
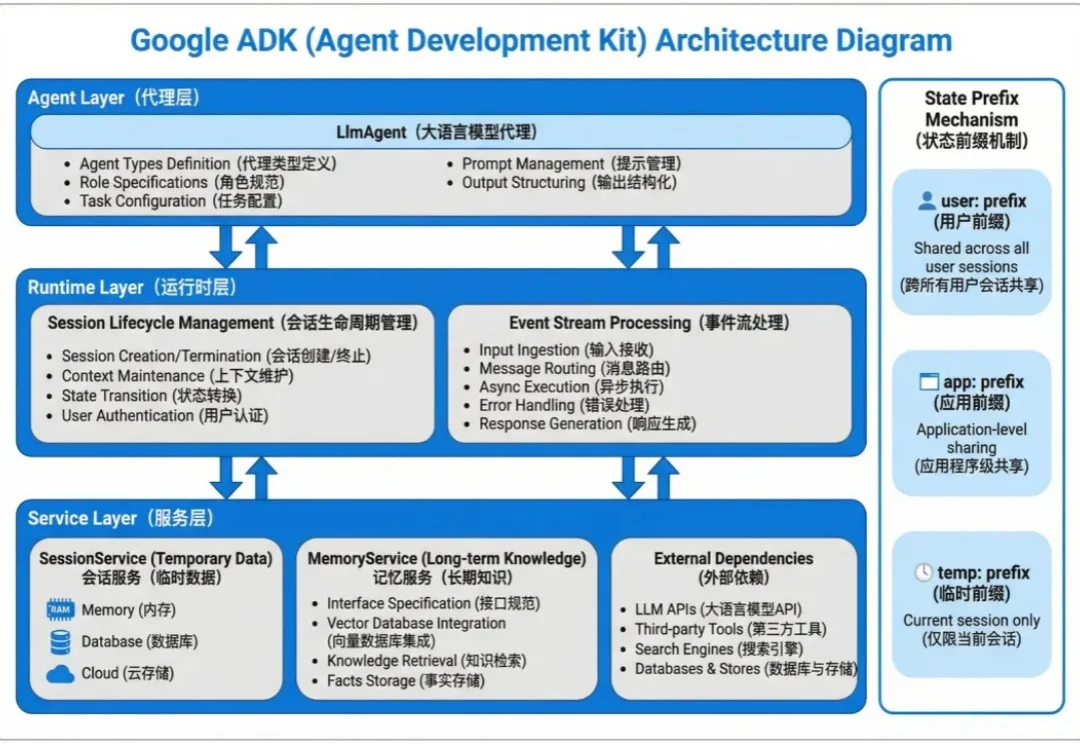
教程|别只盯着 Langchain!Google ADK 搭建 Agent,上下文管理效率翻倍
教程|别只盯着 Langchain!Google ADK 搭建 Agent,上下文管理效率翻倍Agent 的状态数据分两种:会话内的临时上下文和跨会话的长期知识。
来自主题: AI技术研报
8167 点击 2025-12-26 09:43
Agent 的状态数据分两种:会话内的临时上下文和跨会话的长期知识。
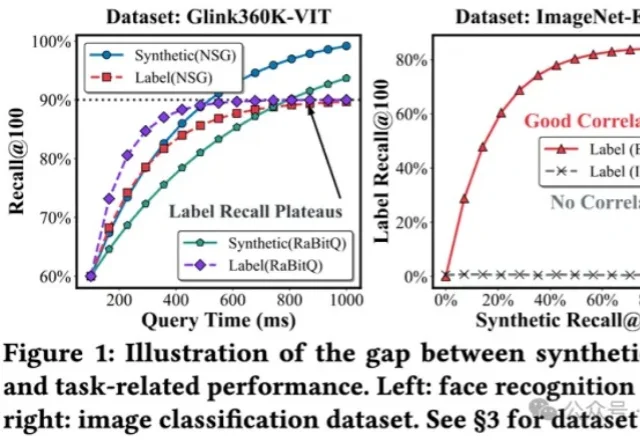
将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。

