从各种各样的网络文本中抓取万亿字节的素材,文本来源可以是网络文章,也可以是社媒平台的帖子,还可以是视频里的字幕或评论。

时隔不到一个月,DeepSeek又一次震动全球AI圈。去年 12 月,DeepSeek推出的DeepSeek-V3在全球AI领域掀起了巨大的波澜,它以极低的训练成本,实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能,震惊了业界。

刚刚发布的豆包大模型1.5,不仅多模态能力全面提升,霸榜多个基准;更难得的是,它在训练过程中从未使用过任何其他模型生成的数据,坚决不走蒸馏「捷径」。

研究者提出了FAST,一种高效的动作Tokenizer。通过结合离散余弦变换(DCT)和字节对编码(BPE),FAST显著缩短了训练时间,并且能高效地学习和执行复杂任务,标志着机器人自回归Transformer训练的一个重要突破。