
让Agent记住一切是愚蠢的:SimpleMem用「结构化语义压缩」登顶记忆SOTA
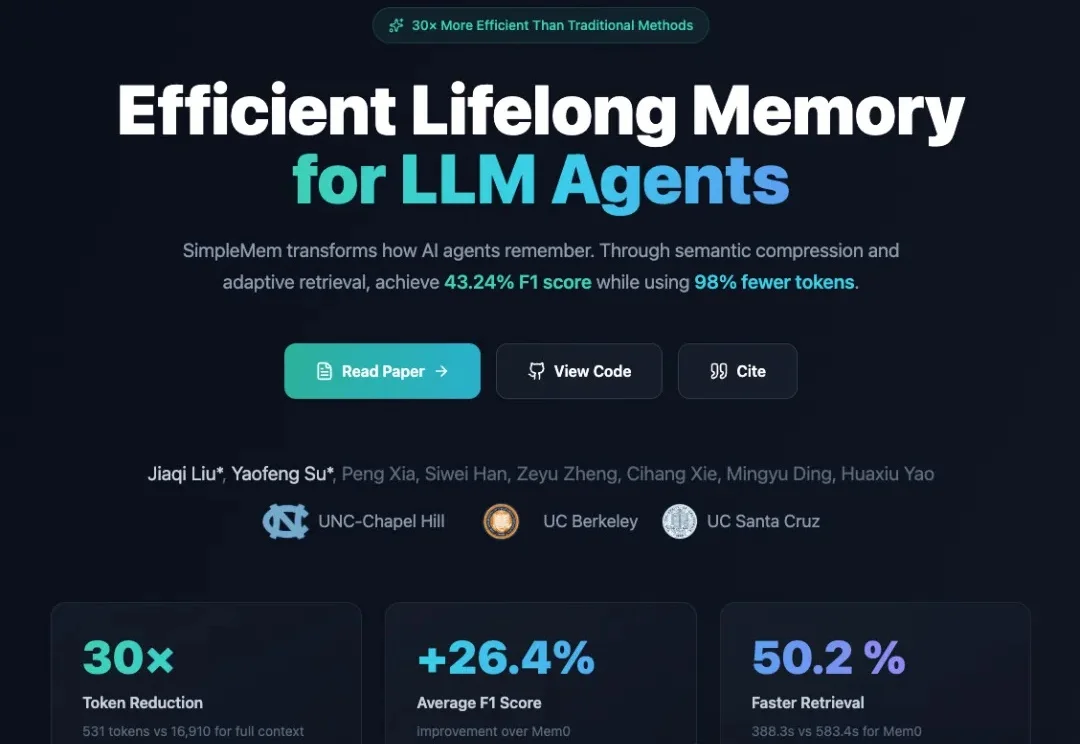
让Agent记住一切是愚蠢的:SimpleMem用「结构化语义压缩」登顶记忆SOTA如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。
来自主题: AI技术研报
8835 点击 2026-01-15 09:22
如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。
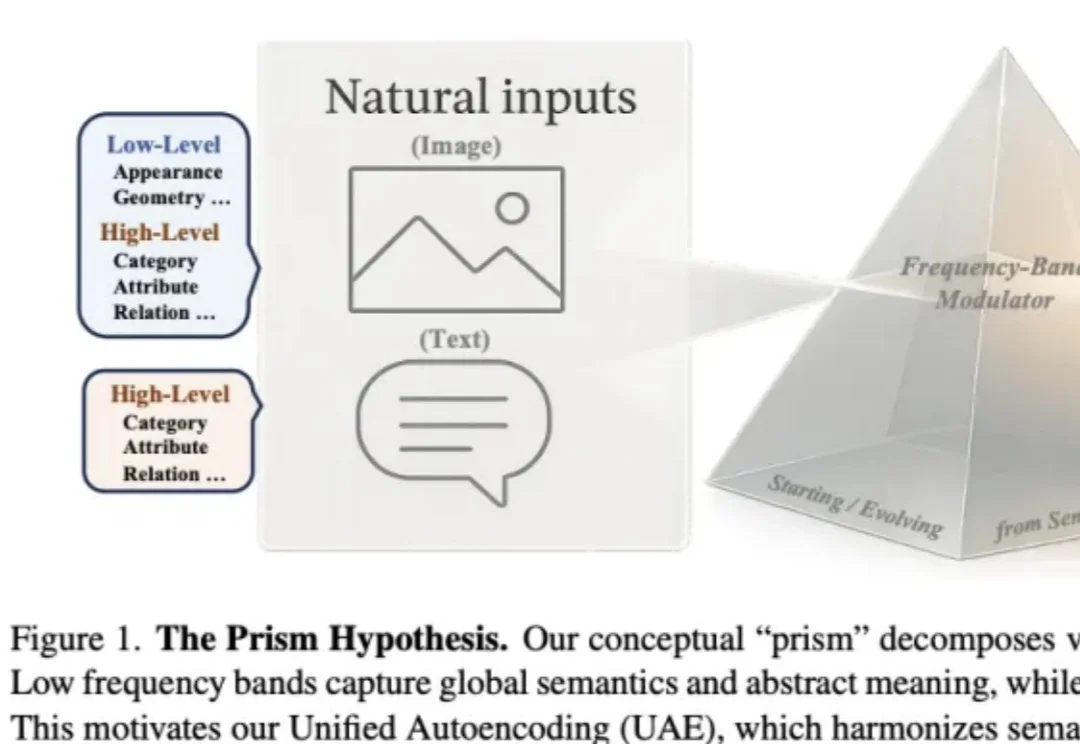
