

OpenAI 12连发第2弹:强化微调,少量样本就能训练自己的专家模型
OpenAI 12连发第2弹:强化微调,少量样本就能训练自己的专家模型强化微调可以轻松创建具备强大推理能力的专家模型。
来自主题: AI技术研报
8939 点击 2024-12-07 11:46
强化微调可以轻松创建具备强大推理能力的专家模型。

近两年来,AI技术取得了重大发展。与此同时,对于使用版权内容进行AI模型训练争议不断,各国也都在积极探索适合自身的规制框架。

OpenAI“双12”直播第二天,依旧简短精悍,主题:新功能强化微调(Reinforcement Fine-Tuning),使用极少训练数据即在特定领域轻松地创建专家模型。少到什么程度呢?最低几十个例子就可以。
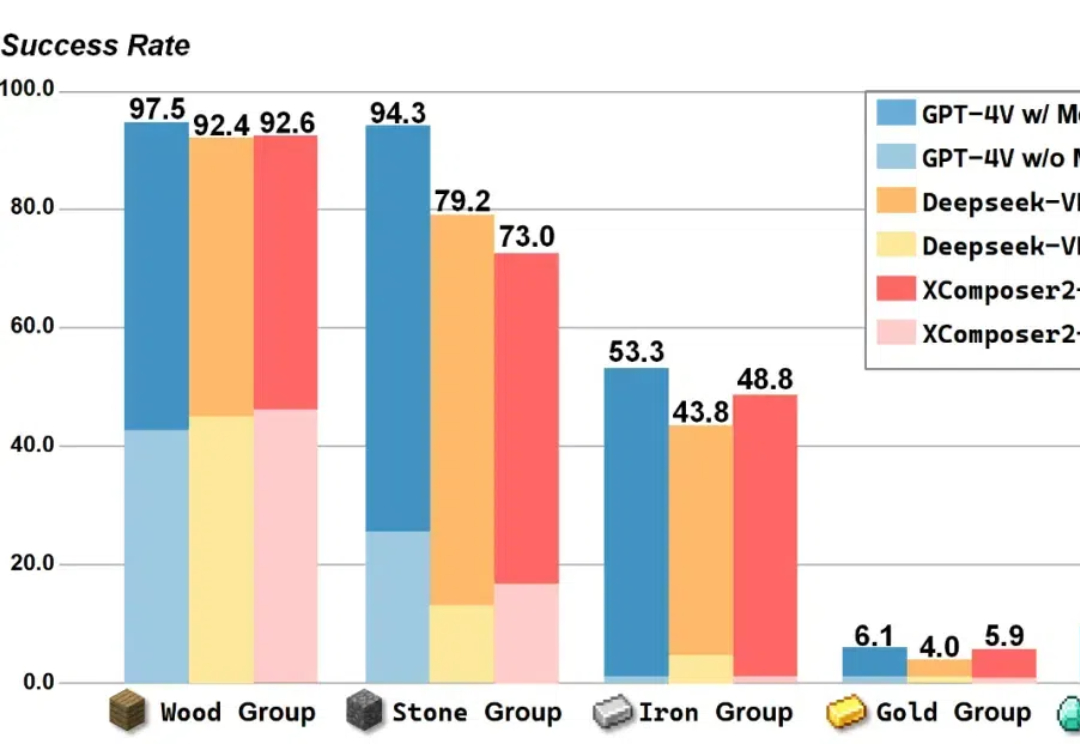
在 Minecraft 中构造一个能完成各种长序列任务的智能体,颇有挑战性。现有的工作利用大语言模型 / 多模态大模型生成行动规划,以提升智能体执行长序列任务的能力。

目前,这一领域发展迅速,但现有综述多聚焦于单智能体的架构、特定能力或多智能体系统的某些方面,尚缺乏从个体到社会模拟的系统性回顾。因此,本文试图填补这一空白,为该领域提供全面的概述。
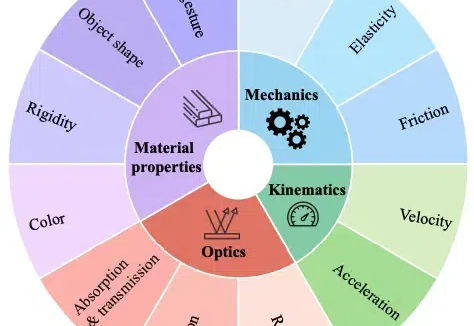
融合物理知识的大型视频语言模型PhysVLM,开源了! 它不仅在 PhysGame 基准上展现出最先进的性能,还在通用视频理解基准上(Video-MME, VCG)表现出领先的性能。

随着“AI妖股”Applovin股价暴涨790%,市值超过1000亿美金,国内大厂正加速发力生成式 AI 营销广告领域。

在AI迅速发展的技术背景下,如何更高效地利用模型资源成为了一个关键问题。批处理提示(Batch Prompting)作为一种同时处理多个相似查询的技术,虽然在提高计算效率方面显示出巨大潜力,但同时也面临着性能下降的挑战。香港理工大学的研究团队提出的Auto-Demo提示技术,为这一问题带来了突破性的解决方案。

今天,LiblibAI与千万用户一起揭幕我们的自研图像大模型。 Star-3 Alpha 图像基座模型来了。Star-3 Alpha大模型,基于业界领先的F.1基础算法架构训练而成。 相较于以往的所有模型,Star-3 Alpha在生图效果上实现了显著的飞跃,在图像精准度、色彩表现力、美学捕捉的细腻表达等方面成为新的业界标杆。
Yoshua Bengio最近在《金融时报》的专栏文章中表示,「AI可以在说话之前学会思考」,实现内部的深思熟虑将成为AGI道路的里程碑。无独有偶,就在几个月前,Yann LeCun也多次表达过类似的观点。