全新MoE架构!阿里开源Qwen3-Next,训练成本直降9成
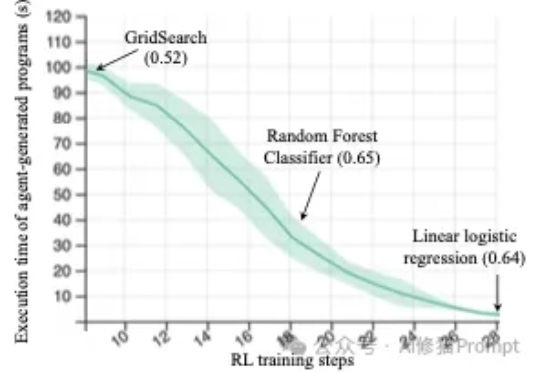
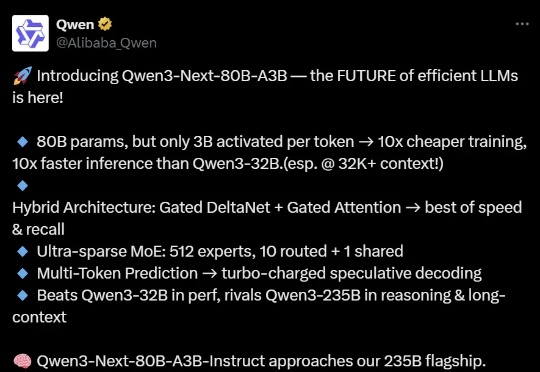
全新MoE架构!阿里开源Qwen3-Next,训练成本直降9成训练、推理性价比创新高。 大语言模型(LLM),正在进入 Next Level。 周五凌晨,阿里通义团队正式发布、开源了下一代基础模型架构 Qwen3-Next。总参数 80B 的模型仅激活 3B ,性能就可媲美千问 3 旗舰版 235B 模型,也超越了 Gemini-2.5-Flash-Thinking,实现了模型计算效率的重大突破。
来自主题: AI资讯
12234 点击 2025-09-12 10:10