作者来自 Nanyang Technological University(MMLab) 与 SenseTime Research,提出 Prism Hypothesis(棱镜假说) 与 Unified Autoencoding(UAE),尝试用 “频率谱” 的统一视角,把语义编码器与像素编码器的表示冲突真正 “合并解决”。
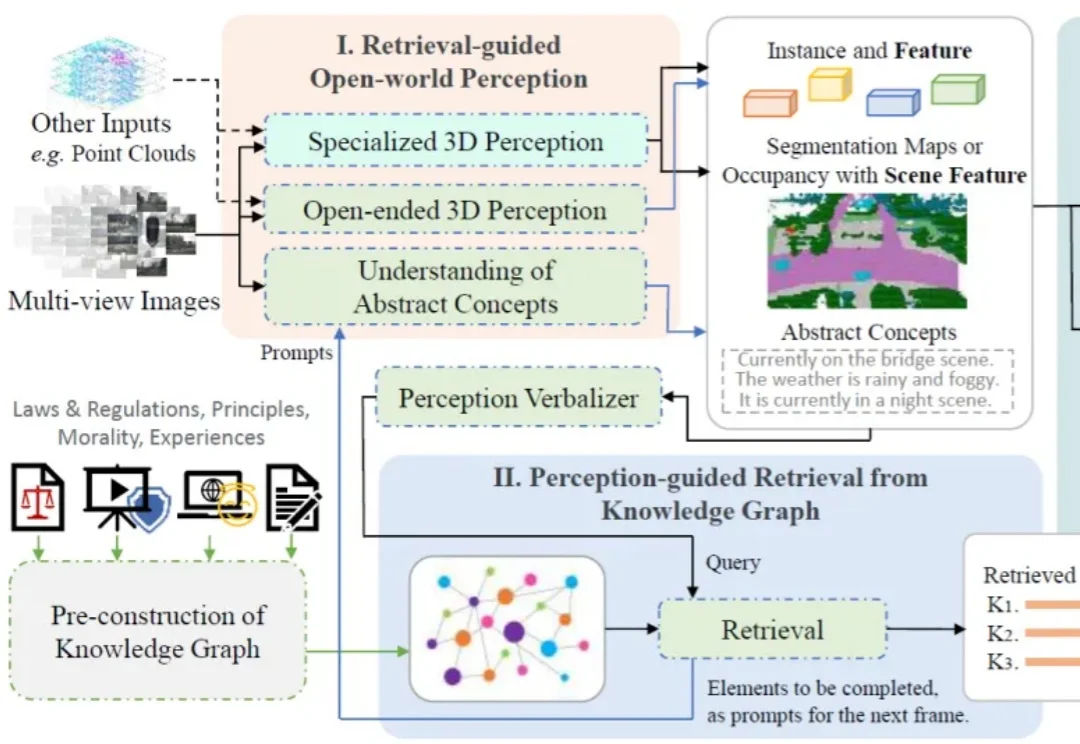
一个智能驾驶系统,在迈向高阶自动驾驶的过程中,应当具备何种能力?除了基础的感知、预测、规划、决策能力,如何对三维空间进行更深入的理解?如何具备包含法律法规、道德原则、防御性驾驶原则等知识?如何进行基本的视觉 - 语言推理?如何让智能系统具备世界观和价值观?
