
李飞飞造了ImageNet,现在她又带人超越了它
李飞飞造了ImageNet,现在她又带人超越了它就在前两天,斯坦福大学等机构发布了一个名为 GPIC(Giant Permissive Image Corpus,巨型开放图像语料库)的数据集。
来自主题: AI技术研报
9206 点击 2026-05-30 15:57
 搜索
搜索
就在前两天,斯坦福大学等机构发布了一个名为 GPIC(Giant Permissive Image Corpus,巨型开放图像语料库)的数据集。

心理健康问题影响着全球数亿人的生活,然而患者往往面临着双重负担:不仅要承受疾病本身的痛苦,还要忍受来自社会的偏见和歧视。世界卫生组织数据显示,全球有相当比例的心理健康患者因为恐惧社会歧视而延迟或拒绝治疗。
据工业和信息化部网站25日消息,工业和信息化部、国务院国有资产监督管理委员会、中华全国工商业联合会日前印发《制造业企业数字化转型实施指南》。

说好的AI给人类打工呢? 为了拿到新数据、训练AI大模型,字节等互联网大厂正在亲自下场,以单次300元不等的价格招募“AI录音员”,定制语料库。

在以英语为主的语料库上训练的多语言LLM,是否使用英语作为内部语言?对此,来自EPFL的研究人员针对Llama 2家族进行了一系列实验。

无论投资界还是产业界,已经没有人质疑AI的兴起是大事件。但无论是谁,奥特曼或者霍夫曼,都无法确定AI领域的投资最终如何获利。

语言建模领域的最新进展在于在极大规模的网络文本语料库上预训练高参数化的神经网络。在实践中,使用这样的模型进行训练和推断可能会成本高昂,这促使人们使用较小的替代模型。然而,已经观察到较小的模型可能会出现饱和现象,表现为在训练的某个高级阶段性能下降并趋于稳定。

大模型语料是指用于训练和评估大模型的一系列文本、语音或其他模态的数据。
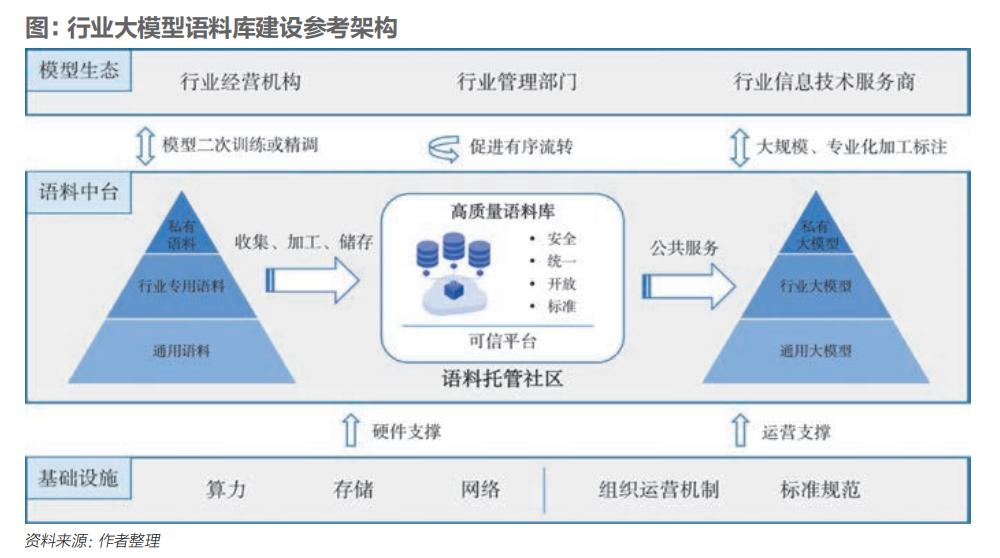
大模型语料是指用于训练和评估大模型的一系列文本、语音或其他模态的数据。语料规模和质量对大模型性能以及应用的深度、广度有着至关重要的影响。

如果让你在互联网上给大模型选一本中文教材,你会去哪里取材?是知乎,是豆瓣,还是微博?一个研究团队为了构建高质量的中文指令微调数据集,对这些社交媒体进行了测试,想找到训练大模型最好的中文预料,结果答案保证让你大跌眼镜——