
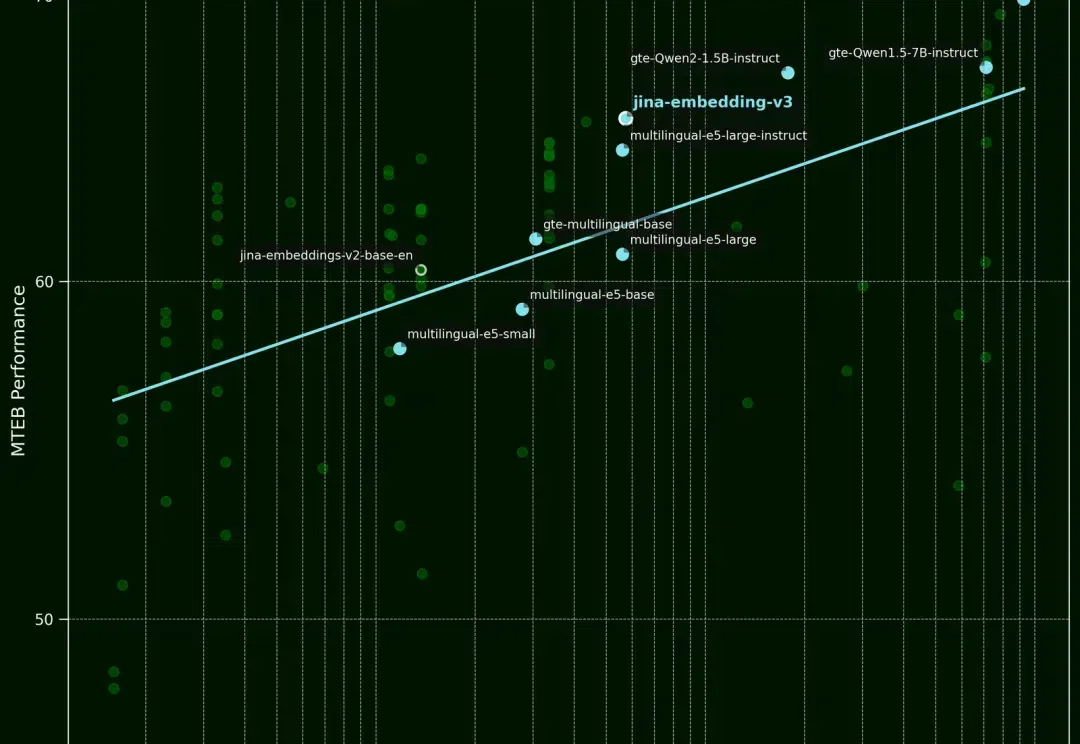
向量模型的词序感知缺陷与优化策略
向量模型的词序感知缺陷与优化策略最近,LAION AI 的创始人 Christoph Schuhmann 分享了一个有趣的发现,他指出,文本向量模型似乎存在一个问题:即使句子词序被打乱,模型输出的向量与原句仍然高度相似。
来自主题: AI技术研报
9325 点击 2024-12-29 11:16
最近,LAION AI 的创始人 Christoph Schuhmann 分享了一个有趣的发现,他指出,文本向量模型似乎存在一个问题:即使句子词序被打乱,模型输出的向量与原句仍然高度相似。

一个来自中国的开源模型,让整个AI圈再次惊呼“来自东方的神秘力量”。 昨天,国内知名大模型创业公司“深度求索”通过官方公众号宣布上线并同步开源 DeepSeek-V3模型,并公布了长达53页的训练和技术细节。
