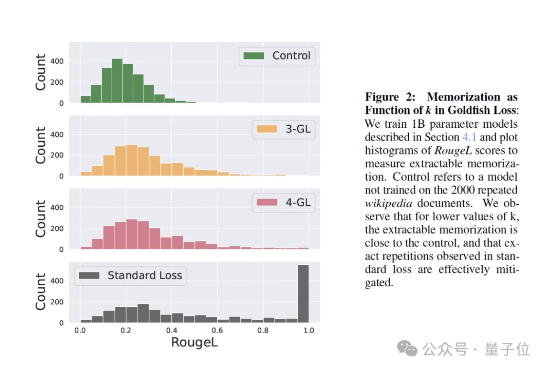
大模型“记性差一点”反而更聪明!金鱼损失随机剔除token,让AI不再死记硬背
大模型“记性差一点”反而更聪明!金鱼损失随机剔除token,让AI不再死记硬背训练大模型时,有时让它“记性差一点”,反而更聪明! 大语言模型如果不加约束,很容易把训练数据原封不动地复刻出来。为解决这个问题,来自马里兰大学、图宾根大学和马普所的研究团队提出了一个新方法——金鱼损失(Goldfish Loss)。
来自主题: AI资讯
7523 点击 2025-09-04 11:33
 搜索
搜索
训练大模型时,有时让它“记性差一点”,反而更聪明! 大语言模型如果不加约束,很容易把训练数据原封不动地复刻出来。为解决这个问题,来自马里兰大学、图宾根大学和马普所的研究团队提出了一个新方法——金鱼损失(Goldfish Loss)。

在这场以大型语言模型(LLM)为核心的 AI 浪潮中,苹果似乎一直保持着低调,很少出现在技术报道的前沿。尽管如此,时不时地,该公司也能拿出一些非常亮眼的研究成果,比如能在 iPhone 上直接运行的高效视觉语言模型 FastVLM。
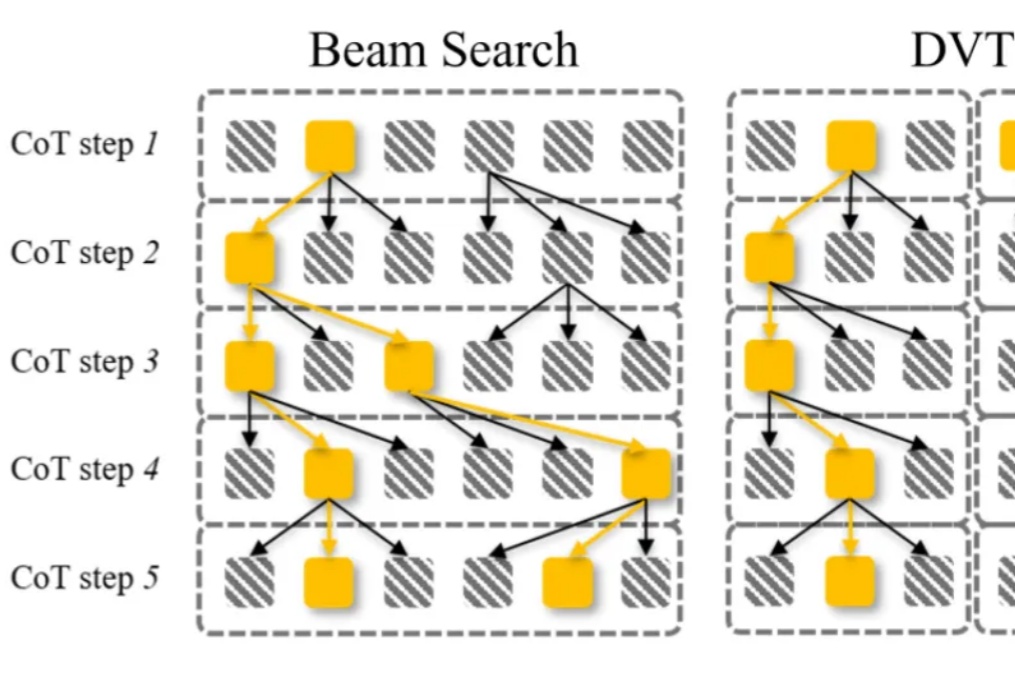
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。
随着DeepSeek R1、Kimi K2和DeepSeek V3.1混合专家(MoE)模型的相继发布,它们已成为智能前沿领域大语言模型(LLM)的领先架构。由于其庞大的规模(1万亿参数及以上)和稀疏计算模式(每个token仅激活部分参数而非整个模型),MoE式LLM对推理工作负载提出了重大挑战,显著改变了底层的推理经济学。