什么?决定 AI 上限的已不再是底座模型,而是外围的「推理编排」(Orchestration)。
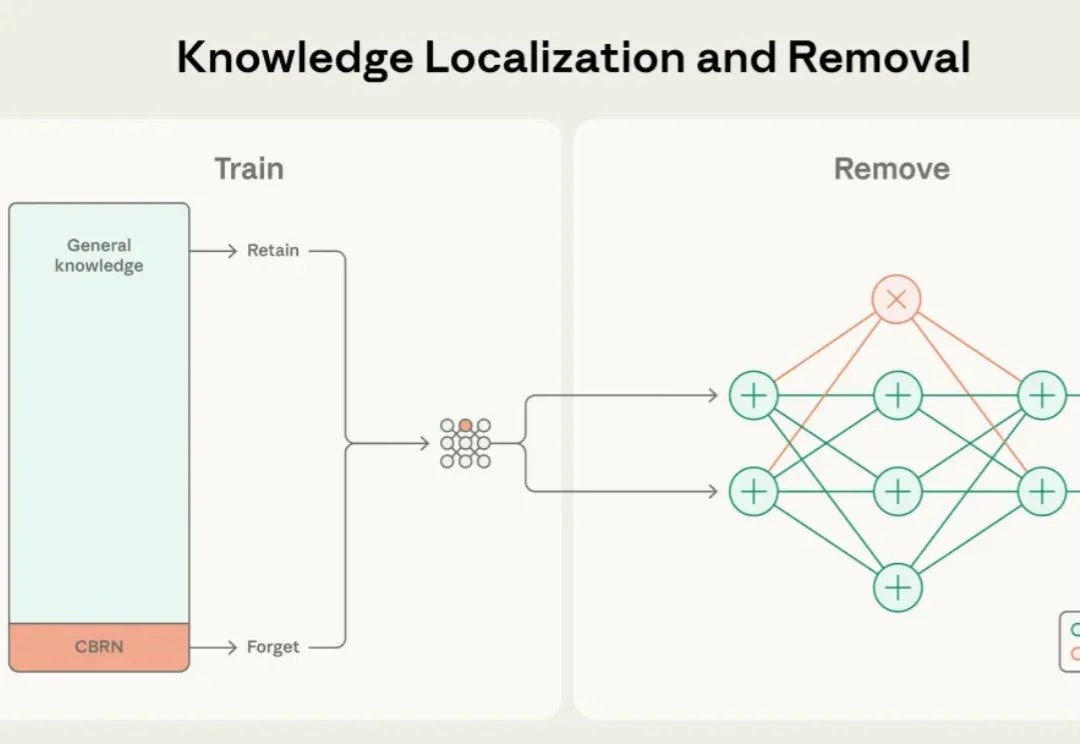
近年来,大语言模型的能力突飞猛进,但随之而来的却是愈发棘手的双重用途风险(dual-use risks)。当模型在海量公开互联网数据中学习时,它不仅掌握语言与推理能力,也不可避免地接触到 CBRN(化学、生物、放射、核)危险制造、软件漏洞利用等高敏感度、潜在危险的知识领域。

视频生成模型总是「记性不好」?生成几秒钟后物体就变形、背景就穿帮?北大、中大等机构联合发布EgoLCD,借鉴人类「长短时记忆」机制,首创稀疏KV缓存+LoRA动态适应架构,彻底解决长视频「内容漂移」难题,在EgoVid-5M基准上刷新SOTA!让AI像人一样拥有连贯的第一人称视角记忆。

