

天下苦VAE久矣:阿里高德提出像素空间生成模型训练范式, 彻底告别VAE依赖
天下苦VAE久矣:阿里高德提出像素空间生成模型训练范式, 彻底告别VAE依赖近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
来自主题: AI技术研报
6813 点击 2025-10-30 17:03
近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
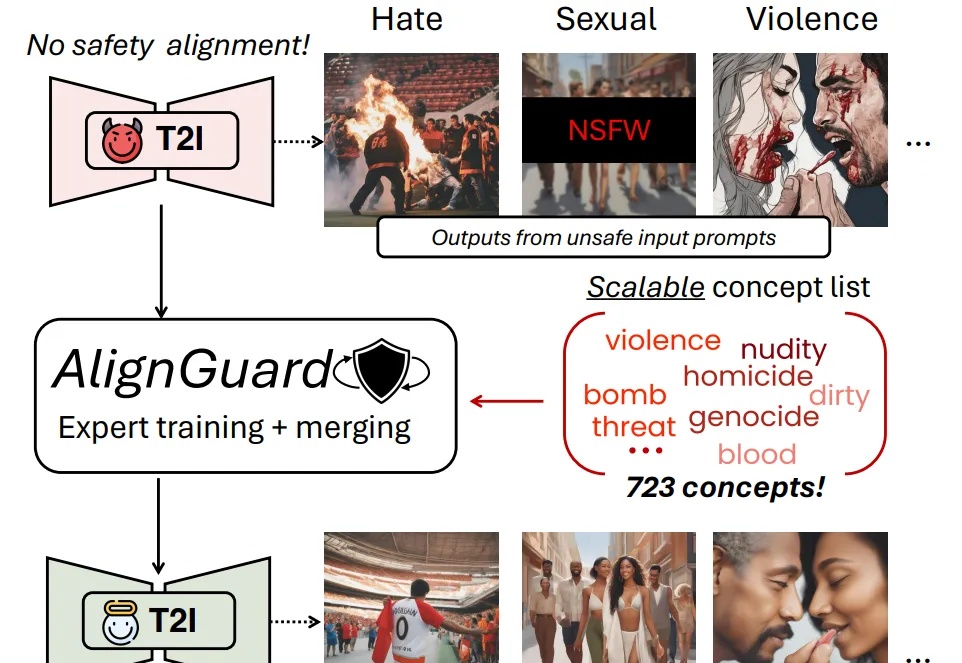
