

刚刚,Kimi开源新架构,开始押注线性注意力
刚刚,Kimi开源新架构,开始押注线性注意力月之暗面在这一方向有所突破。在一篇新的技术报告中,他们提出了一种新的混合线性注意力架构 ——Kimi Linear。该架构在各种场景中都优于传统的全注意力方法,包括短文本、长文本以及强化学习的 scaling 机制。
来自主题: AI技术研报
7540 点击 2025-10-31 14:33
月之暗面在这一方向有所突破。在一篇新的技术报告中,他们提出了一种新的混合线性注意力架构 ——Kimi Linear。该架构在各种场景中都优于传统的全注意力方法,包括短文本、长文本以及强化学习的 scaling 机制。

厦门大学和腾讯合作的最新论文《FlashWorld: High-quality 3D Scene Generation within Seconds》获得了海内外的广泛关注,在当日 Huggingface Daily Paper 榜单位列第一,并在 X 上获得 AK、Midjourney 创始人、SuperSplat 创始人等 AI 大佬点赞转发。
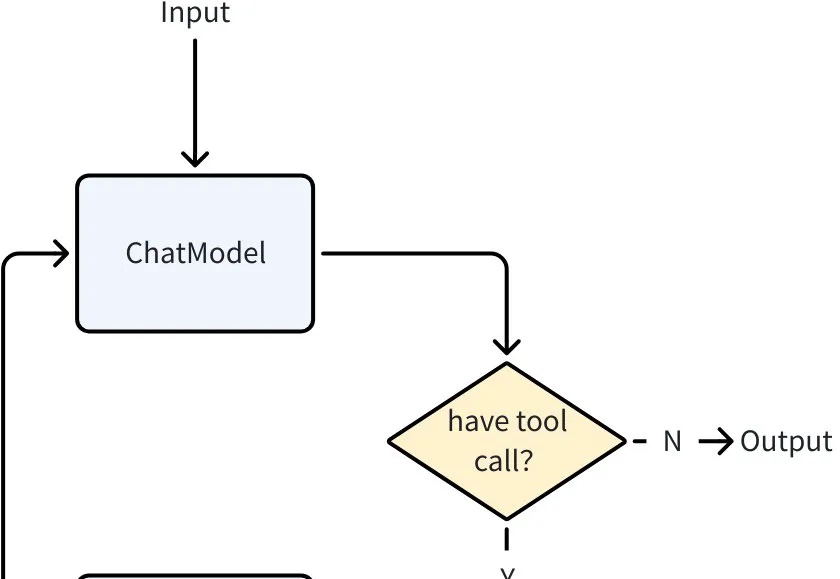
