
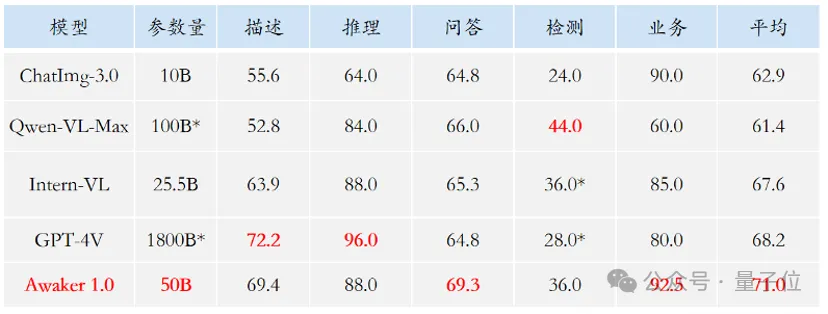
超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。
来自主题: AI技术研报
7064 点击 2024-04-29 20:06
训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。

近期,大语言模型、文生图模型等大规模 AI 模型迅猛发展。在这种形势下,如何适应瞬息万变的需求,快速适配大模型至各类下游任务,成为了一个重要的挑战。受限于计算资源,传统的全参数微调方法可能会显得力不从心,因此需要探索更高效的微调策略。
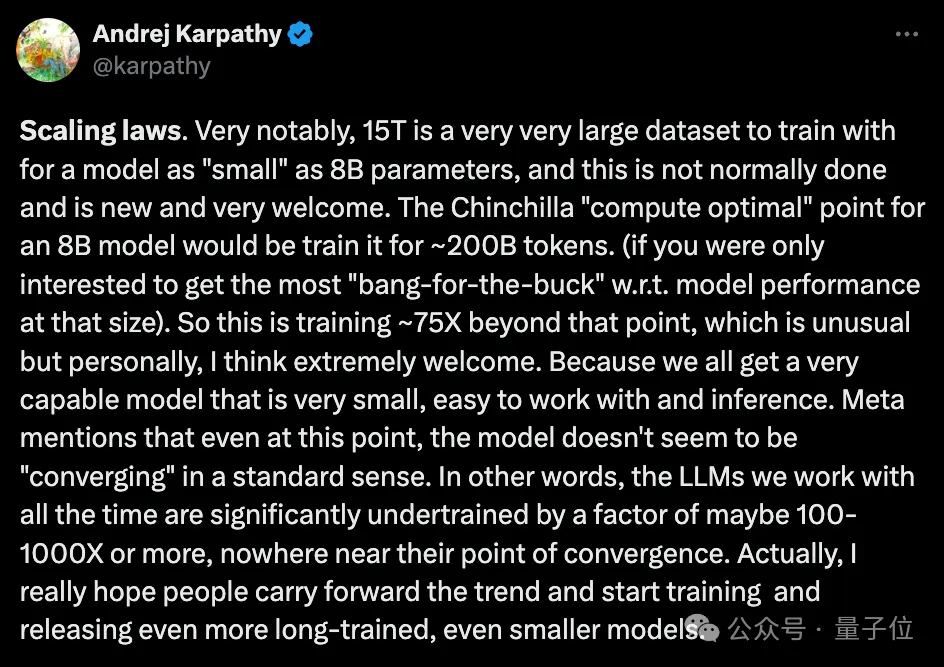
大模型力大砖飞,让LLaMA3演绎出了新高度: 超15T Token数据上的超大规模预训练,既实现了令人印象深刻的性能提升,也因远超Chinchilla推荐量再次引爆开源社区讨论。
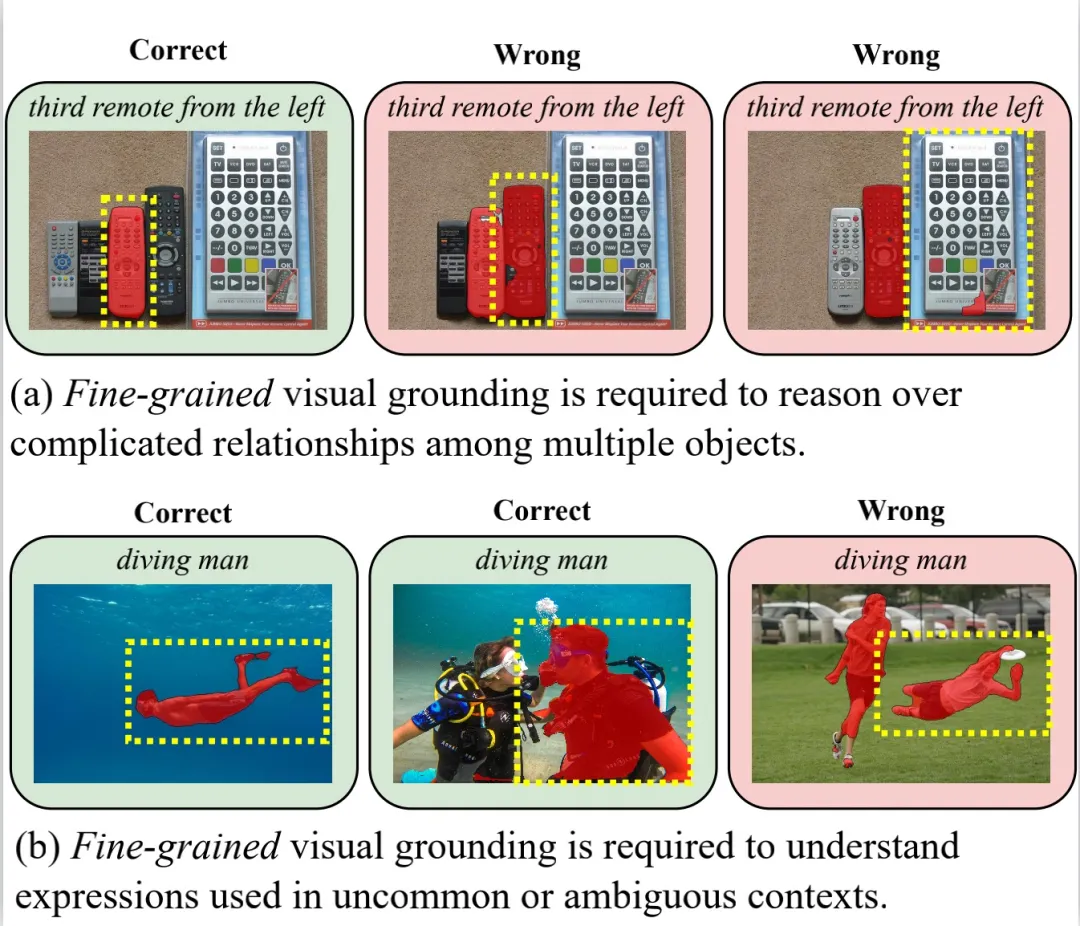
指代分割 (Referring Image Segmentation,RIS) 是一项极具挑战性的多模态任务,要求算法能够同时理解精细的人类语言和视觉图像信息,并将图像中句子所指代的物体进行像素级别的分割。

奔向通用人工智能,大模型又迈出一大步。

大模型语料是指用于训练和评估大模型的一系列文本、语音或其他模态的数据。
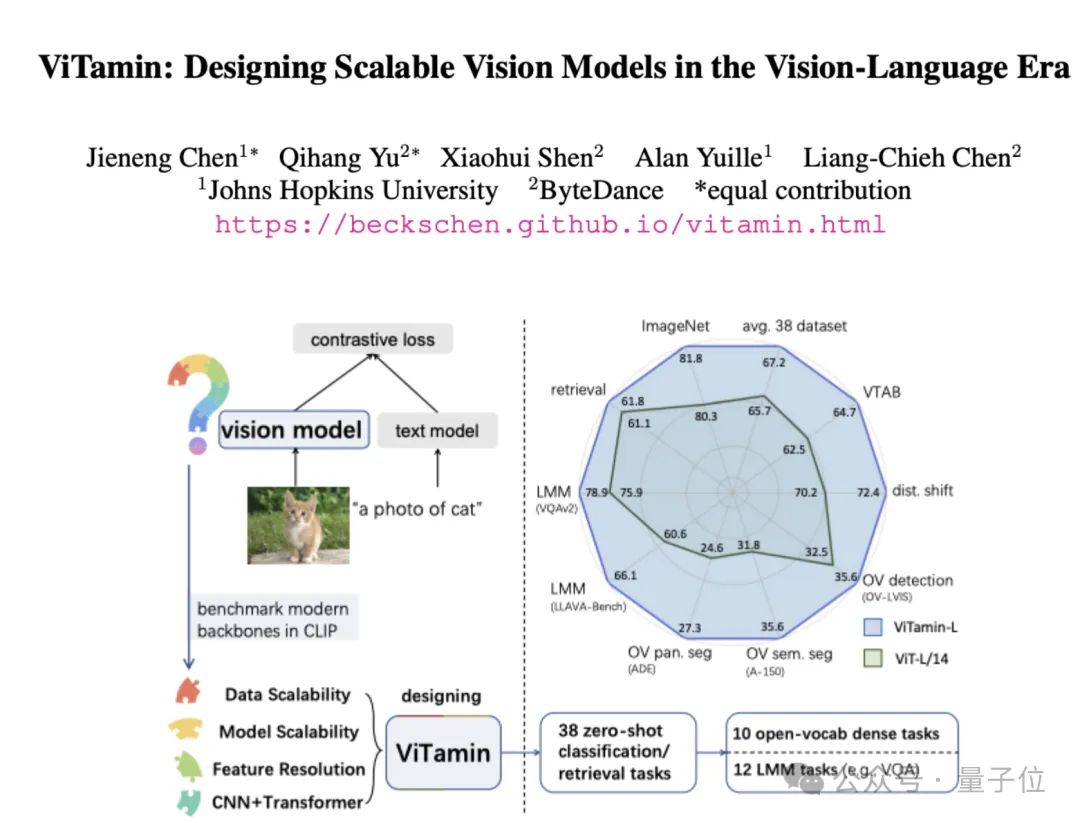
视觉语言模型屡屡出现新突破,但ViT仍是图像编码器的首选网络结构。
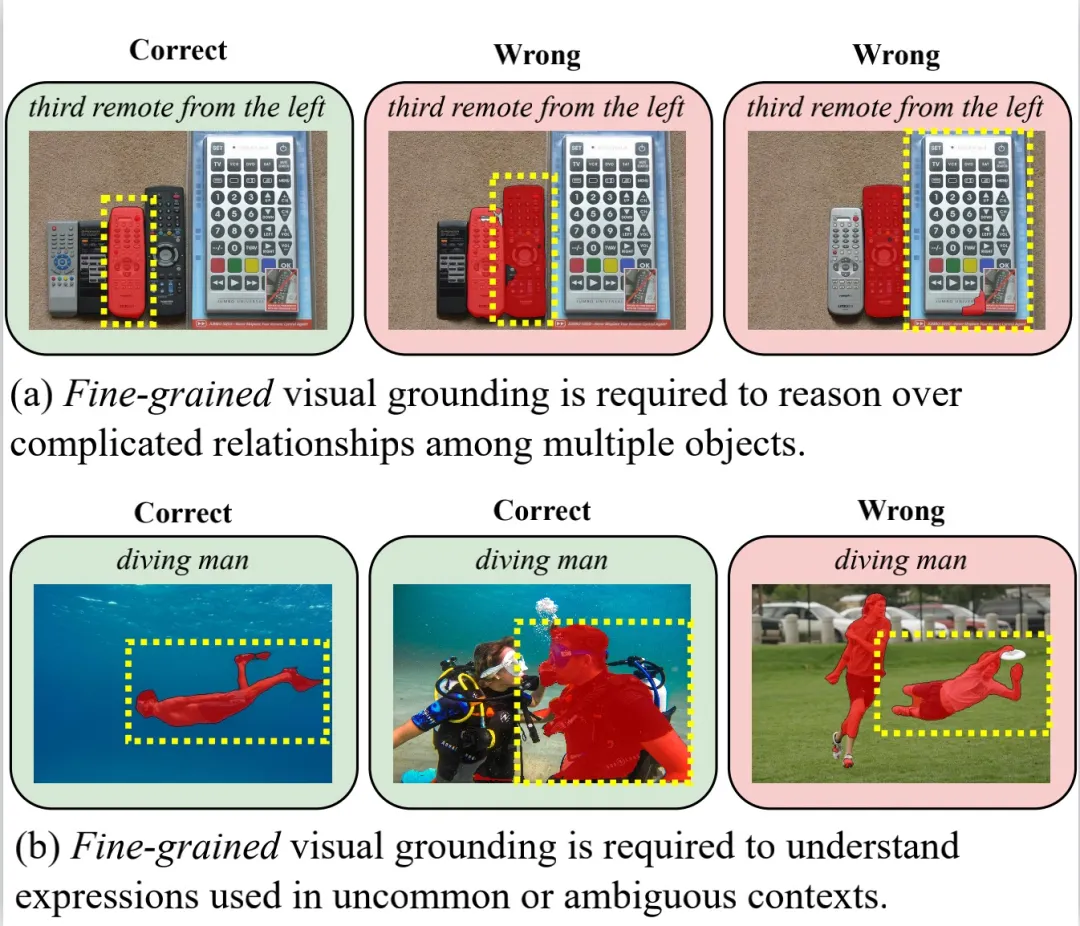
指代分割 (Referring Image Segmentation,RIS) 是一项极具挑战性的多模态任务,要求算法能够同时理解精细的人类语言和视觉图像信息,并将图像中句子所指代的物体进行像素级别的分割。
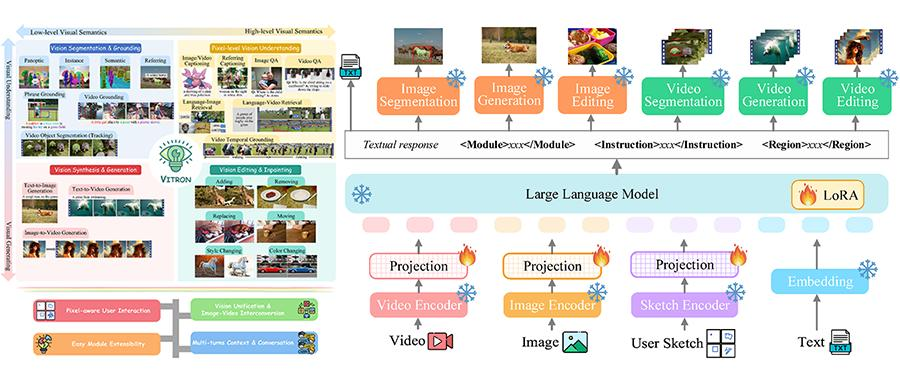
奔向通用人工智能,大模型又迈出一大步。
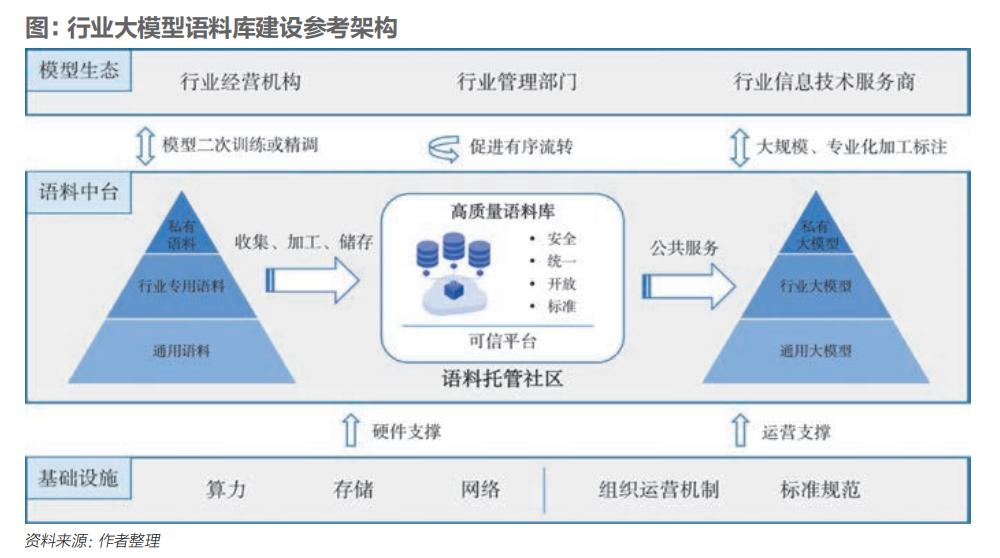
大模型语料是指用于训练和评估大模型的一系列文本、语音或其他模态的数据。语料规模和质量对大模型性能以及应用的深度、广度有着至关重要的影响。