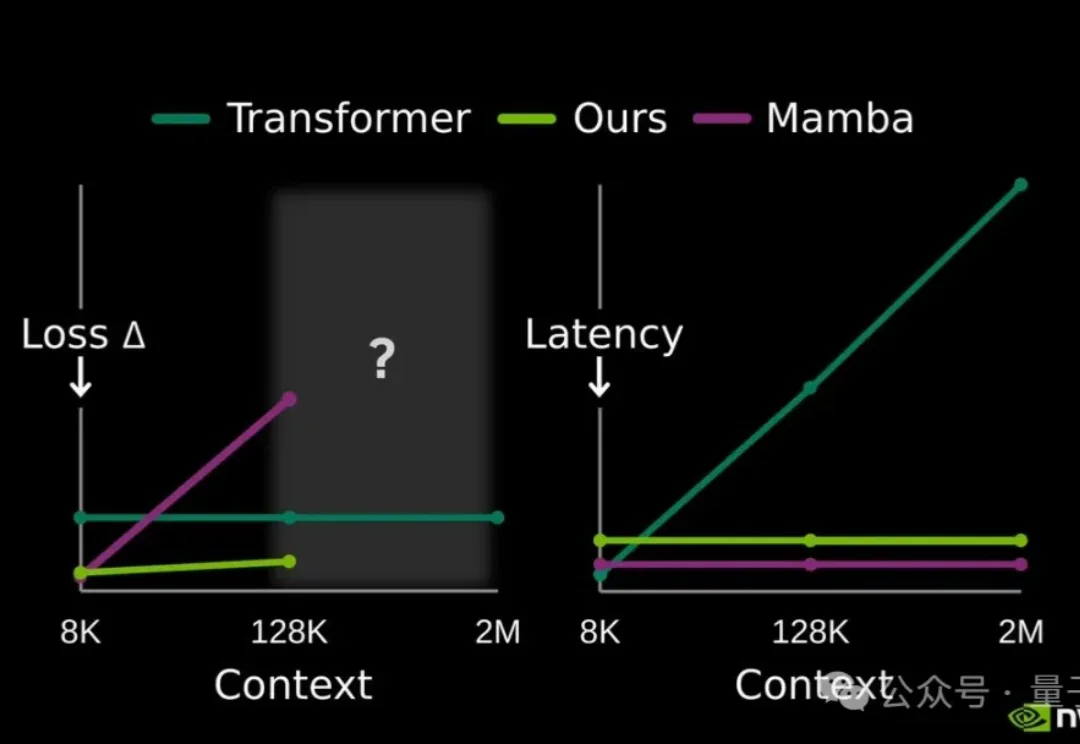
提高大模型记忆这块儿,美国大模型开源王者——英伟达也出招了。
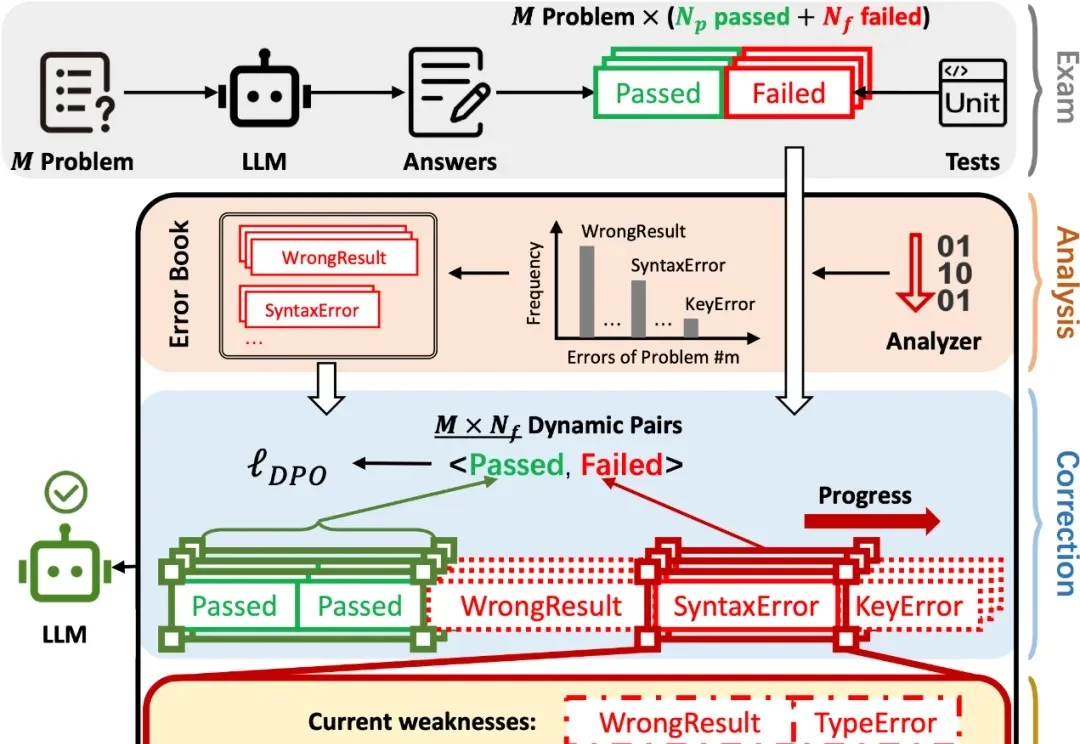
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。
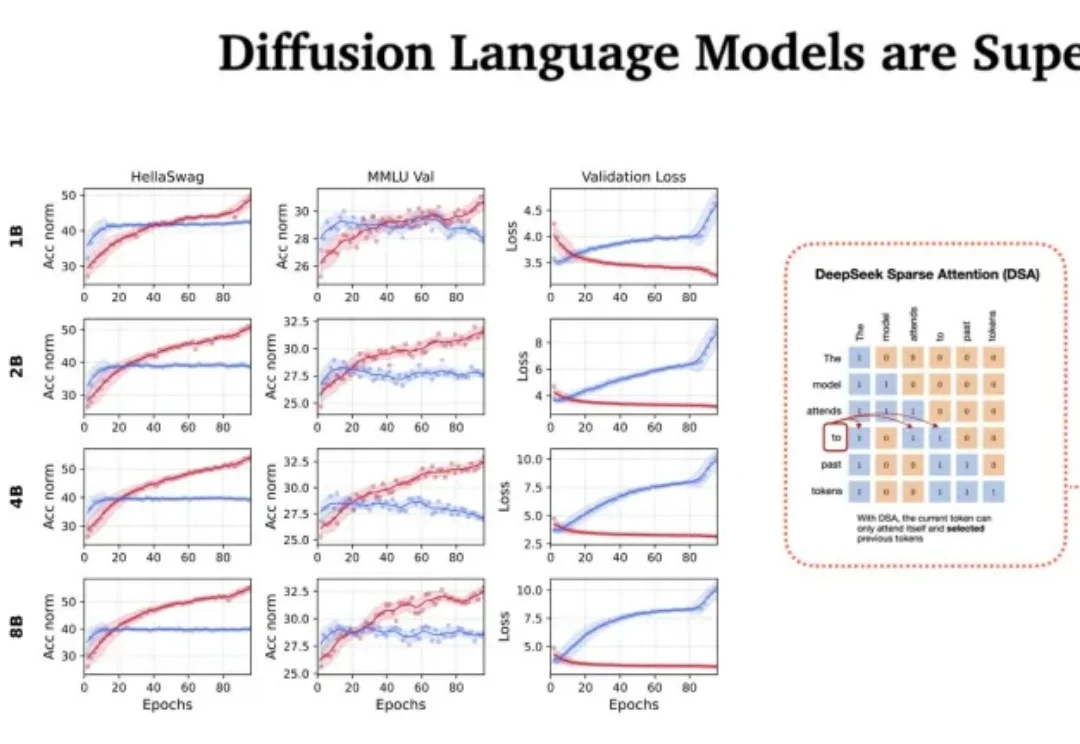
