

国产AI芯片看两个指标:模型覆盖+集群规模能力 | 百度智能云王雁鹏@MEET2026
国产AI芯片看两个指标:模型覆盖+集群规模能力 | 百度智能云王雁鹏@MEET2026当国产AI芯片接连发布、估值高涨之际,一个尖锐的问题依然悬在头顶:它们真的能撑起下一代万卡集群与万亿参数模型的训练吗?
来自主题: AI资讯
10069 点击 2025-12-19 09:38
当国产AI芯片接连发布、估值高涨之际,一个尖锐的问题依然悬在头顶:它们真的能撑起下一代万卡集群与万亿参数模型的训练吗?
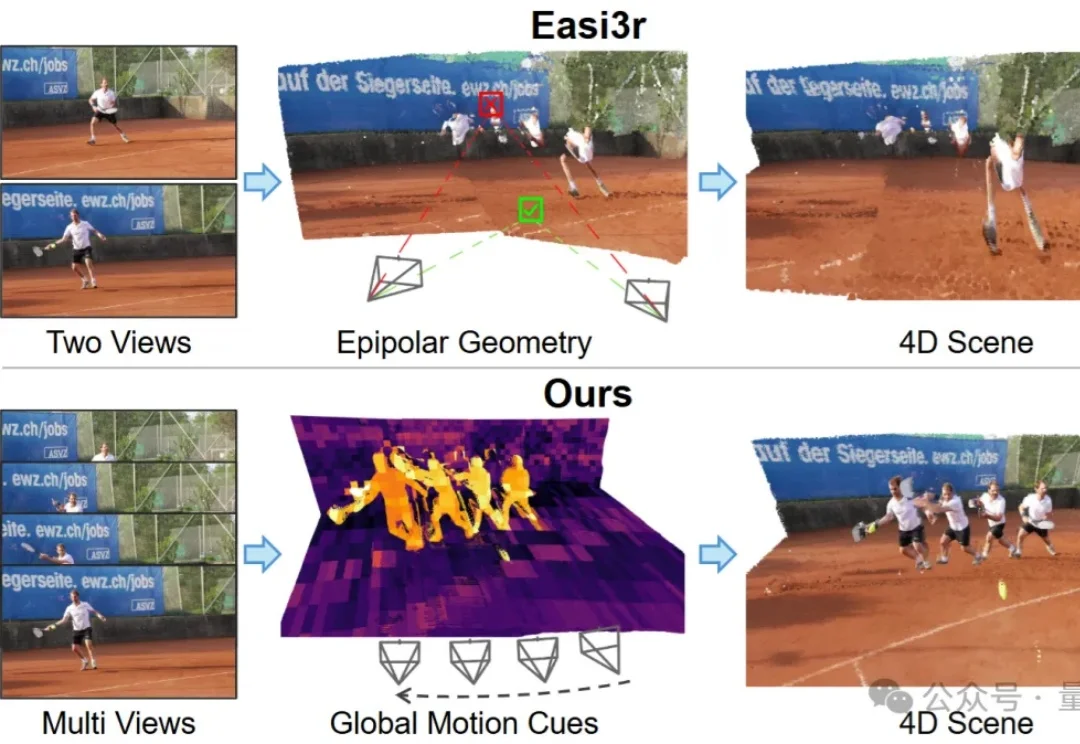
如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?