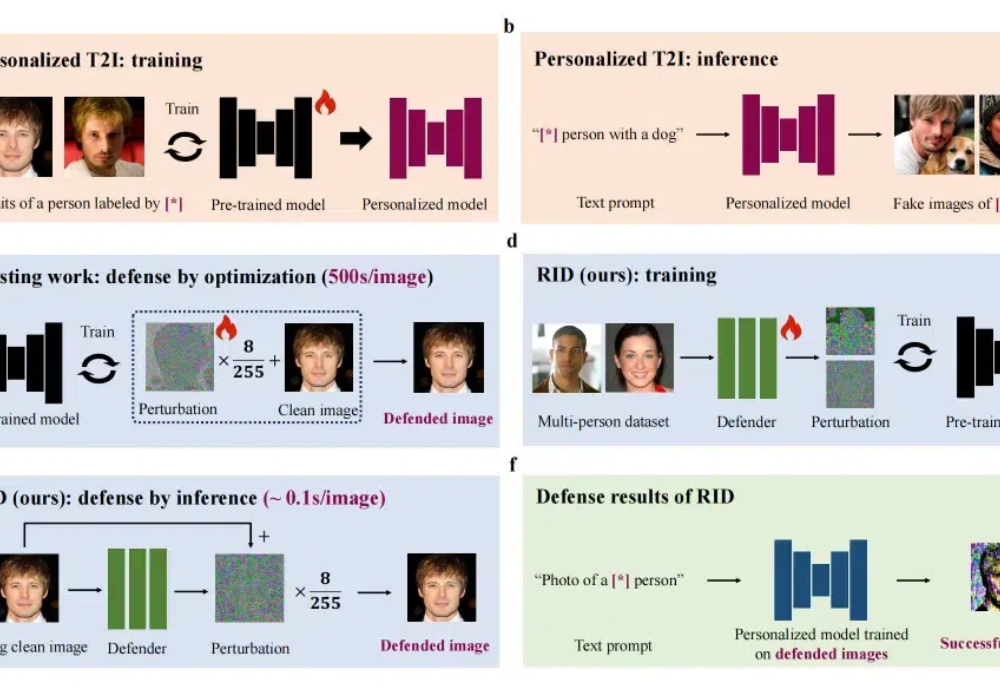
近年来许多论文研究了基于扩散模型的定制化生成,即通过给定一张或几张某个概念的图片,通过定制化学习让模型记住这个概念,并能够生成这个概念的新视角、新场景图片。

超越ControlNet++,让文生图更可控的新框架来了!

本月,OpenAI科学家就当前LLM的scaling方法论能否实现AGI话题展开深入辩论,认为将来AI至少与人类平分秋色;LLM scaling目前的问题可以通过后训练、强化学习、合成数据、智能体协作等方法得到解决;按现在的趋势估计,明年LLM就能赢得IMO金牌。

Orr Zohar的指导老师Serena Yeung-Levy教授于2018年获得斯坦福大学博士学位,师从李飞飞和Arnold Milstein。2017年至2019年期间,Serena Yeung-Levy曾与Justin Johnson和李飞飞共同教授斯坦福大学卷积神经网络课程。

一个全新的模型能力衡量指标诞生了?!
