
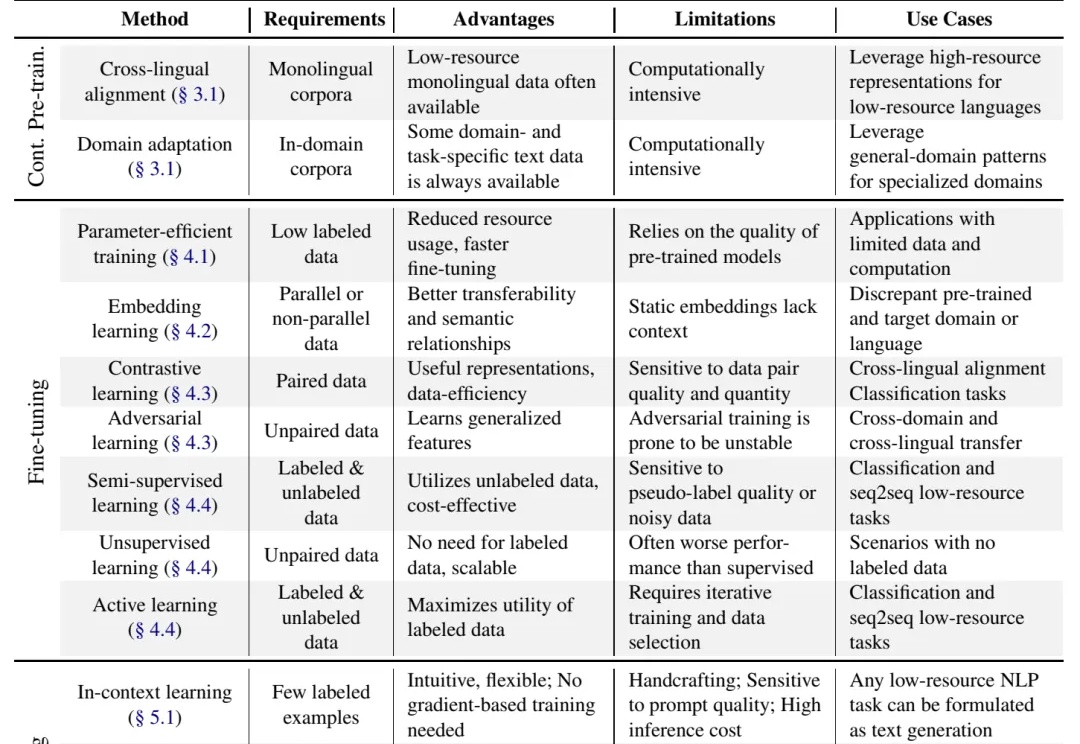
缺钱缺数据时的大模型微调方法汇总
缺钱缺数据时的大模型微调方法汇总别说什么“没数据就去标注啊,没钱标注就别做大模型啊”这种风凉话,有些人数据不足也能做大模型,是因为有野心,就能想出来稀缺数据场景下的大模型解决方案,或者整理出本文将要介绍的 "Practical Guide to Fine-tuning with Limited Data" 这样的综述。
来自主题: AI资讯
11127 点击 2024-12-09 09:30
别说什么“没数据就去标注啊,没钱标注就别做大模型啊”这种风凉话,有些人数据不足也能做大模型,是因为有野心,就能想出来稀缺数据场景下的大模型解决方案,或者整理出本文将要介绍的 "Practical Guide to Fine-tuning with Limited Data" 这样的综述。

2024 年 12 月 6 号加州时间上午 11 点,OpenAI 发布了新的 Reinforcement Finetuning 方法,用于构造专家模型。对于特定领域的决策问题,比如医疗诊断、罕见病诊断等等,只需要上传几十到几千条训练案例,就可以通过微调来找到最有的决策。

OpenAI“双12”刚进行到第二天,就把大模型圈搅得好不热闹! 一边是Meta没预告就发布了Llama 3.3,70B版本就能实现以前405B的性能。
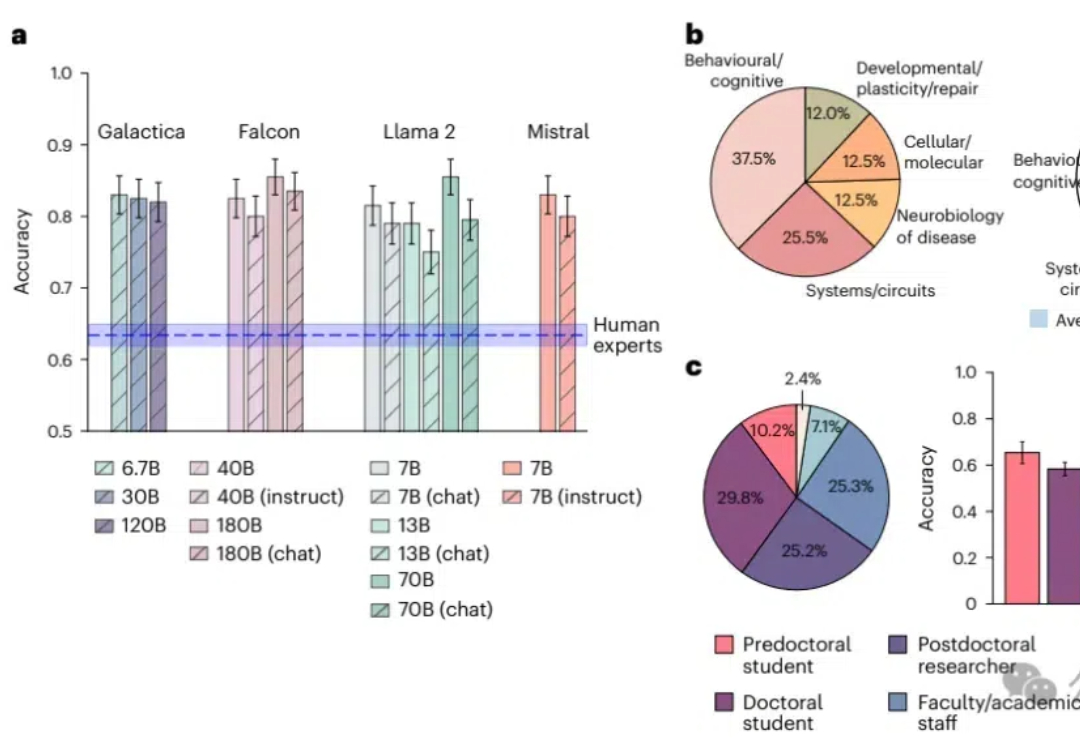
知识密集型工作也败了!大型语言模型在预测神经科学结果方面超越了人类专家,平均准确率达到81%,而人类专家仅为63%;模型通过整合大量文献数据,展现出了惊人的前瞻性预测能力,预示着未来科研工作中人机协作的巨大潜力。

在人工智能发展史上,强化学习 (RL) 凭借其严谨的数学框架解决了众多复杂的决策问题,从围棋、国际象棋到机器人控制等领域都取得了突破性进展。
人类离AGI究竟还有多远?最新一期Nature文章,从以往研究分析、多位大佬言论深入探讨了LLM在智能化道路上突破与局限。

以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。

强化微调可以轻松创建具备强大推理能力的专家模型。

近两年来,AI技术取得了重大发展。与此同时,对于使用版权内容进行AI模型训练争议不断,各国也都在积极探索适合自身的规制框架。

OpenAI“双12”直播第二天,依旧简短精悍,主题:新功能强化微调(Reinforcement Fine-Tuning),使用极少训练数据即在特定领域轻松地创建专家模型。少到什么程度呢?最低几十个例子就可以。