
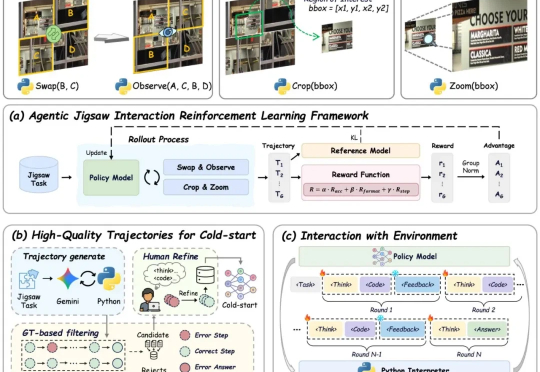
AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升
AGILE:视觉学习新范式!自监督+交互式强化学习助力VLMs感知与推理全面提升现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。
来自主题: AI技术研报
7433 点击 2025-10-21 15:30
现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。
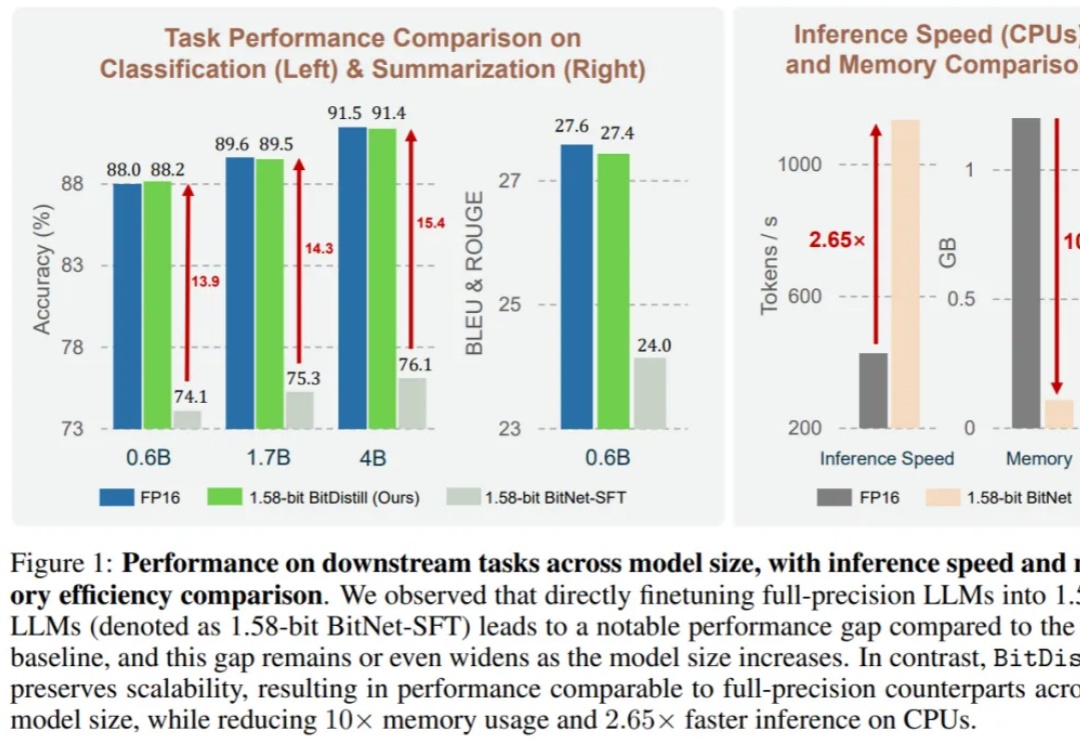
大语言模型(LLM)不仅在推动通用自然语言处理方面发挥了关键作用,更重要的是,它们已成为支撑多种下游应用如推荐、分类和检索的核心引擎。尽管 LLM 具有广泛的适用性,但在下游任务中高效部署仍面临重大挑战。

不再依赖人工设计,让模型真正学会管理记忆。

近日刚好得了空闲,在研读 Anthropic 官方技术博客和一些相关论文,主题是「Agent 与 Context 工程」。2025 年 6 月以来,原名为「Prompt Engineering」的提示词工程,在 AI Agent 概念日趋火热的应用潮中,

在视频生成与理解的赛道上,常常见到分头发力的模型:有的专注做视频生成,有的专注做视频理解(如问答、分类、检索等)。而最近,一个开源项目 UniVid,提出了一个「融合」方向:把理解 + 生成融为一体 —— 他们希望用一个统一的模型,兼顾「看懂视频」+「生成视频」的能力。

复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。

AI 会写字吗?在写字机器人衍生换代的今天,你或许并不觉得 AI 写字有多么困难。

在某种程度上,GPT-5可以被视作是o3.1。 该观点出自OpenAI研究副总裁Jerry Tworek的首次播客采访,而Jerry其人,正是o1模型的主导者之一。
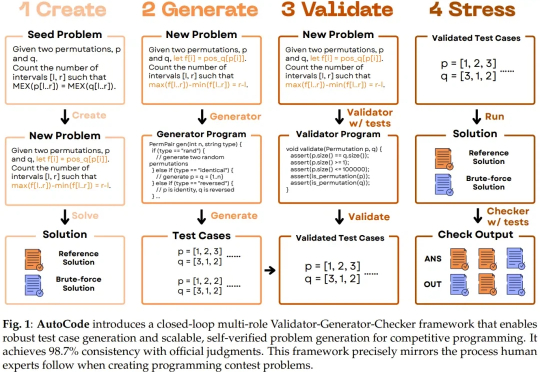
随着大型语言模型(LLM)朝着通用能力迈进,并以通用人工智能(AGI)为最终目标,测试其生成问题的能力也正变得越来越重要。尤其是在将 LLM 应用于高级编程任务时,因为未来 LLM 编程能力的发展和经济整合将需要大量的验证工作。
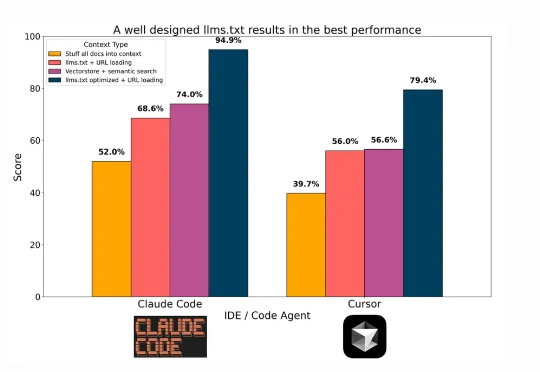
在技术飞速更新迭代的今天,每隔一段时间就会出现「XX 已死」的论调。「搜索已死」、「Prompt 已死」的余音未散,如今矛头又直指 RAG。