

国产之光DeepSeek把AI大佬全炸出来了!671B大模型训练只需此前算力1/10,细节全公开
国产之光DeepSeek把AI大佬全炸出来了!671B大模型训练只需此前算力1/10,细节全公开DeepSeek新版模型正式发布,技术大佬们都转疯了! 延续便宜大碗特点的基础之上,DeepSeek V3发布即完全开源,直接用了53页论文把训练细节和盘托出的那种。
来自主题: AI技术研报
8039 点击 2024-12-28 11:19
DeepSeek新版模型正式发布,技术大佬们都转疯了! 延续便宜大碗特点的基础之上,DeepSeek V3发布即完全开源,直接用了53页论文把训练细节和盘托出的那种。
就在OpenAI热闹的12天发布会刚刚落下帷幕,谷歌的火力全开新模型Voe2和Gemnini2吸引了全球AI开发者的眼球时,Meta作为三巨头之一则在筹划着一场静悄悄的革命。
1822 年,电学之父法拉第在日记中写到“既然通电能够产生磁力,为什么不能用磁铁产生电流呢?我一定要反过来试试!”。于是在 1831 年,第一台发电机被发明,推动了人类进入电气化时代。

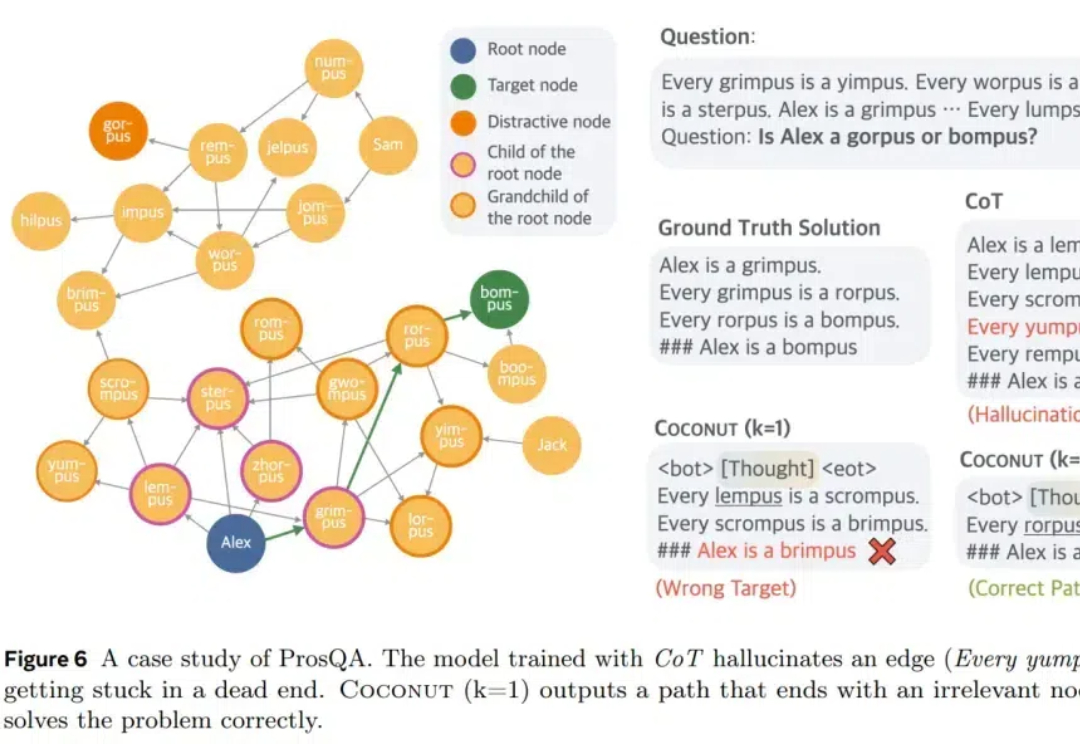
最近,类 o1 模型的出现,验证了长思维链 (CoT) 在数学和编码等推理任务中的有效性。在长思考(long thought)的帮助下,LLM 倾向于探索、反思和自我改进推理过程,以获得更准确的答案。
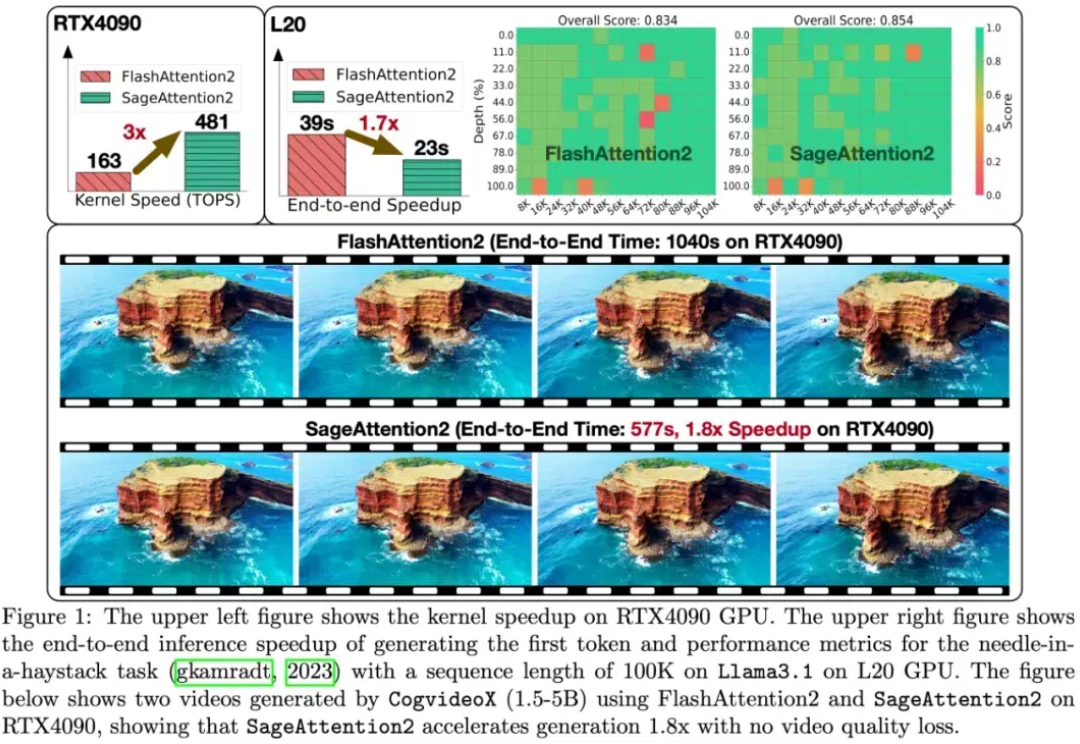
大模型中,线性层的低比特量化已经逐步落地。然而,对于注意力模块,目前几乎各个模型都还在用高精度(例如 FP16 或 FP32)的注意力运算进行训练和推理。并且,随着大型模型需要处理的序列长度不断增加,Attention(注意力运算)的时间开销逐渐成为主要开销。