随着文图生成模型的广泛应用,模型本身有限的安全防护机制使得用户有机会无意或故意生成有害的图片内容,并且该内容有可能会被恶意使用。现有的安全措施主要依赖文本过滤或概念移除的策略,只能从文图生成模型的生成能力中移除少数几个概念。
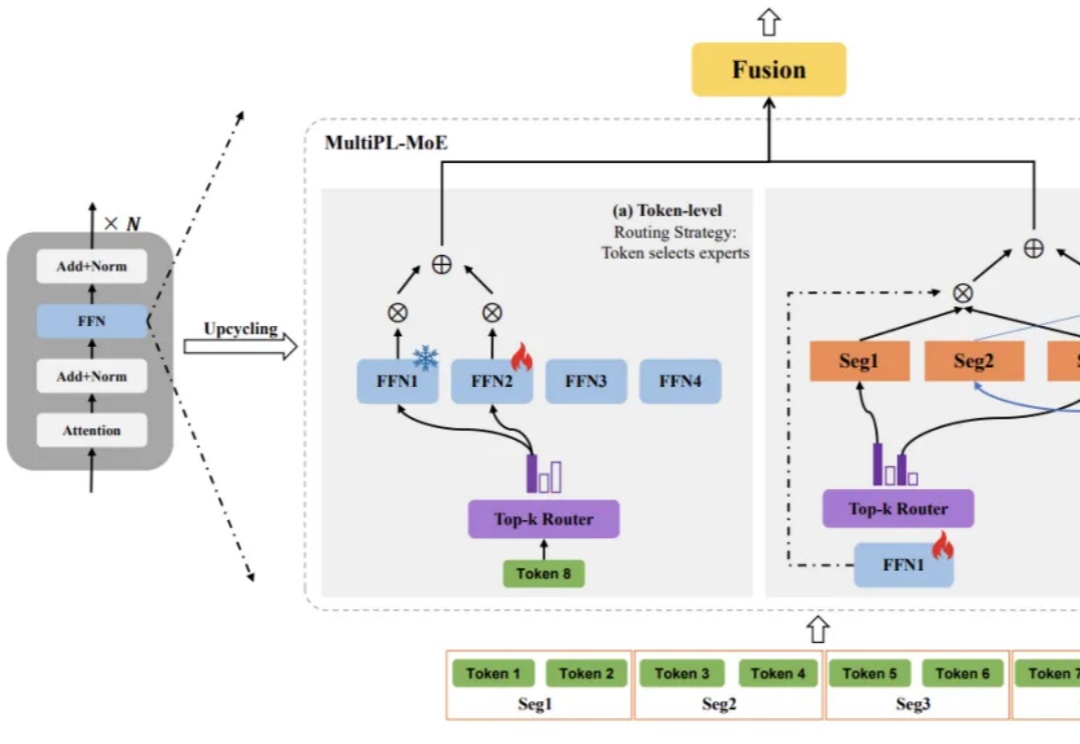
大语言模型(LLM)虽已展现出卓越的代码生成潜力,却依然面临着一道艰巨的挑战:如何在有限的计算资源约束下,同步提升对多种编程语言的理解与生成能力,同时不损害其在主流语言上的性能?

杨红霞要走一条和阿里、字节截然不同的模型训练之路。