站在 2026 年的开端回望,LLM 的架构之争似乎进入了一个新的微妙阶段。过去几年,Transformer 架构以绝对的统治力横扫了人工智能领域,但随着算力成本的博弈和对推理效率的极致追求,挑战者们从未停止过脚步。
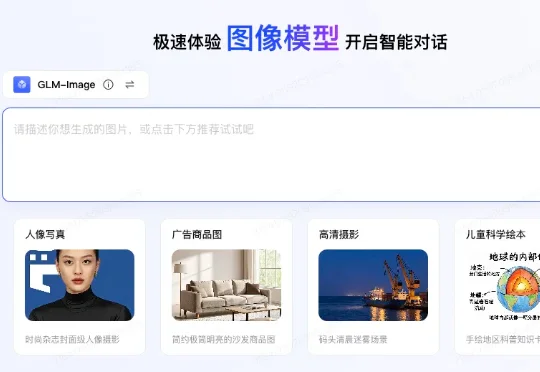
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。
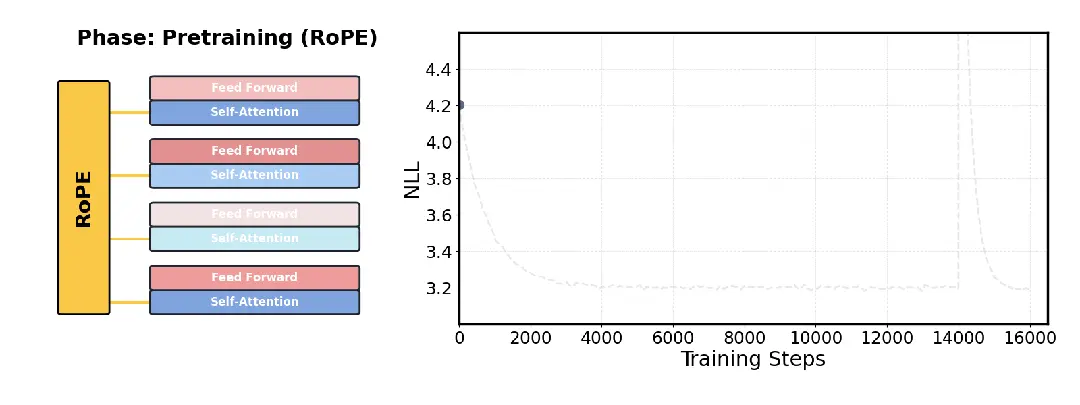