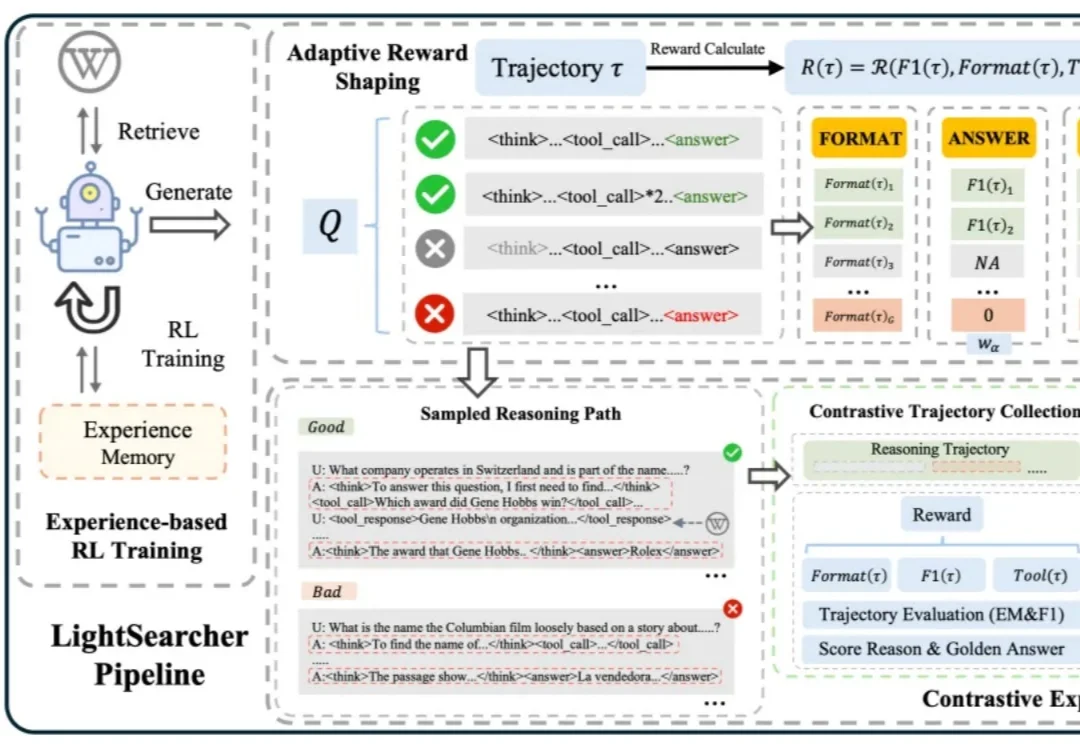
如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。
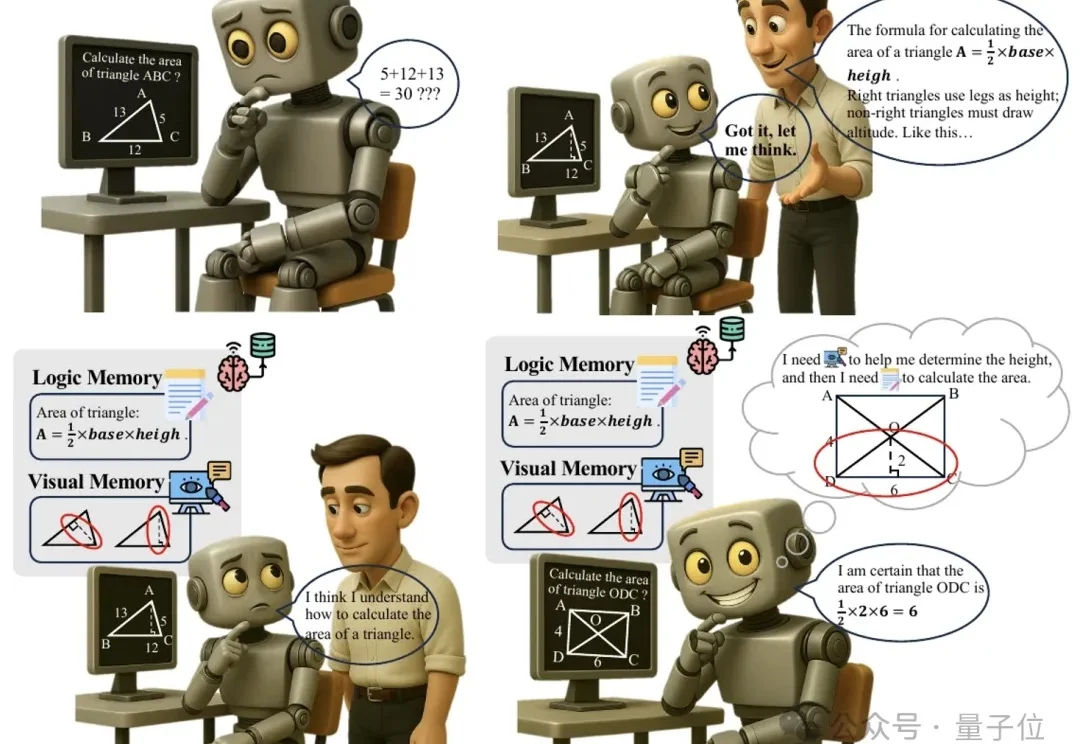
多模态推理又有新招,大模型“记不住教训”的毛病有治了。
今天聊一聊我们如何做高质量rerank。

北京大学团队提出了一种新的视觉语义场景补全方法HD²-SSC,用于从多视角图像重建三维语义场景。该方法通过高维度语义解耦和高密度占用优化,解决了现有技术中二维输入与三维输出之间的维度差异,以及人工标注与真实场景密度差异的问题,从而实现更准确的语义场景补全。
