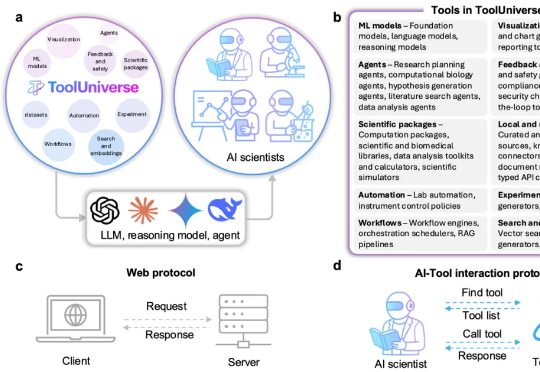
无需训练一键调用超600种工具,哈佛MIT打造AI科学家的“Linux操作系统”,让大模型秒变专家自主做实验
无需训练一键调用超600种工具,哈佛MIT打造AI科学家的“Linux操作系统”,让大模型秒变专家自主做实验近日,OpenAI 宣称要在 2028 年实现让 AI 完全自主做研究,一下子又把焦点聚在了AI 科学家。 过去,AI 只是作为“助理”辅助研究者们进行科学研究。现在,美国哈佛大学与美国麻省理工学院联
来自主题: AI资讯
10106 点击 2025-11-01 09:14