针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。
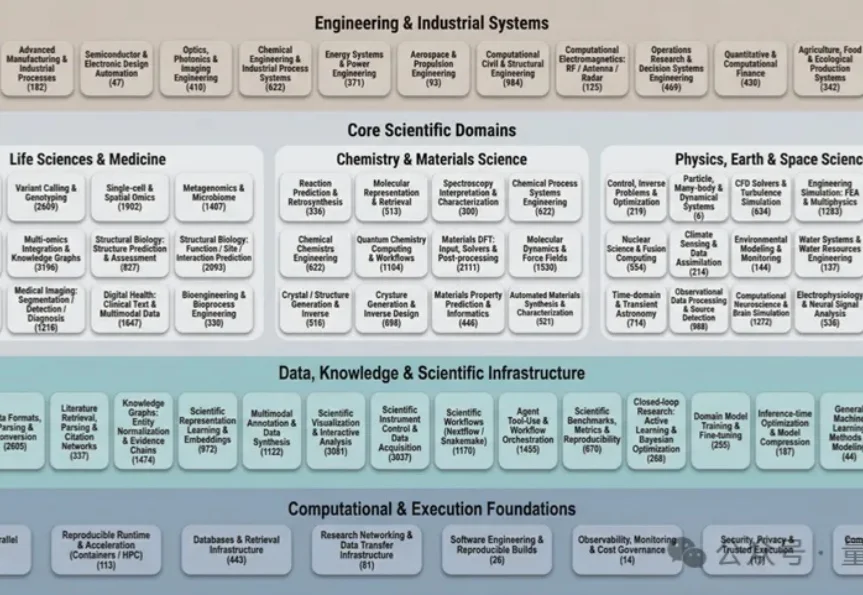
过去几十年里,科学计算领域积累了数量空前的开源软件工具。

假如你是一个致力于将 AI 引入传统行业的工程团队。现在,你有一个问题:训练一个能看懂复杂机械图纸、设备维护手册或金融研报图表的多模态助手。这个助手不仅要能专业陪聊,更要能精准地识别图纸上的零件标注,或者从密密麻麻的财报截图中提取关键数据。