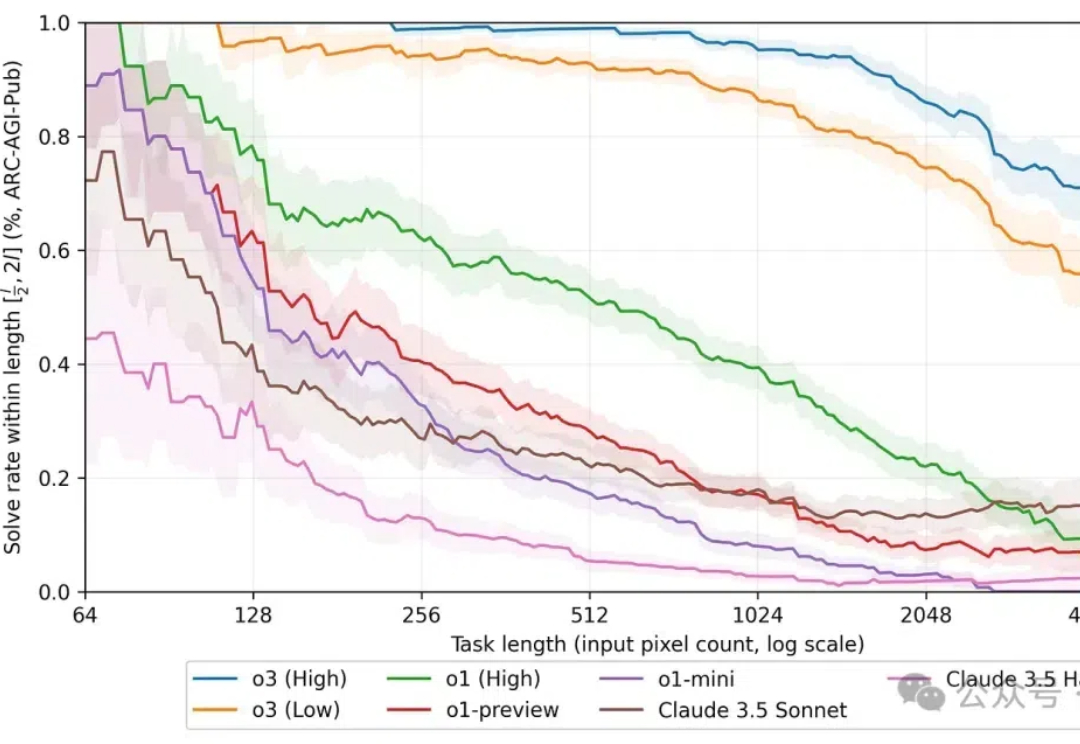
o3在超难推理任务ARC-AGI上的成绩,属实给人类带来了不少震撼。 但有人专门研究了它不会做的题之后,有了更有趣的发现—— o3之所以不会做这些题,原因可能不是因为太难,而是题目的规模太大了。
无需额外模型训练、即插即用,全新的视频生成增强算法——Enhance-A-Video来了!

语言模型的发展已很难有大的突破了。
两年前,ChatGPT横空出世,掀起一场超强的“AI旋风”;最近,OpenAI用连续12天的发布会再次让全球进入“AI狂欢”。但不同于两年前的震惊、兴奋与困惑,今天的学界和产业界对于AGI路线有了更多的“中国思考”。
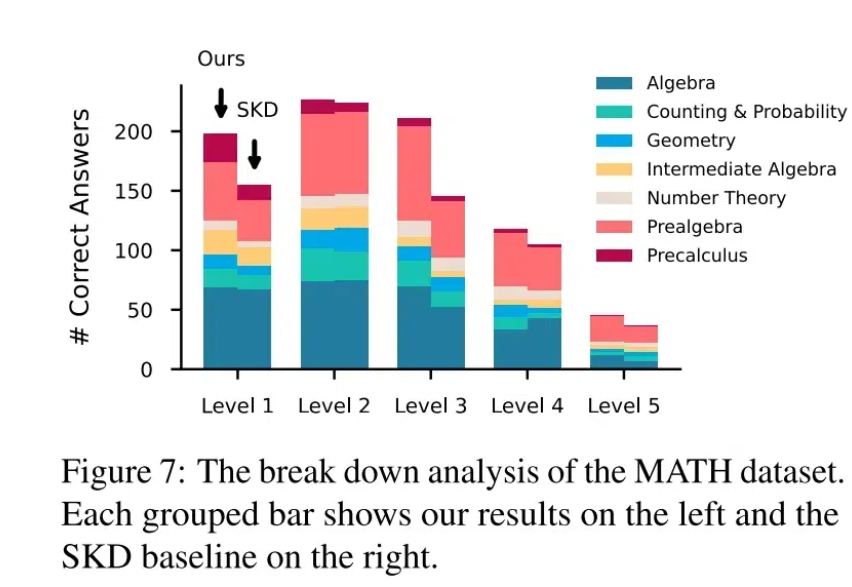
AI缺乏情商,需设计训练数据提高社交认知能力。 当你觉得AI不够好用时,很可能是因为它还不够“懂”你。