Lumina-DiMOO:多模态扩散语言模型重塑图像生成与理解
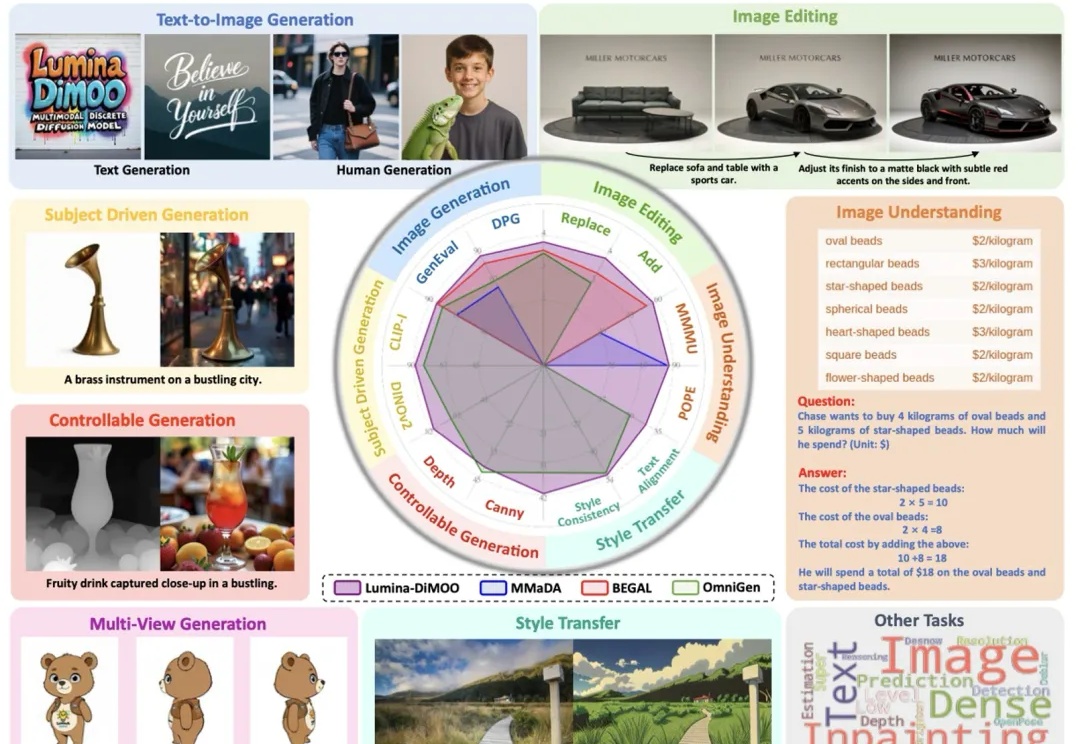
Lumina-DiMOO:多模态扩散语言模型重塑图像生成与理解上海人工智能实验室推出了一款革新的多模态生成理解一体化的扩散语言模型 ——Lumina-DiMOO。基于离散扩散建模(Discrete Diffusion Modeling),Lumina-DiMOO 打破了多模态任务之间的壁垒,在同一离散扩散框架下,完成从 文本→图像、图像→图像、图像→文本的全栈能力闭环。
来自主题: AI技术研报
9422 点击 2025-11-17 14:33