当大语言模型突破了 “理解与生成” 的瓶颈,Agent 迅速成为 AI 落地的主流形态。从智能客服到自动化办公,几乎所有场景都需要 Agent 来承接 LLM 能力、执行具体任务。
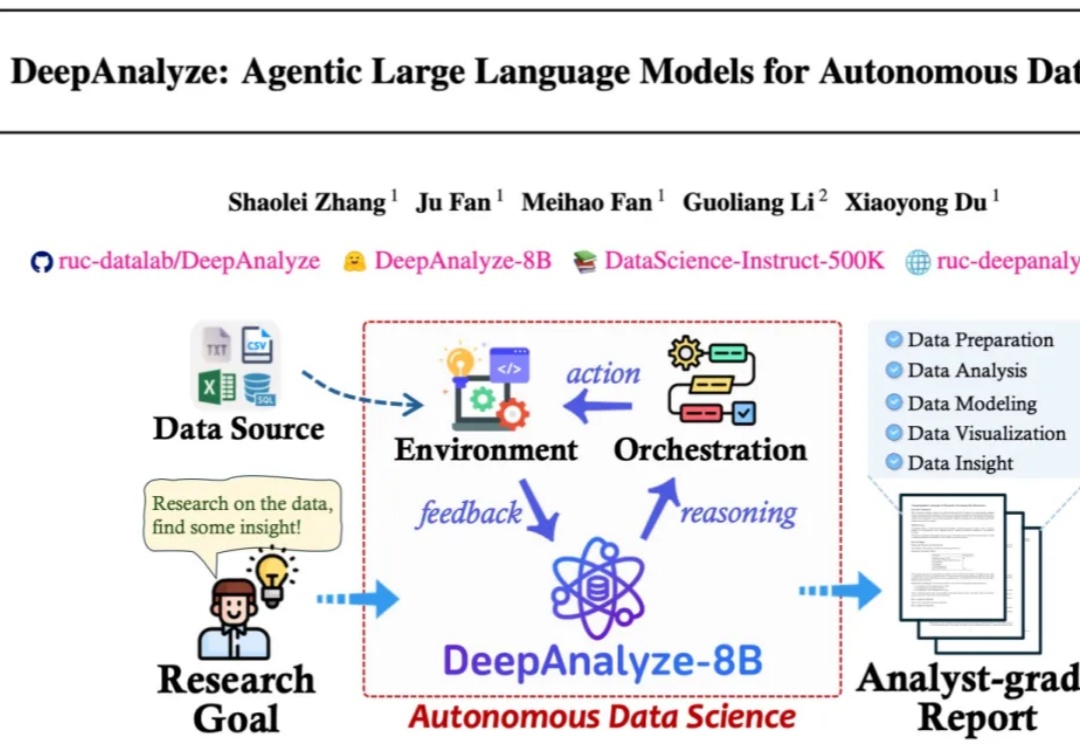
来自人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM。DeepAnalyze引起了社区内广泛讨论,一周内收获1000多个GitHub星标、20w余次社交媒体浏览量。
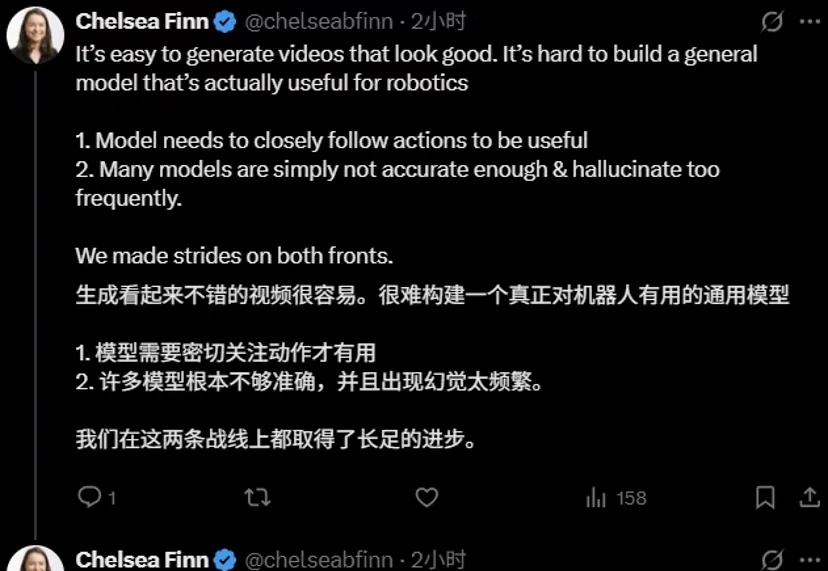
这两天,Physical Intelligence(PI)联合创始人Chelsea Finn在𝕏上,对斯坦福课题组一项最新世界模型工作kuakua连续点赞。
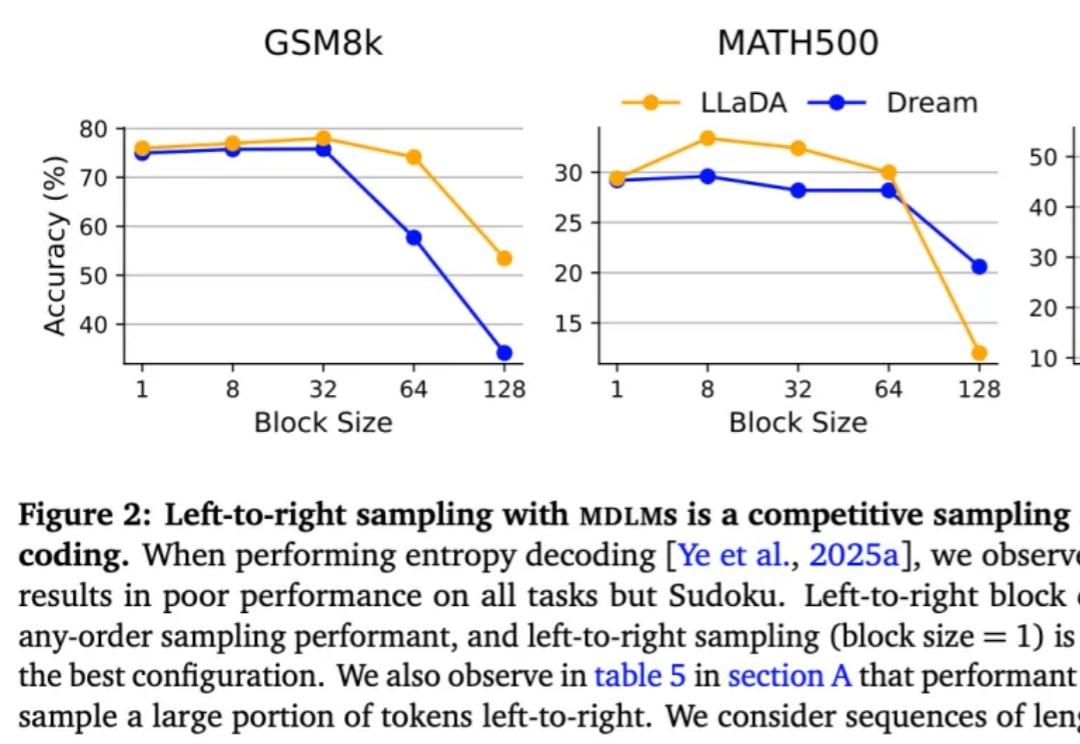
按从左到右的顺序依次生成下一个 token 真的是大模型生成方式的最优解吗?最近,越来越多的研究者对此提出质疑。其中,有些研究者已经转向一个新的方向 —— 掩码扩散语言模型(MDLM)。