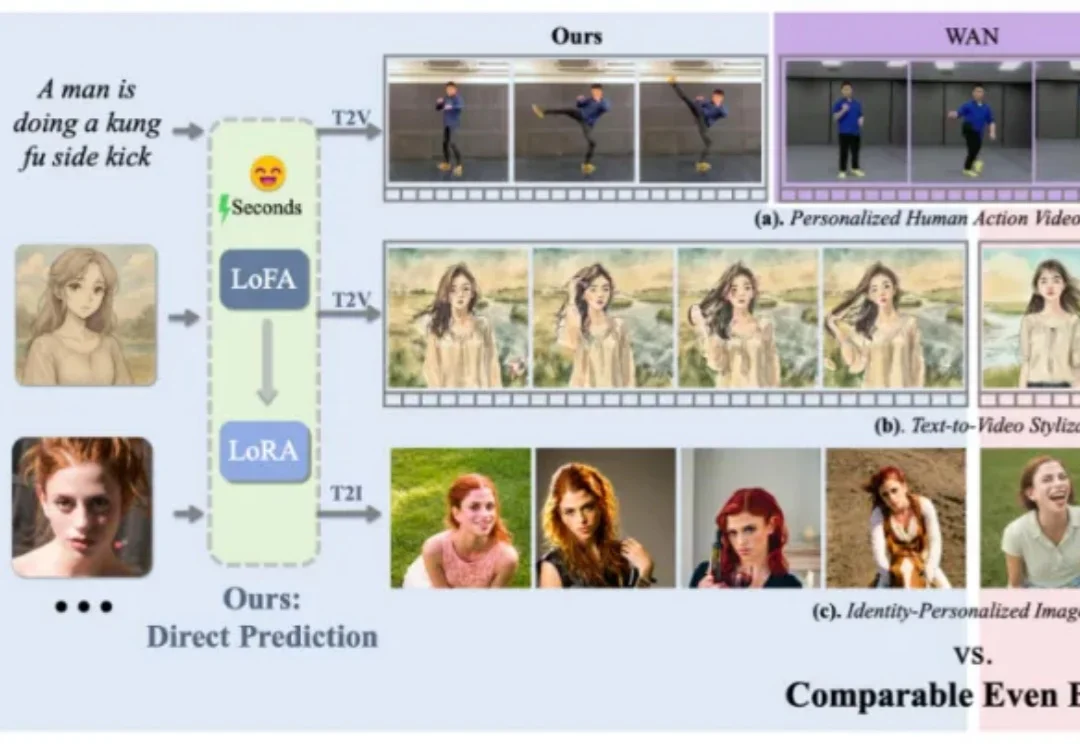
在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。

LLM 智能体很赞,正在成为一种解决复杂难题的强大范式。
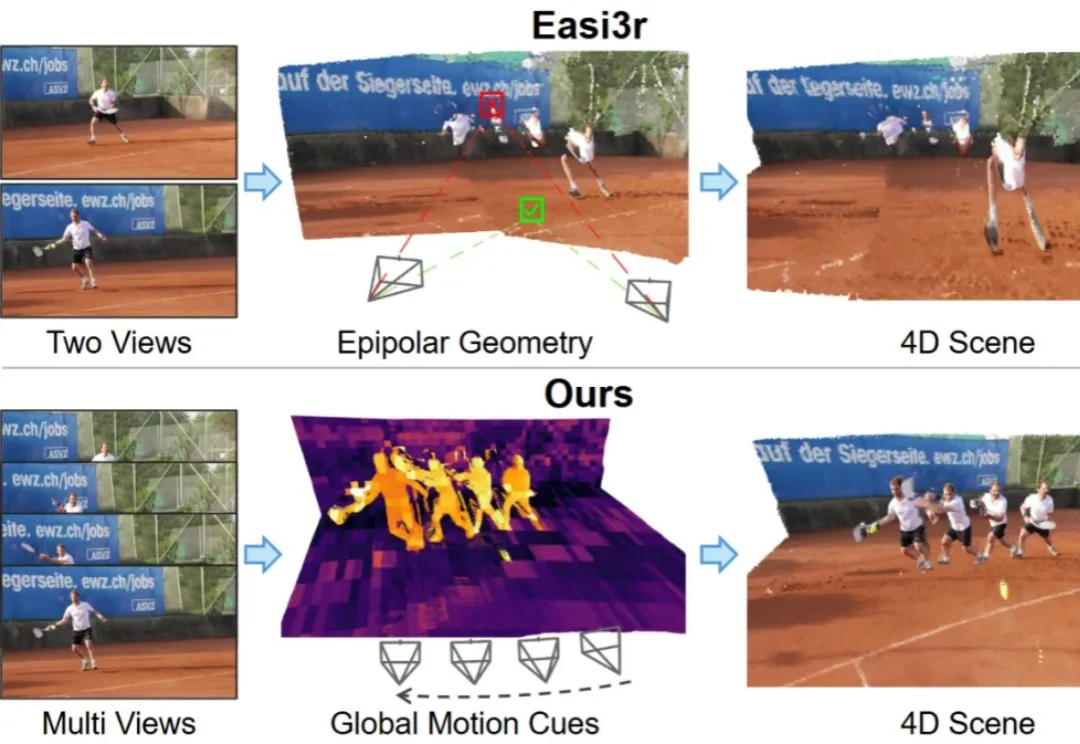
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力?

生成式模型正在成为机器人和具身智能领域的重要范式,它能够从高维视觉观测中直接生成复杂、灵活的动作策略,在操作、抓取等任务中表现亮眼。但在真实系统中,这类方法仍面临两大「硬伤」:一是训练极度依赖大规模演示数据,二是推理阶段需要大量迭代,动作生成太慢,难以实时控制。