
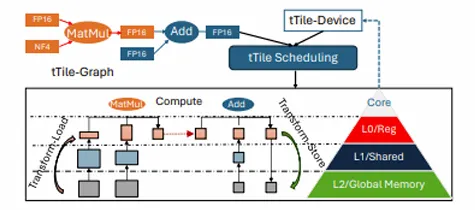
大模型终端部署新趋势:硬件直接支持混合矩阵乘法
大模型终端部署新趋势:硬件直接支持混合矩阵乘法在人工智能领域,模型参数的增多往往意味着性能的提升。但随着模型规模的扩大,其对终端设备的算力与内存需求也日益增加。低比特量化技术,由于可以大幅降低存储和计算成本并提升推理效率,已成为实现大模型在资源受限设备上高效运行的关键技术之一。然而,如果硬件设备不支持低比特量化后的数据模式,那么低比特量化的优势将无法发挥。
来自主题: AI资讯
5173 点击 2024-08-19 14:49
在人工智能领域,模型参数的增多往往意味着性能的提升。但随着模型规模的扩大,其对终端设备的算力与内存需求也日益增加。低比特量化技术,由于可以大幅降低存储和计算成本并提升推理效率,已成为实现大模型在资源受限设备上高效运行的关键技术之一。然而,如果硬件设备不支持低比特量化后的数据模式,那么低比特量化的优势将无法发挥。

越来越多研究发现,后训练对模型性能同样重要。Allen AI的机器学习研究员Nathan Lambert最近发表了一篇技术博文,总结了科技巨头们所使用的模型后训练配方。
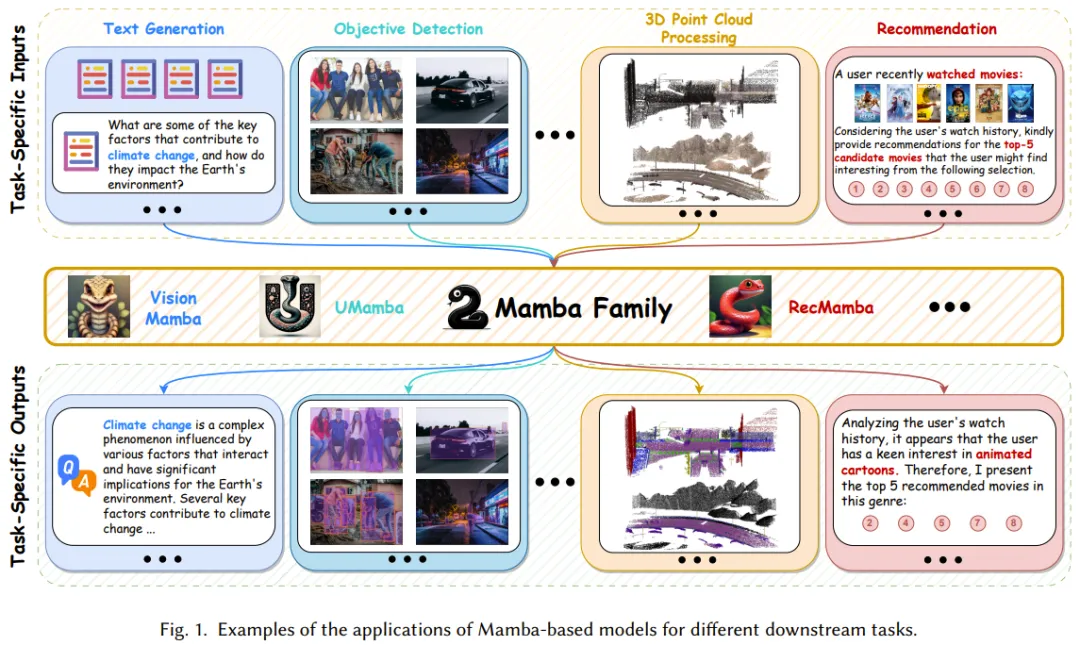
Mamba 虽好,但发展尚早。

研究发现:大模型尚无法独立学习或获得新技能。

AI 技术在辅助抗体设计方面取得了巨大进步。然而,抗体设计仍然严重依赖于从血清中分离抗原特异性抗体,这是一个资源密集且耗时的过程。

单目深度估计新成果来了!
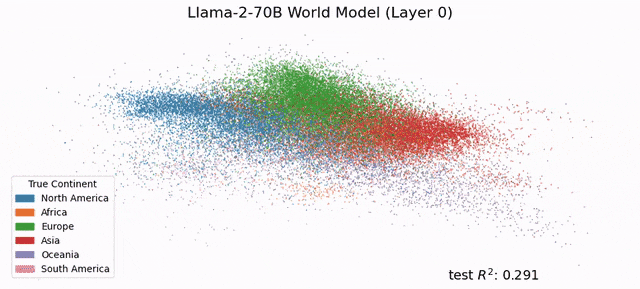
MIT CSAIL的研究人员发现,LLM的「内心深处」已经发展出了对现实的模拟,模型对语言和世界的理解,绝不仅仅是简单的「鹦鹉学舌」。也就说,在未来,LLM会比今天更深层地理解语言。

让模型具有更加广泛和通用的认知能力,是当前人工智能(AI)领域发展的重要目标。目前流行的大模型路径是基于 Scaling Law (尺度定律) 去构建更大、更深和更宽的神经网络提升模型的表现,可称之为 “基于外生复杂性” 的通用智能实现方法。然而,这一路径也面临着一些难以克服的困境,例如高昂的计算资源消耗和能源消耗,并且在可解释性方面存在不足。

只用不到10%的训练参数,就能实现ControlNet一样的可控生成!
“FLUX在线版”,新增一系列重磅功能!