

李开复回应放弃预训练:训一次大模型三四百万美元,头部公司都付得起|最前线
李开复回应放弃预训练:训一次大模型三四百万美元,头部公司都付得起|最前线零一万物的最新模型,打榜赢了GPT-4o。
来自主题: AI资讯
4352 点击 2024-10-17 09:56
零一万物的最新模型,打榜赢了GPT-4o。

OpenAI ο1 模型的发布掀起了人们对 AI 推理过程的关注,甚至让现在的 AI 行业开始放弃卷越来越大的模型,而是开始针对推理过程进行优化了。今天我们介绍的这项来自 Meta FAIR 田渊栋团队的研究也是如此,其从人类认知理论中获得了灵感,提出了一种新型 Transformer 架构:Dualformer。
近日,来自斯坦福、MIT、纽约大学和Meta-FAIR等机构的研究人员,通过新的研究重新定义了最大流形容量表示法(MMCR)的可能性。

TeleAI 李学龙团队提出具身世界模型,挖掘大量人类操作视频和少量机器人数据的共同决策模式。

AI对待每个人类都一视同仁吗? 现在OpenAI用53页的新论文揭示:ChatGPT真的会看人下菜碟。 根据用户的名字就自动推断出性别、种族等身份特征,并重复训练数据中的社会偏见。

在自然语言处理、语音识别和时间序列分析等众多领域中,序列建模是一项至关重要的任务。然而,现有的模型在捕捉长程依赖关系和高效建模序列方面仍面临诸多挑战。
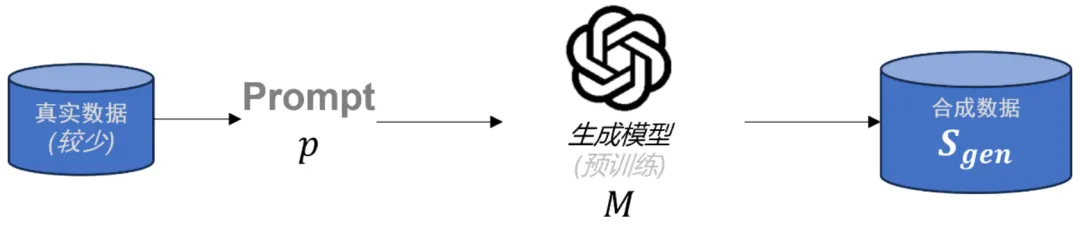
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。
国庆节过后,人工智能领域似乎多了几分冷色调。不知道是因为大语言模型(Large Language Model,LLM)的幻觉,还是因为寒露时节的到来。

Robin3D通过鲁棒指令数据生成引擎(RIG)生成的大规模数据进行训练,以提高模型在3D场景理解中的鲁棒性和泛化能力,在多个3D多模态学习基准测试中取得了优异的性能,超越了以往的方法,且无需针对特定任务的微调。

随着LLM的进步,它将超越代码补全(“Copilot”)的功能,进入代码创作(“Autopilot”)的领域。随着LLM变得越来越复杂,它们能够释放的经济价值也会越来越大。AGI的经济价值仅受我们的想象力限制。