我们不会和 Meta 竞价,即便待遇远低于对方,核心人才仍愿意留在 OpenAI,只因大家坚信这里的发展潜力和 AGI 愿景。

在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。

多模态大语言模型(MLLMs)已成为AI视觉理解的核心引擎,但其在真实世界视觉退化(模糊、噪声、遮挡等)下的性能崩溃,始终是制约产业落地的致命瓶颈。
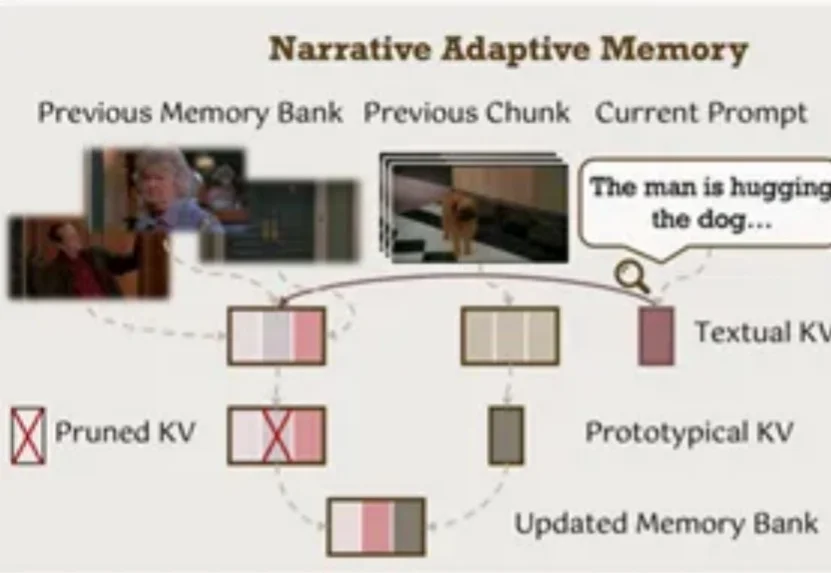
你是否曾被AI视频生成的不连贯性所困扰?
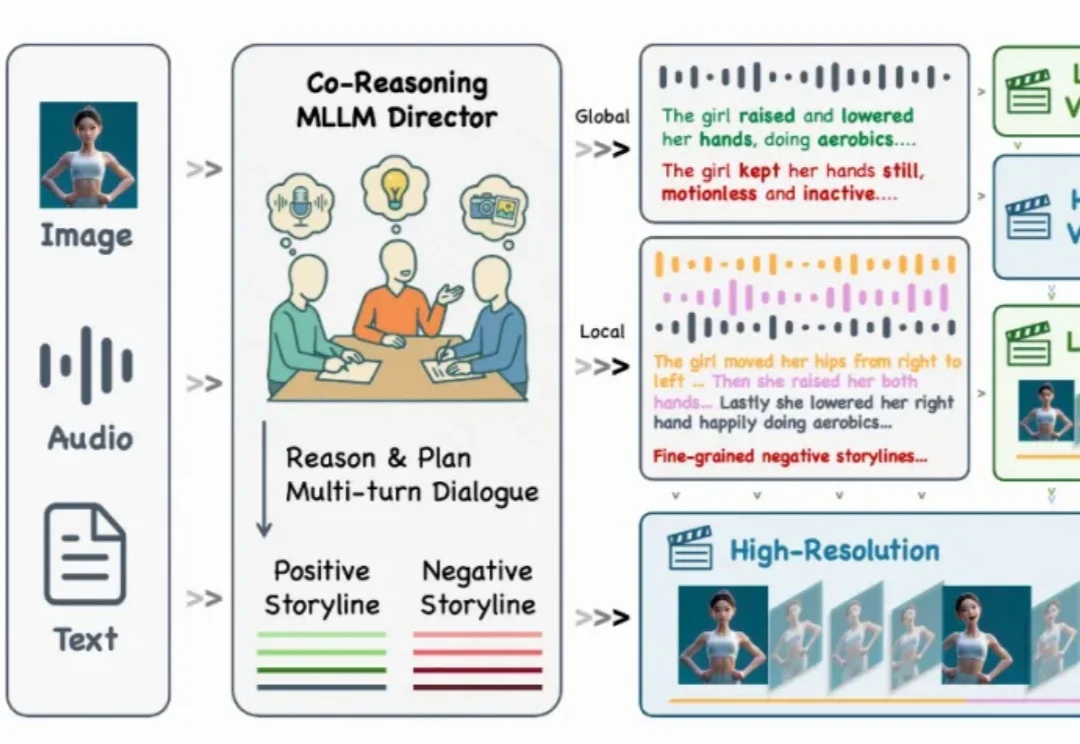
还记得几个月前那个能随着音乐节拍自然舞动的 KlingAvatar 数字人吗?现在,它迎来了史诗级进化!