读者,您好!今天想跟您聊一个硬核又极具启发性的项目——HGM(Huxley-Gödel Machine)。我刚刚一起花了几个小时,从环境配置的坑,一路“打怪升级”到让它最终跑完,相信您可能已经从别的公众号上看到了这篇文章。
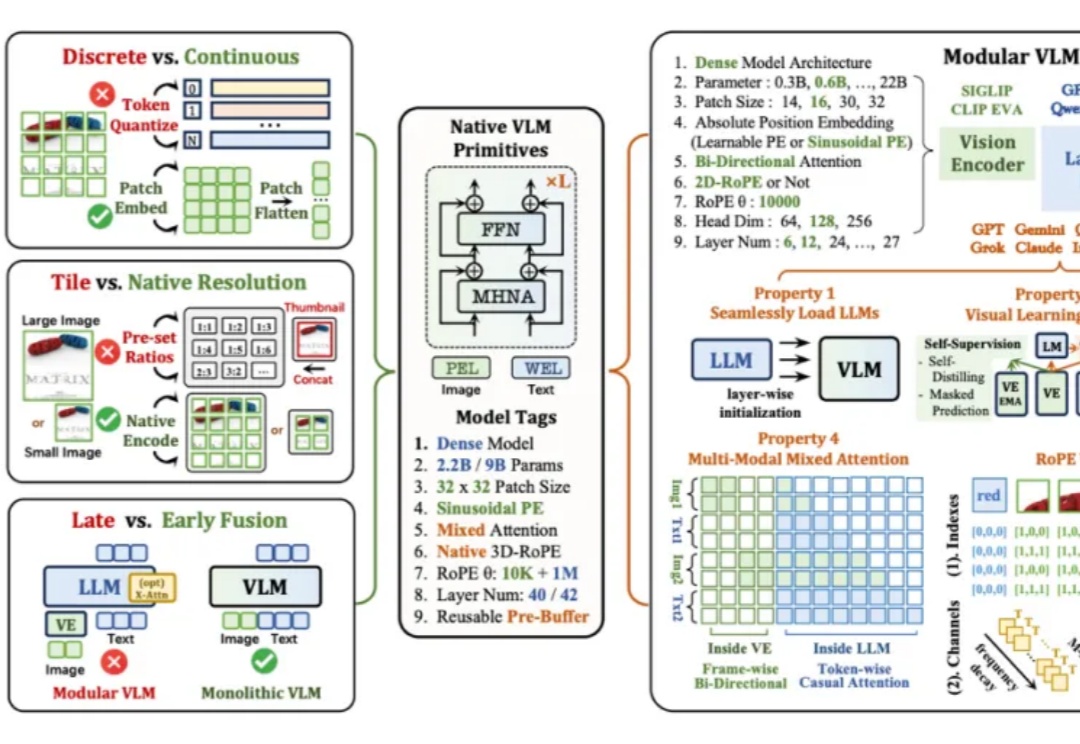
当下主流的视觉语言模型(Vision-Language Models, VLM),通常都采用这样一种设计思路:将预训练的视觉编码器与大语言模型通过投影层拼接起来。这种模块化架构成就了当前 VLM 的辉煌,但也带来了一系列新的问题——多阶段训练复杂、组件间语义对齐成本高,不同模块的扩展规律难以协调。
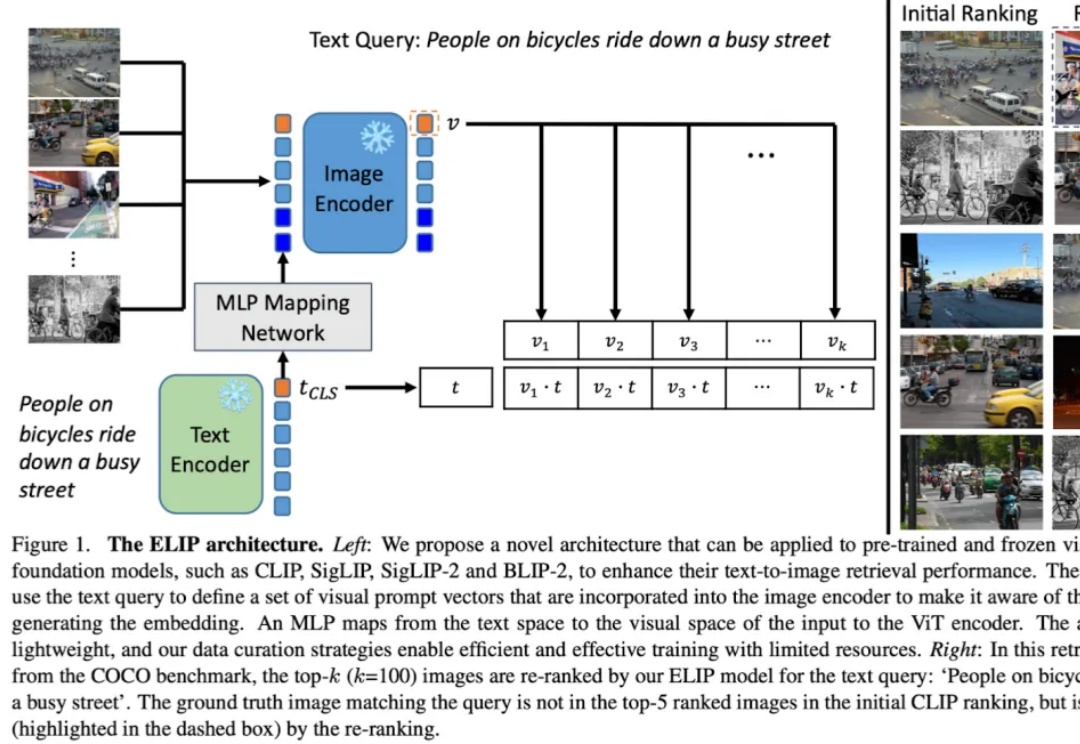
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。
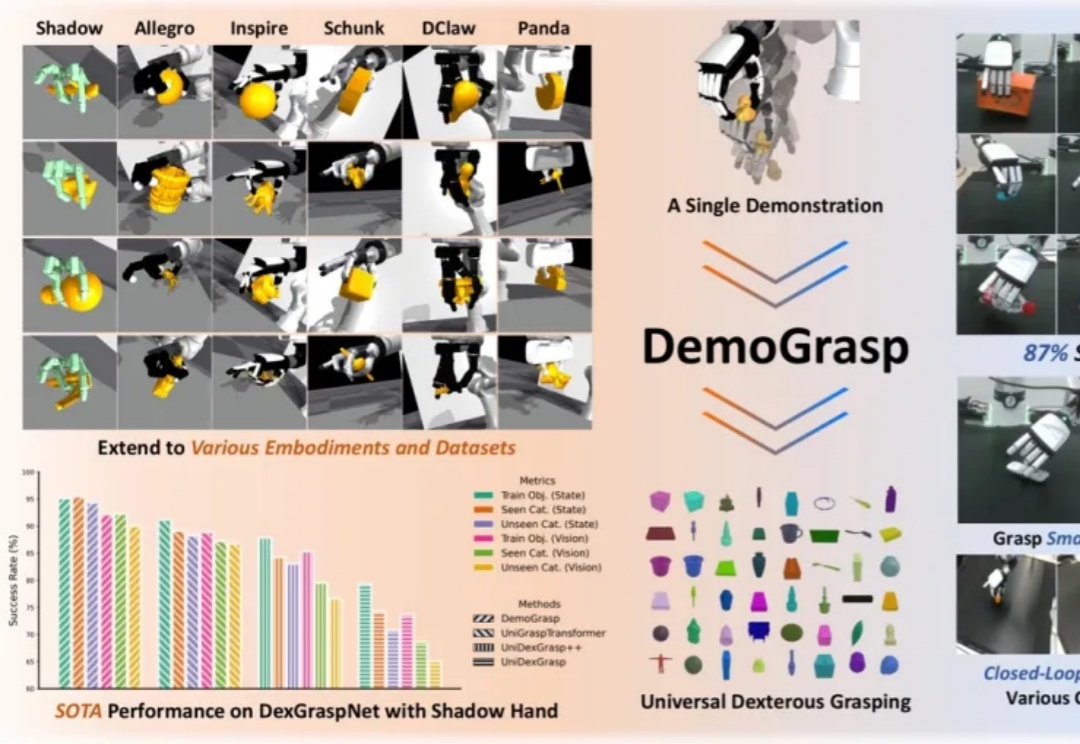
在灵巧手通用抓取的研究中,由于动作空间维度高、任务具有长程探索特征且涉及多样化物体,传统强化学习(RL)面临探索效率低、奖励函数及训练过程设计复杂等挑战。
