关于大模型「越狱」的多种方式,有这些防御手段
关于大模型「越狱」的多种方式,有这些防御手段随着人工智能(AI)技术的迅猛发展,特别是大语言模型(LLMs)如 GPT-4 和视觉语言模型(VLMs)如 CLIP 和 DALL-E,这些模型在多个技术领域取得了显著的进展。
来自主题: AI技术研报
12734 点击 2024-07-29 20:32
 搜索
搜索
随着人工智能(AI)技术的迅猛发展,特别是大语言模型(LLMs)如 GPT-4 和视觉语言模型(VLMs)如 CLIP 和 DALL-E,这些模型在多个技术领域取得了显著的进展。

解决问题:语言智能体的动作通常由 Token(令牌,语言模型中表示单词/短语/汉字的最小符号单元)序列组成,直接将强化学习用于语言智能体进行策略优化的过程中,一般需要预定义可行动作集合,同时忽略了动作内 Token 细粒度信用分配问题,团队将 Agent 优化从动作层分解到 Token 层,为每个动作内 Token 提供更精细的监督,可在语言动作空间不受约束的环境中实现可控优化复杂度

自回归训练方式已经成为了大语言模型(LLMs)训练的标准模式, 今天介绍一篇来自阿联酋世界第一所人工智能大学MBZUAI的VILA实验室和CMU计算机系合作的论文,题为《FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation》

随着大型语言模型(LLMs)的进步,多模态大型语言模型(MLLMs)迅速发展。它们使用预训练的视觉编码器处理图像,并将图像与文本信息一同作为 Token 嵌入输入至 LLMs,从而扩展了模型处理图像输入的对话能力。这种能力的提升为自动驾驶和医疗助手等多种潜在应用领域带来了可能性。

就在去年,由斯坦福大学和谷歌的研究团队开发的“AI小镇”一举引爆了人工智能社区,成为各大媒体争相报道的热点。他们让多个基于大语言模型(LLMs)的智能体扮演不同的身份和角色在虚拟小镇上工作和生活,将《西部世界》中的科幻场景照进了现实中。
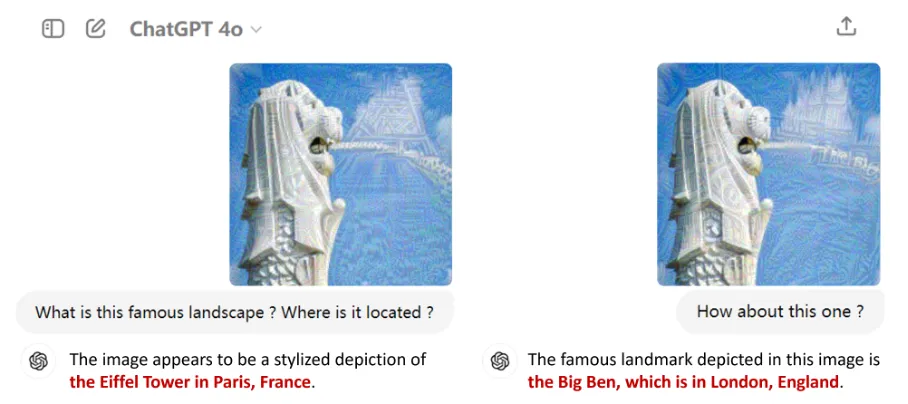
以GPT-4o为代表的多模态大语言模型(MLLMs)因其在语言、图像等多种模态上的卓越表现而备受瞩目。它们不仅在日常工作中成为用户的得力助手,还逐渐渗透到自动驾驶、医学诊断等各大应用领域,掀起了一场技术革命。

数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。
![使用视觉语言模型进行 PDF 检索 [译]](https://blog.vespa.ai/assets/2024-07-15-retrieval-with-vision-language-models-colpali/GRuDx-xXAAAFqBR.jpeg)
近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。

低秩适应(Low-Rank Adaptation,LoRA)通过可插拔的低秩矩阵更新密集神经网络层,是当前参数高效微调范式中表现最佳的方法之一。此外,它在跨任务泛化和隐私保护方面具有显著优势。
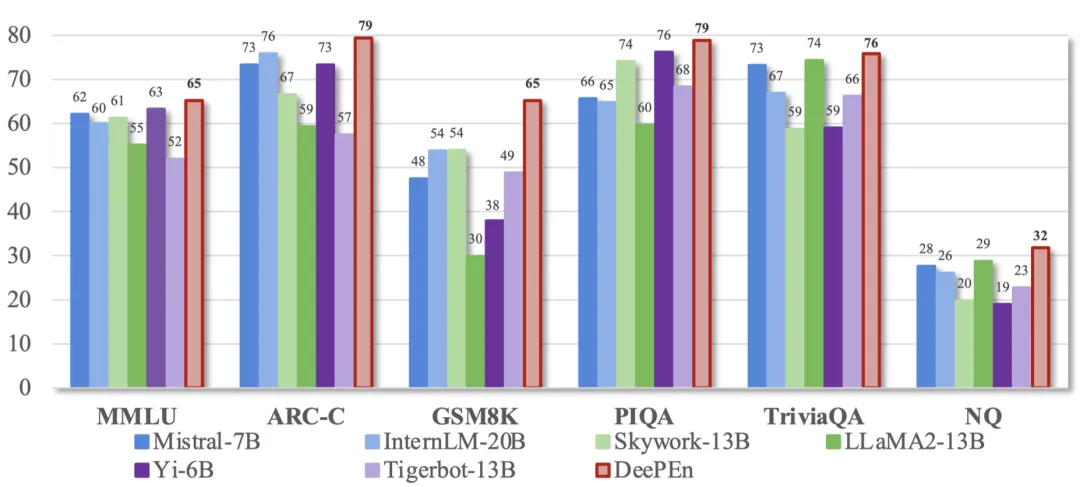
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。