

用童话训练AI模型,微软找到了探索生成模型参数的新切入点
用童话训练AI模型,微软找到了探索生成模型参数的新切入点即便大语言模型的参数规模日渐增长,其模型中的参数到底是如何发挥作用的还是让人难以琢磨,直接对大模型进行分析又费钱费力。针对这种情况,微软的两位研究员想到了一个绝佳的切入点
来自主题: AI技术研报
9834 点击 2023-10-31 16:46
即便大语言模型的参数规模日渐增长,其模型中的参数到底是如何发挥作用的还是让人难以琢磨,直接对大模型进行分析又费钱费力。针对这种情况,微软的两位研究员想到了一个绝佳的切入点

有关GPT-5的消息最近又火起来了。从最一开始的爆料,说OpenAI正在秘密训练GPT-5,到后来Sam Altman澄清;再到后来说需要多少张H100 GPU来训练GPT-5,DeepMind的CEO Suleyman采访「实锤」OpenAI正在秘密训练GPT-5。

DeepMind最新研究发现,只要模型设计上没有缺陷,决定模型性能的核心可能是训练计算量和数据。在相同计算量下,卷积神经网络模型和视觉Transformers模型的性能居然能旗鼓相当!

相比于一味规避“有毒”数据,以毒攻毒,干脆给大模型喂点错误文本,再让模型剖析、反思出错的原因,反而能够让模型真正理解“错在哪儿了”,进而避免胡说八道。

最近,出现了一种新AI工具Nightshade,它可以让艺术家在他们的作品中添加不可见的像素变化。这些作品上传到网上被抓取到人工智能模型的训练集中,它添加的“病毒”,就可以导致最终模型在训练这些数据的时候,以混乱和不可预测的方式崩溃。

大型语言模型能力惊人,但在部署过程中往往由于规模而消耗巨大的成本。华盛顿大学联合谷歌云计算人工智能研究院、谷歌研究院针对该问题进行了进一步解决,提出了逐步微调(Distilling Step-by-Step)的方法帮助模型训练。

英伟达最新AI AgentEureka ,用GPT-4生成奖励函数,结果教会机器人完成了三十多个复杂任务。
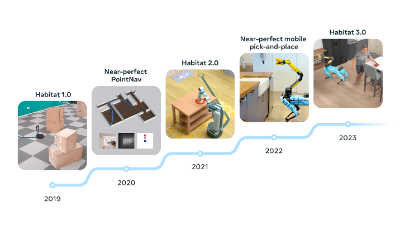
Meta Platforms Inc. 基础人工智能研究团队的研究人员今天表示,他们将发布 AI 模拟环境 Habitat 的更高级版本,用来教机器人如何与物理世界交互。
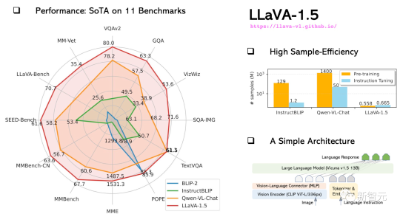
GPT-4V风头正盛,LLaVA-1.5就来踢馆了!它不仅在11个基准测试上都实现了SOTA,而且13B模型的训练,只用8个A100就可以在1天内完成。

而在AI大模型的相关市场竞争中,除了底层的算法、架构外,“语料”则是一个被反复提及的关键要素。