家人们,不知道你有没有试过,在和 AI 聊天时,冷不丁地问一句: “你刚刚在想什么?”

用 iPhone 本地跑大模型已经不是新鲜事了,但能不能在 iPhone 上微调模型呢?

近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
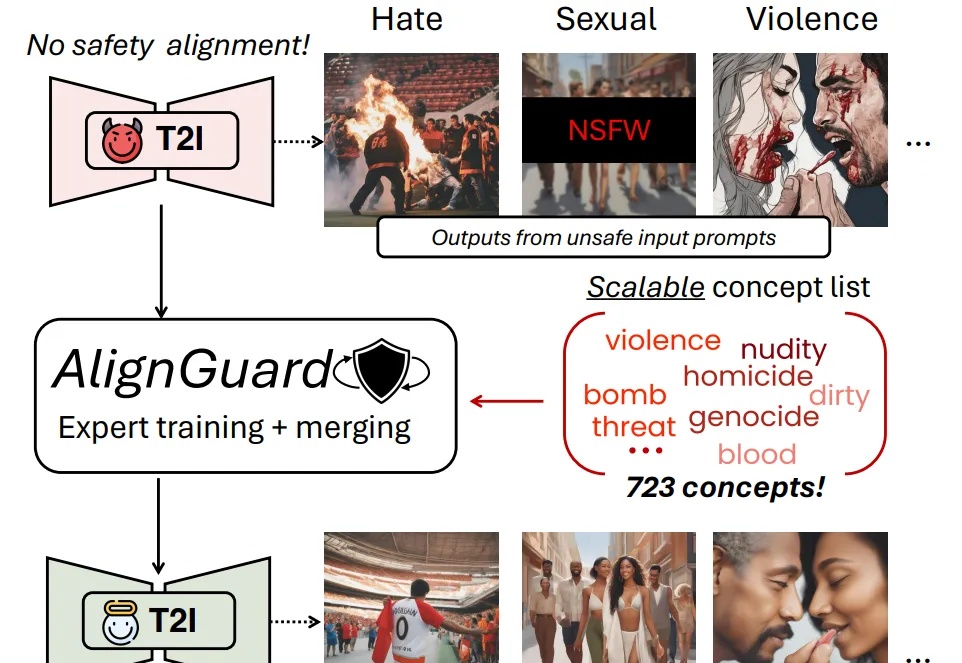
随着文图生成模型的广泛应用,模型本身有限的安全防护机制使得用户有机会无意或故意生成有害的图片内容,并且该内容有可能会被恶意使用。现有的安全措施主要依赖文本过滤或概念移除的策略,只能从文图生成模型的生成能力中移除少数几个概念。