

GPT-4太烧钱,微软想甩掉OpenAI?曝出Plan B:千块GPU专训「小模型」,开启必应内测
GPT-4太烧钱,微软想甩掉OpenAI?曝出Plan B:千块GPU专训「小模型」,开启必应内测GPT-4太吃算力,微软被爆内部制定了Plan B,训练更小、成本更低的模型,进而摆脱OpenAI。
来自主题: AI资讯
8215 点击 2023-09-27 15:04
GPT-4太吃算力,微软被爆内部制定了Plan B,训练更小、成本更低的模型,进而摆脱OpenAI。

DALLE-3 是一个文本到图像生成器,可以根据称为提示的书面描述创建新颖的图像。尽管 OpenAI 没有发布有关 DALL-E 3 的技术细节,但 DALL-E 早期版本的核心 AI 模型接受了人类艺术家和摄影师创作的数百万张图像的训练
多模态大模型的战场上,已有人闻到风声。据外媒爆料,OpenAI的全新多模态模型Gobi似乎已在筹备中。谷歌和OpenAI的这场对决,似乎已是箭在弦上了。
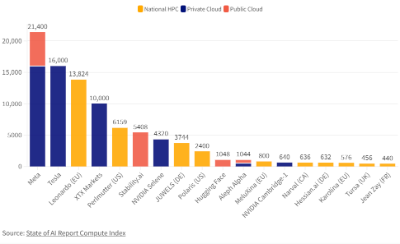
在高性能计算(HPC)、人工智能(AI)、和数据分析等领域,图形处理器(GPUs)正在发挥越来越重要的作用。其中,NVIDIA的 A100尤为引人注目。这是英伟达最强大的显卡处理器,也是当前使用最广泛大模型训练用的显卡。
就在最近,百川智能正式发布Baichuan 2系列开源大模型。作为开源领域性能最好的中文模型,在国内,Baichuan 2是要妥妥替代Llama 2了。

一些日本研究人员认为,接受外语训练的人工智能系统无法掌握日本语言和文化的复杂性,所以,需要一个属于自己的chatGPT。

德意志银行正在测试几个人工智能(AI)工具,目的是在从交易员电话交谈的语气中发现潜在不当行为迹象。

在高工资的芬兰,很少有人愿意从事数据标注这种体力活,AI行业一家公司另辟蹊径,选择囚犯来完成这样的工作。

《华尔街日报》报道,Meta 公司一直在抢购人工智能训练芯片并建立数据中心,以创建一个与chatGPT 4.0一样强大的新AI。
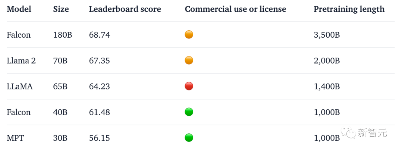
一经发布,地表最强开源模型Falcon 180B直接霸榜HF。3.5万亿token训练,性能直接碾压Llama 2。