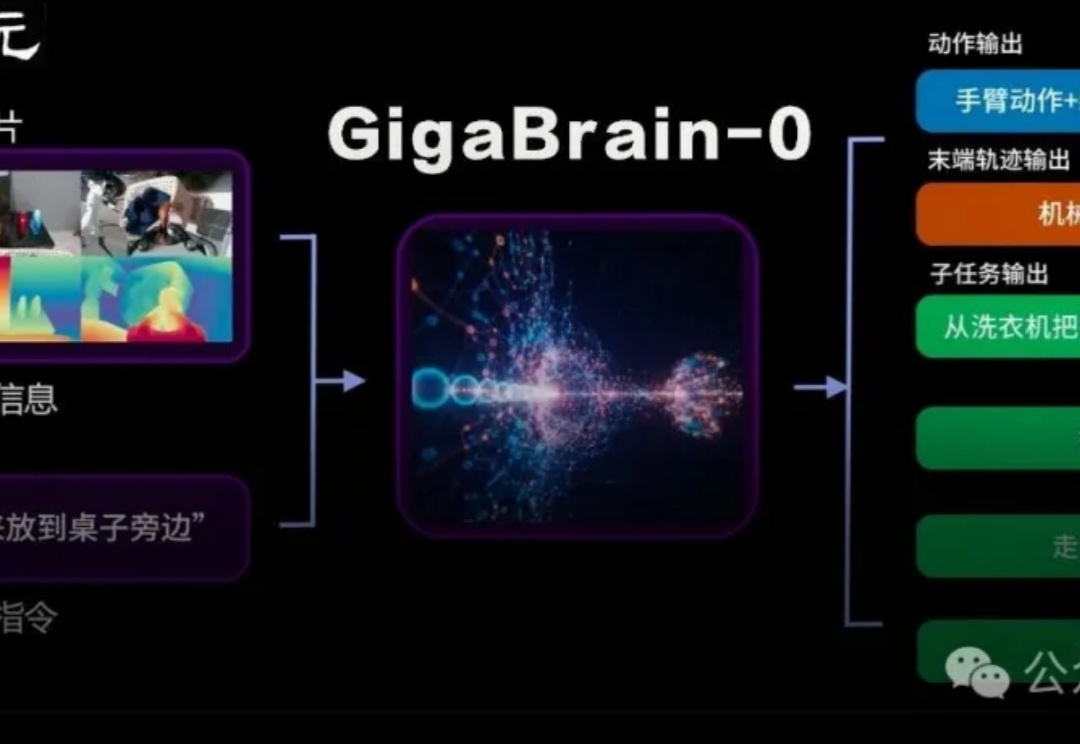
国内首个利用世界模型生成数据实现真机泛化的端到端VLA具身基础模型GigaBrain-0重磅发布。
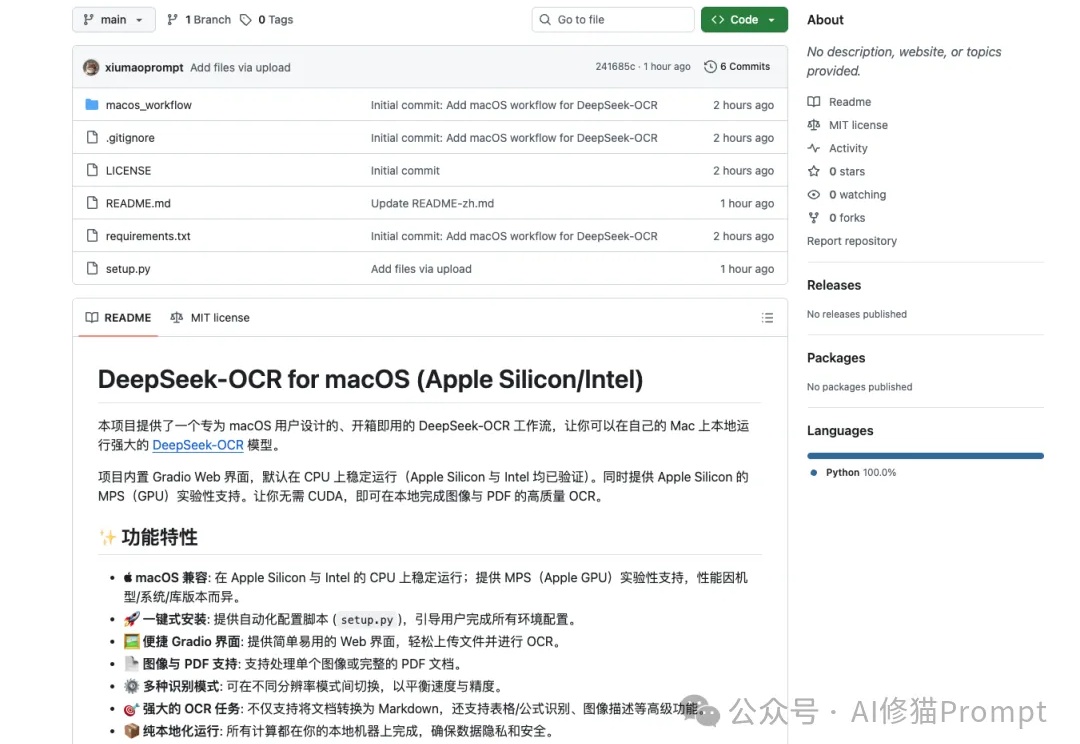
DeepSeek-OCR这段时间非常火,但官方开源的文件是“按 NVIDIA/CUDA 习惯写的 Linux 版推理脚本+模型权重”,而不是“跨设备跨后端”的通吃实现,因此无法直接在苹果设备上运行,对于Mac用户来说,在许多新模型诞生的第一时间,往往只能望“模”兴叹。