

不花一分钱!GPT-4o微调限时免费开放,每日附赠百万训练token
不花一分钱!GPT-4o微调限时免费开放,每日附赠百万训练token一觉醒来,OpenAI又上新功能了:
来自主题: AI资讯
9970 点击 2024-08-21 13:56
一觉醒来,OpenAI又上新功能了:

本期我们邀请到了 纽约大学计算机科学院博士 童晟邦 带来【多模态大模型:视觉为中心的探索】的主题分享。

虽然大语言模型(LLM)的能力不断突破,但在长文生成方面却一直存在瓶颈。近日,清华大学和智谱AI联合发布的最新研究成果,为解决这一难题提供了创新方案。这项名为"LongWriter"的技术,成功将AI模型的长文生成能力从约2000字提升至10000字以上,同时保持了高质量输出。这一成果通过创新的数据构建方法、模型训练策略和评估基准,为AI长文创作开辟了新天地。

AI掌握自我设计的权力,将会怎样?最近,来自UBC等机构研究人员提出了「智能体自动化设计」系统,让元智能体使用搜索算法,自动构建强大的同类。
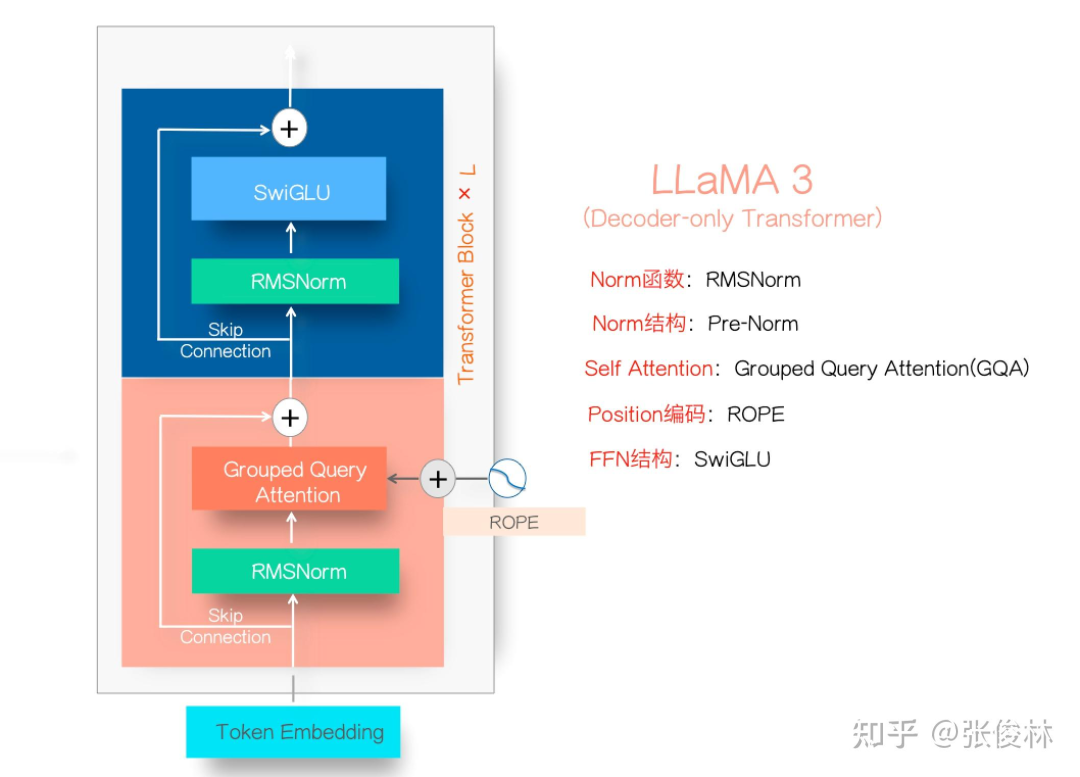
Llama3.1系列模型的开源,真让大模型格局大震,指标上堪比最好的闭源模型比如GPT 4o和Claude3.5,让开源追赶闭源成为现实。

作为基础的视觉语言任务,指代表达理解(referring expression comprehension, REC)根据自然语言描述来定位图中被指代的目标。REC 模型通常由三部分组成:视觉编码器、文本编码器和跨模态交互,分别用于提取视觉特征、文本特征和跨模态特征特征交互与增强。

具身智能的数据从这里来。

“乱世”其实早已到来,只不过这次是公开承认了这个现实。
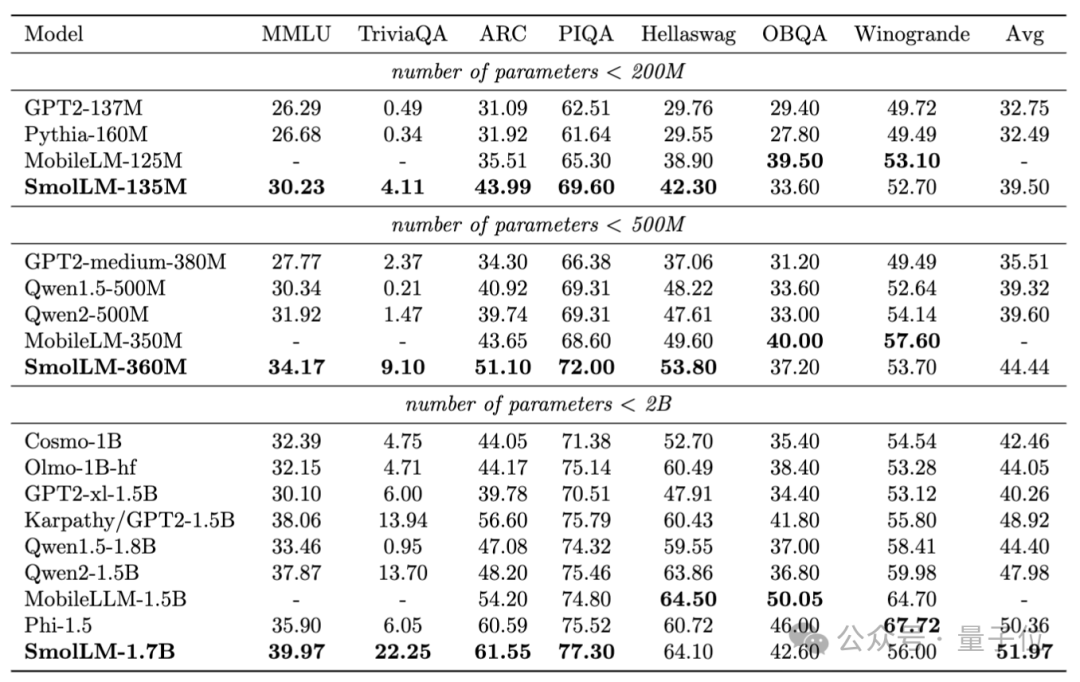
浏览器里直接能跑的SOTA小模型来了,分别在2亿、5亿和20亿级别获胜,抱抱脸出品。

合成数据2.0秘诀曝光了!来自微软的研究人员们提出了智能体框架AgentInstruct,能够自动创建大量、多样化的合成数据。经过合成数据微调后的模型Orca-3,在多项基准上刷新了SOTA。