如今,人工智能已经成为科技发展的主流,尤其是 ChatGPT 问世以来,大语言模型(LLM)正在深刻影响社会、企业和个人的方方面面。
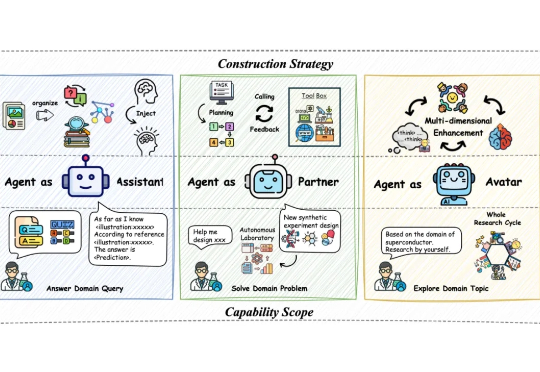
当前基于大语言模型(LLM)的智能体构建通过推动自主科学研究推动 AI4S 迅猛发展,催生一系列科研智能体的构建与应用。然而人工智能与自然科学研究之间认知论与方法论的偏差,对科研智能体系统的设计、训练以及验证产生着较大阻碍。
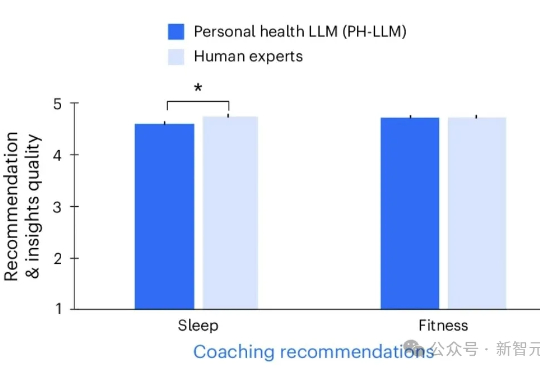
谷歌DeepMind最新Nature王炸,直接把Gemini版大模型PH-LLM调教成了「AI健康私教」,把可穿戴冷冰冰的数据,直接变成睡眠健身建议,结果准确率暴打人类医生。

最近3D内容生成模型好生热闹,像谷歌Genie 3、World Labs、混元、昆仑争相发布并开测世界模型。
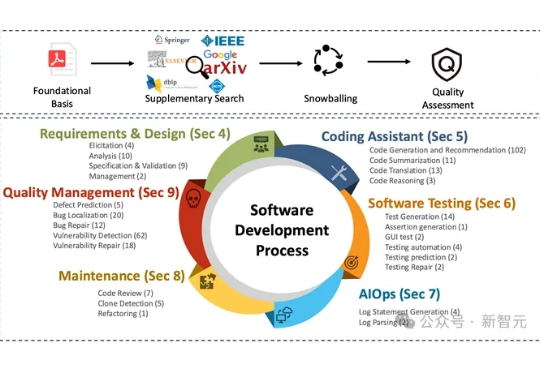
大语言模型正加速重塑软件工程领域的各个环节,从需求分析到代码生成,再到自动化测试,几乎无所不能,但衡量这些模型到底「好不好用」、「好在哪里」、「还有哪些短板」,一直缺乏系统、权威的评估工具。
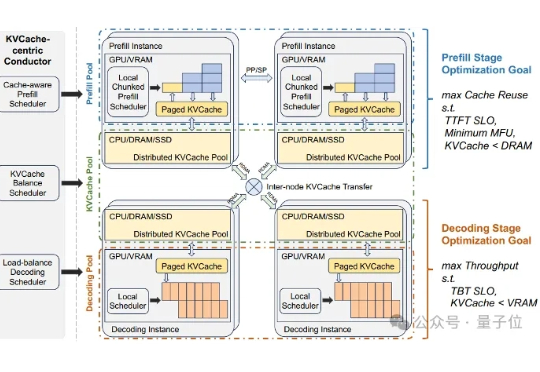
当大语言模型(LLM)走向千行百业,推理效率与显存成本的矛盾日益尖锐。