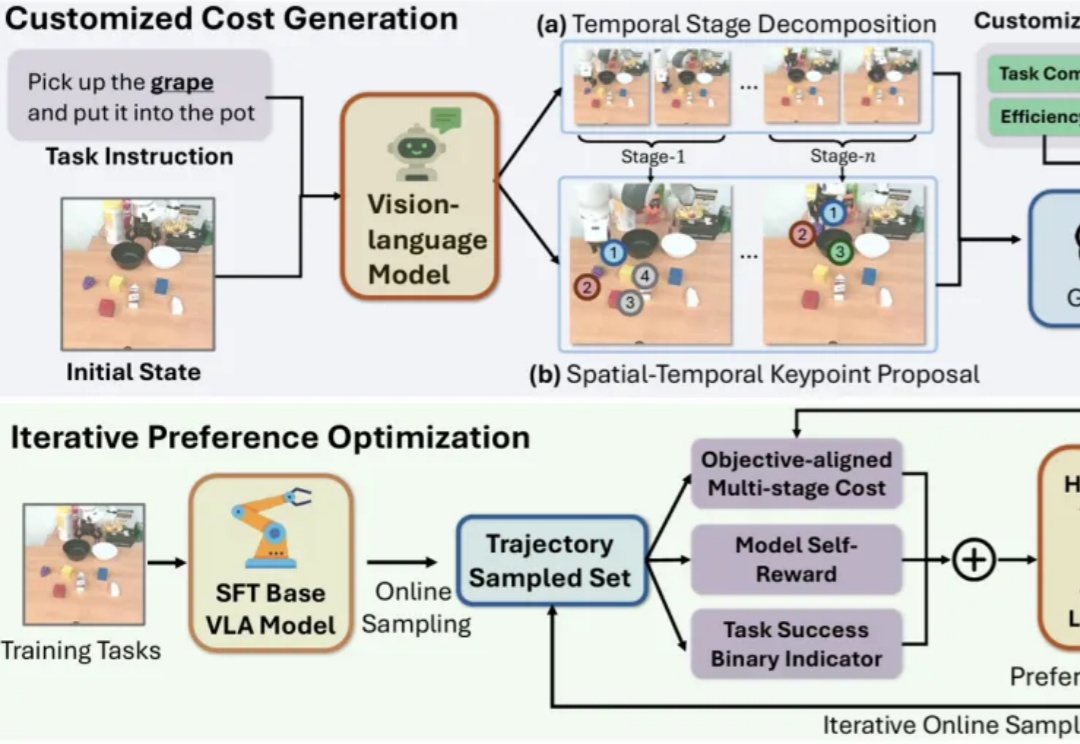
近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)在诸多机器人任务上取得了显著的进展,但它们仍面临一些关键问题,例如由于仅依赖从成功的执行轨迹中进行行为克隆,导致对新任务的泛化能力较差。
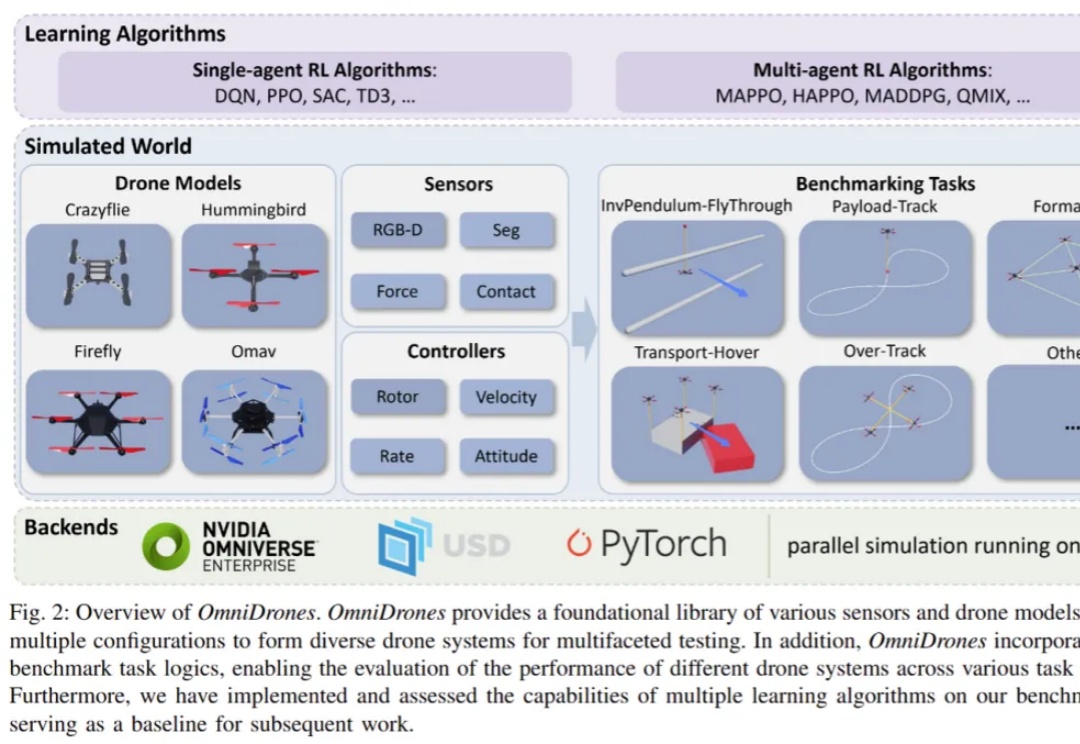
控制无人机执行敏捷、高机动性的行为是一项颇具挑战的任务。传统的控制方法,比如 PID 控制器和模型预测控制(MPC),在灵活性和效果上往往有所局限。而近年来,强化学习(RL)在机器人控制领域展现出了巨大的潜力。通过直接将观测映射为动作,强化学习能够减少对系统动力学模型的依赖。
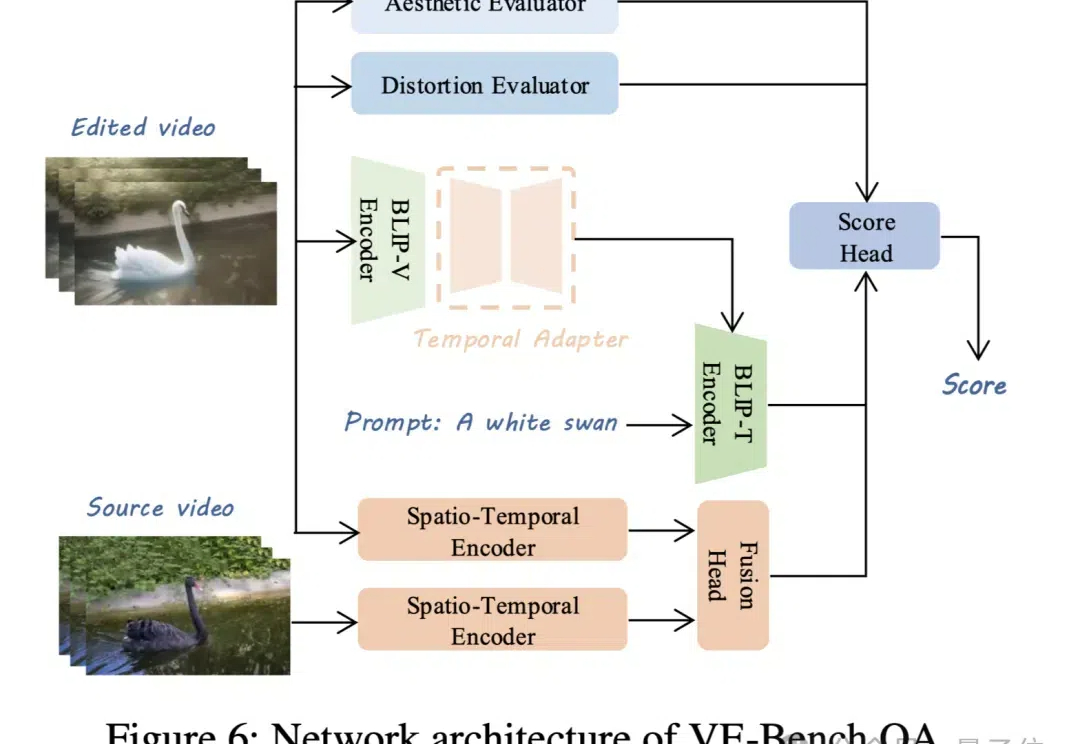
视频生成模型卷得热火朝天,配套的视频评价标准自然也不能落后。 现在,北京大学MMCAL团队开发了首个用于视频编辑质量评估的新指标——VE-Bench,相关代码与预训练权重均已开源。