北大团队让AI学会考古!全球首个古希腊陶罐3D视觉问答数据集发布,还配了专用模型
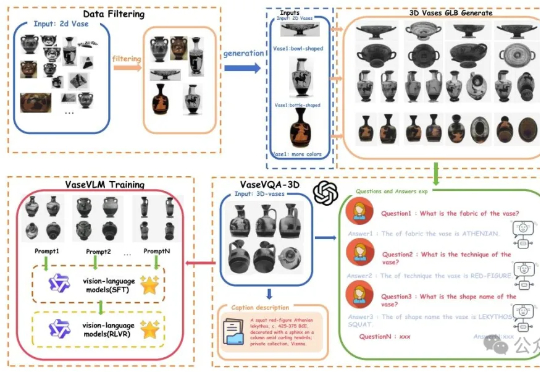
北大团队让AI学会考古!全球首个古希腊陶罐3D视觉问答数据集发布,还配了专用模型现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。
来自主题: AI技术研报
9056 点击 2025-11-07 14:49
 搜索
搜索
现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。

大型语言模型(LLMs)正迅速成为从金融到交通等各个专业领域不可或缺的辅助决策工具。但目前LLM的“通用智能”在面对高度专业化、高风险的任务时,往往显得力不从心。

大模型一个token一个token生成,效率太低怎么办?
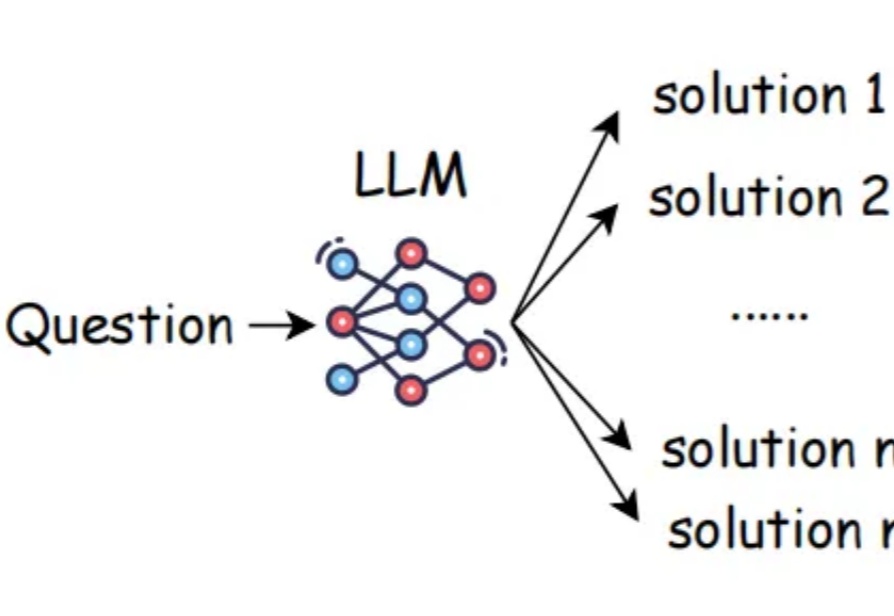
在大语言模型(LLM)席卷各类复杂任务的今天,“测试时扩展”(Test-Time Scaling,TTS)已成为提升模型推理能力的核心思路 —— 简单来说,就是在模型 “答题” 时分配更多的计算资源来让它表现更好。严格来说,Test-Time Scaling 分成两类:
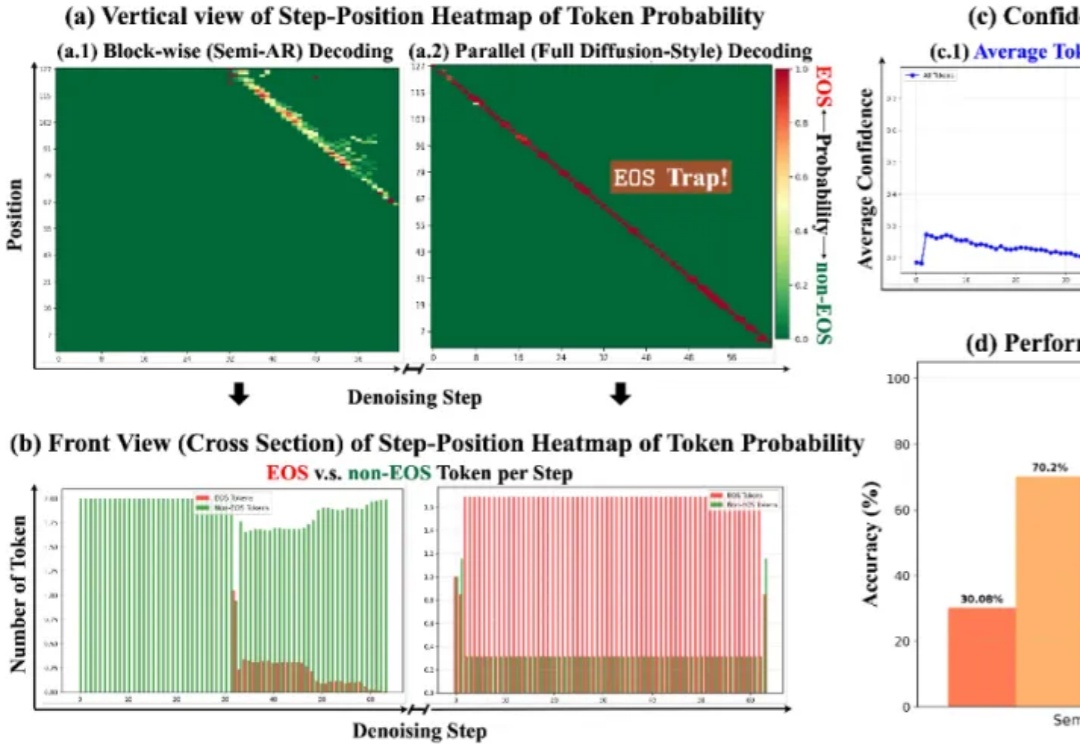
扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。
大语言模型(LLM)的「炼丹师」们,或许都曾面临一个共同的困扰:为不同任务、不同模型手动调整解码超参数(如 temperature 和 top-p)。这个过程不仅耗时耗力,而且一旦模型或任务发生变化,历史经验便瞬间失效,一切又得从头再来。
现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。

11 月 2 日,英伟达首次把 H100 GPU 送入了太空。作为目前 AI 领域的主力训练芯片,H100 配备 80GB 内存,其性能是此前任何一台进入太空的计算机的上百倍。在轨道上,它将测试一系列人工智能处理应用,包括分析地球观测图像和运行谷歌的大语言模型(LLM)。

Transformer 语言模型具有单射性,隐藏状态可无损重构输入信息。

当用户向大语言模型提出一个简单问题,比如「单词 HiPPO 里有几个字母 P?」,它却正襟危坐,开始生成一段冗长的推理链: